
Mit verbundenen Tabellenblättern können Sie Petabytes an Daten direkt in Google Sheets analysieren. Sie können Ihre Tabellen mit einem BigQuery-Data Warehouse oder Looker verbinden und die Analyse mit vertrauten Google Sheets-Tools wie Pivot-Tabellen, Diagrammen und Formeln durchführen.
BigQuery-Datenquelle verwalten
In diesem Abschnitt wird anhand des öffentlichen Datasets von BigQueryShakespeare gezeigt, wie Sie Verbundene Tabellenblätter verwenden. Das Dataset enthält die folgenden Informationen:
| Feld | Typ | Beschreibung |
|---|---|---|
| Wort | STRING |
Ein einzelnes eindeutiges Wort, das aus einem Korpus extrahiert wurde (Leerzeichen als Trennzeichen). |
| word_count | INTEGER |
Die Anzahl der Vorkommen dieses Wortes in diesem Korpus. |
| Korpus | STRING |
Das Werk, aus dem dieses Wort extrahiert wurde. |
| corpus_date | INTEGER |
Das Jahr, in dem dieser Korpus veröffentlicht wurde. |
Wenn Ihre Anwendung Daten aus BigQuery Connected Sheets anfordert, muss sie ein OAuth 2.0-Token mit dem Bereich bigquery.readonly angeben. Dies gilt zusätzlich zu den anderen Bereichen, die für eine reguläre Google Sheets API-Anfrage erforderlich sind. Weitere Informationen finden Sie unter Google Sheets API-Bereiche auswählen.
Eine Datenquelle gibt einen externen Speicherort an, an dem Daten gefunden werden. Die Datenquelle wird dann mit der Tabelle verbunden.
BigQuery-Datenquelle hinzufügen
Wenn Sie eine Datenquelle hinzufügen möchten, geben Sie ein AddDataSourceRequest mit der Methode spreadsheets.batchUpdate an. Im Anfragetext sollte ein dataSource-Feld vom Typ DataSource-Objekt angegeben werden.
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
Ersetzen Sie PROJECT_ID durch eine gültige Google Cloud-Projekt-ID.
Nachdem eine Datenquelle erstellt wurde, wird ein zugehöriges DATA_SOURCE-Tabellenblatt erstellt, das eine Vorschau von bis zu 500 Zeilen enthält. Die Vorschau ist nicht sofort verfügbar. Die Ausführung wird asynchron ausgelöst, um die BigQuery-Daten zu importieren.
Das AddDataSourceResponse enthält die folgenden Felder:
dataSource: Das erstellteDataSource-Objekt. DiedataSourceIdist eine eindeutige ID, die auf die Tabelle beschränkt ist. Es wird mit Daten gefüllt und referenziert, um jedesDataSource-Objekt aus der Datenquelle zu erstellen.dataExecutionStatus: Der Status einer Ausführung, bei der BigQuery-Daten in das Vorschau-Tabellenblatt importiert werden. Weitere Informationen finden Sie im Abschnitt Status der Datenausführung.
BigQuery-Datenquelle aktualisieren oder löschen
Verwenden Sie die Methode spreadsheets.batchUpdate und geben Sie eine UpdateDataSourceRequest- oder DeleteDataSourceRequest-Anfrage an.
BigQuery-Datenquellenobjekte verwalten
Sobald eine Datenquelle der Tabelle hinzugefügt wurde, kann daraus ein Datenquellenobjekt erstellt werden. Ein Datenquellenobjekt ist ein reguläres Google Sheets-Tool wie Pivot-Tabellen, Diagramme und Formeln, das in verbundene Tabellenblätter integriert ist, um Ihre Datenanalyse zu unterstützen.
Es gibt vier Arten von Objekten:
DataSourceTabelleDataSourcepivotTable- Diagramm zu
DataSource DataSource-Formel
BigQuery-Datenquellentabelle hinzufügen
Das Tabellenobjekt, das im Sheets-Editor als „Auszug“ bezeichnet wird, importiert einen statischen Datendump aus der Datenquelle in Sheets. Ähnlich wie bei einer Pivot-Tabelle wird die Tabelle angegeben und in der Zelle oben links verankert.
Das folgende Codebeispiel zeigt, wie Sie mit der Methode spreadsheets.batchUpdate und einem UpdateCellsRequest eine Datenquellentabelle mit bis zu 1.000 Zeilen und zwei Spalten (word und word_count) erstellen.
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
Ersetzen Sie DATA_SOURCE_ID durch eine eindeutige ID auf Tabellenebene, die die Datenquelle identifiziert.
Nachdem eine Datenquellentabelle erstellt wurde, sind die Daten nicht sofort verfügbar. Im Google Sheets-Editor wird sie als Vorschau angezeigt. Sie müssen die Datenquellentabelle aktualisieren, um die BigQuery-Daten abzurufen. Sie können ein RefreshDataSourceRequest innerhalb desselben batchUpdate angeben. Alle Datenquellenobjekte funktionieren ähnlich.
Weitere Informationen finden Sie unter Datenquellenobjekt aktualisieren.
Nachdem die Aktualisierung abgeschlossen und die BigQuery-Daten abgerufen wurden, wird die Tabelle der Datenquelle wie unten dargestellt gefüllt:
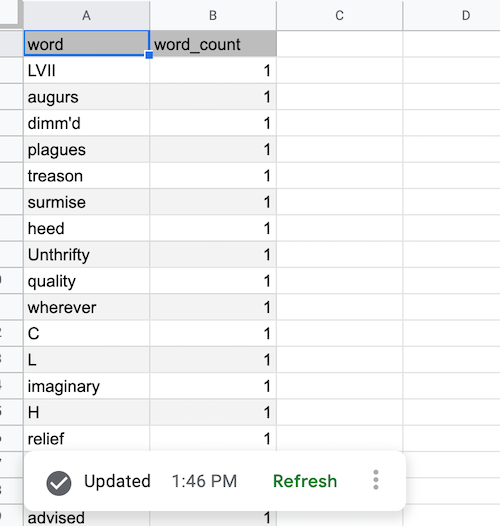
BigQuery-Datenquelle für Pivot-Tabelle hinzufügen
Im Gegensatz zu einer herkömmlichen Pivot-Tabelle basiert eine Datenquellen-Pivot-Tabelle auf einer Datenquelle und verweist anhand des Spaltennamens auf die Daten. Das folgende Codebeispiel zeigt, wie Sie mit der Methode spreadsheets.batchUpdate und einem UpdateCellsRequest eine Pivot-Tabelle erstellen, in der die Gesamtzahl der Wörter nach Korpus angezeigt wird.
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
Ersetzen Sie DATA_SOURCE_ID durch eine eindeutige ID auf Tabellenebene, die die Datenquelle identifiziert.
Nachdem die BigQuery-Daten abgerufen wurden, wird die Pivot-Tabelle der Datenquelle so ausgefüllt:
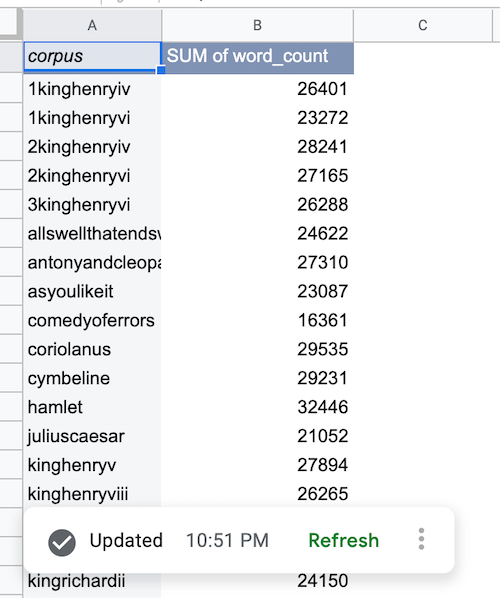
Diagramm für eine BigQuery-Datenquelle hinzufügen
Das folgende Codebeispiel zeigt, wie Sie die Methode spreadsheets.batchUpdate und ein AddChartRequest verwenden, um ein Datenquellen-Diagramm mit einem chartType vom Typ COLUMN zu erstellen, das die Gesamtzahl der Wörter nach Korpus zeigt.
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
Ersetzen Sie DATA_SOURCE_ID durch eine eindeutige ID auf Tabellenebene, die die Datenquelle identifiziert.
Nachdem die BigQuery-Daten abgerufen wurden, wird das Diagramm der Datenquelle so gerendert:
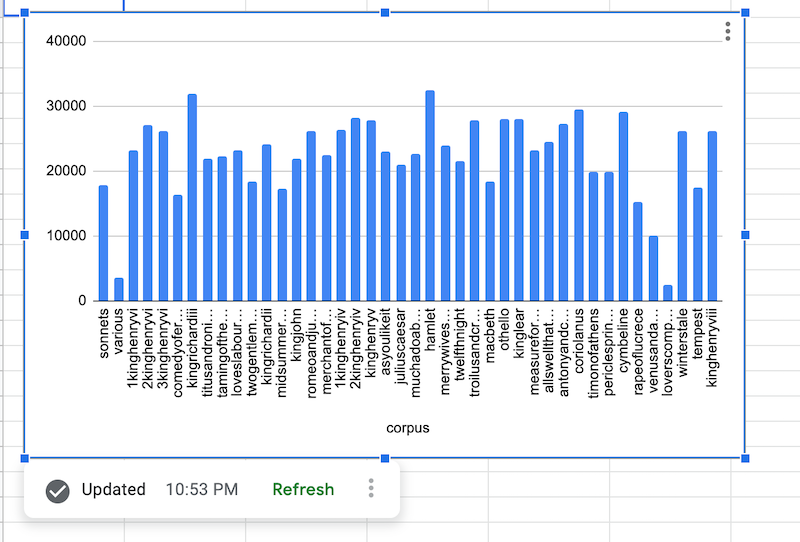
Formel für BigQuery-Datenquelle hinzufügen
Im folgenden Codebeispiel wird gezeigt, wie Sie mit der Methode spreadsheets.batchUpdate und einem UpdateCellsRequest eine Datenquellenformel erstellen, um die durchschnittliche Anzahl von Wörtern zu berechnen.
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
Nachdem die BigQuery-Daten abgerufen wurden, wird die Datenquellenformel wie unten dargestellt ausgefüllt:
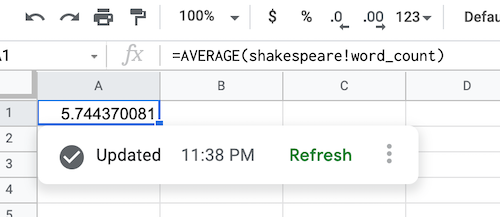
BigQuery-Datenquellenobjekt aktualisieren
Sie können ein Datenquellenobjekt aktualisieren, um die neuesten Daten aus BigQuery abzurufen. Dabei werden die aktuellen Datenquellenspezifikationen und Objektkonfigurationen berücksichtigt. Sie können die Methode spreadsheets.batchUpdate verwenden, um RefreshDataSourceRequest aufzurufen.
Geben Sie dann mit dem Objekt DataSourceObjectReferences mindestens eine Objektreferenz an, die aktualisiert werden soll.
Sie können Datenquellenobjekte sowohl erstellen als auch aktualisieren.batchUpdate
Looker-Datenquelle verwalten
In dieser Anleitung wird beschrieben, wie Sie eine Looker-Datenquelle hinzufügen, aktualisieren oder löschen, eine Pivot-Tabelle dafür erstellen und sie aktualisieren.
Für Ihre Anwendung, die Looker Connected Sheets-Daten anfordert, wird Ihre vorhandene Google-Konto-Verknüpfung mit Looker wiederverwendet.
Looker-Datenquelle hinzufügen
Wenn Sie eine Datenquelle hinzufügen möchten, geben Sie ein AddDataSourceRequest mit der Methode spreadsheets.batchUpdate an. Im Anfragetext sollte ein dataSource-Feld vom Typ DataSource-Objekt angegeben werden.
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
Ersetzen Sie INSTANCE_URI, MODEL und EXPLORE durch einen gültigen Looker-Instanz-URI, einen Modellnamen und einen Explore-Namen.
Nachdem eine Datenquelle erstellt wurde, wird ein zugehöriges DATA_SOURCE-Arbeitsblatt erstellt, um eine Vorschau der Struktur des ausgewählten Explores zu liefern, einschließlich Ansichten, Dimensionen, Messwerten und allen Feldbeschreibungen.
Die AddDataSourceResponse enthält die folgenden Felder:
dataSource: Das erstellteDataSource-Objekt. DiedataSourceIdist eine eindeutige ID auf Tabellenebene. Sie wird ausgefüllt und referenziert, um jedesDataSource-Objekt aus der Datenquelle zu erstellen.dataExecutionStatus: Der Status einer Ausführung, bei der BigQuery-Daten in das Vorschau-Tabellenblatt importiert werden. Weitere Informationen finden Sie im Abschnitt Status der Datenausführung.
Looker-Datenquelle aktualisieren oder löschen
Verwenden Sie die Methode spreadsheets.batchUpdate und geben Sie eine UpdateDataSourceRequest- oder DeleteDataSourceRequest-Anfrage an.
Looker-Datenquellenobjekte verwalten
Sobald eine Datenquelle der Tabelle hinzugefügt wurde, kann daraus ein Datenquellenobjekt erstellt werden. Für Looker-Datenquellen können Sie nur ein DataSource-Objekt daraus erstellen.
Es ist nicht möglich, DataSource-Formeln, ‑Extrakte und ‑Diagramme aus Looker-Datenquellen zu erstellen.
Looker-Datenquellenobjekt aktualisieren
Sie können ein Datenquellenobjekt aktualisieren, um die neuesten Daten aus Looker abzurufen, die auf den aktuellen Datenquellenspezifikationen und Objektkonfigurationen basieren. Sie können die Methode spreadsheets.batchUpdate verwenden, um RefreshDataSourceRequest aufzurufen.
Geben Sie dann mit dem Objekt DataSourceObjectReferences mindestens eine Objektreferenz an, die aktualisiert werden soll.
Sie können Datenquellenobjekte sowohl erstellen als auch aktualisieren.batchUpdate
Status der Datenausführung
Wenn Sie Datenquellen erstellen oder Datenquellenobjekte aktualisieren, wird eine Hintergrundausführung erstellt, um die Daten aus BigQuery oder Looker abzurufen und eine Antwort mit dem DataExecutionStatus zurückzugeben.
Wenn die Ausführung erfolgreich gestartet wird, befindet sich DataExecutionState normalerweise im Status RUNNING.
Da der Prozess asynchron ist, sollte Ihre Anwendung ein Polling-Modell implementieren, um den Status der Datenquellenobjekte regelmäßig abzurufen. Verwenden Sie die Methode spreadsheets.get, bis der Status entweder SUCCEEDED oder FAILED zurückgibt.
Die Ausführung ist in den meisten Fällen schnell abgeschlossen, hängt aber von der Komplexität Ihrer Datenquelle ab. Die Ausführung dauert in der Regel nicht länger als 10 Minuten.
Weitere Informationen
- Google Sheets API-Bereiche auswählen
- Erste Schritte mit BigQuery-Daten in Google Sheets
- BigQuery-Dokumentation
- BigQuery: Connected Sheets verwenden
- Videoanleitung zu verbundenen Tabellenblättern
- Verbundene Tabellenblätter für Looker verwenden
- Looker-Einführung