
Connected Sheets позволяет анализировать петабайты данных прямо в Google Таблицах. Вы можете подключить свои таблицы к хранилищу данных BigQuery или Looker и выполнять анализ, используя привычные инструменты Таблиц, такие как сводные таблицы, диаграммы и формулы.
Управление источником данных BigQuery
В этом разделе для демонстрации работы с подключенными таблицами используется общедоступный набор данных BigQuery Shakespeare . Набор данных содержит следующую информацию:
| Поле | Тип | Описание |
|---|---|---|
| слово | STRING | Одно уникальное слово (где пробел является разделителем), извлеченное из корпуса. |
| количество_слов | INTEGER | Сколько раз данное слово встречается в данном корпусе. |
| корпус | STRING | Произведение, из которого было извлечено это слово. |
| corpus_date | INTEGER | Год публикации данного корпуса. |
Если ваше приложение запрашивает данные BigQuery Connected Sheets, оно должно предоставить токен OAuth 2.0, предоставляющий доступ к области bigquery.readonly , в дополнение к другим областям, необходимым для обычного запроса API Google Таблиц. Подробнее см. в разделе Выбор областей API Google Таблиц .
Источник данных определяет внешнее расположение данных. Затем этот источник данных подключается к электронной таблице.
Добавить источник данных BigQuery
Чтобы добавить источник данных, отправьте запрос AddDataSourceRequest с помощью метода spreadsheets.batchUpdate . В теле запроса должно быть указано поле dataSource типа объекта DataSource .
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
Замените PROJECT_ID действительным идентификатором проекта Google Cloud.
После создания источника данных создаётся связанная таблица DATA_SOURCE для предварительного просмотра до 500 строк. Предварительный просмотр доступен не сразу. Выполнение запускается асинхронно для импорта данных BigQuery.
AddDataSourceResponse содержит следующие поля:
dataSource: созданный объектDataSource.dataSourceId— это уникальный идентификатор, действующий в пределах электронной таблицы. Он заполняется и используется для создания каждого объектаDataSourceиз источника данных.dataExecutionStatus: статус выполнения импорта данных BigQuery в лист предварительного просмотра. Подробнее см. в разделе « Статус выполнения данных» .
Обновление или удаление источника данных BigQuery
Используйте метод spreadsheets.batchUpdate и укажите запрос UpdateDataSourceRequest или DeleteDataSourceRequest соответственно.
Управление объектами источника данных BigQuery
После добавления источника данных в электронную таблицу можно создать объект источника данных. Объект источника данных — это стандартный инструмент Таблиц, такой как сводные таблицы, диаграммы и формулы, интегрированный с Connected Sheets для более эффективного анализа данных.
Существует четыре типа объектов:
- Таблица
DataSource -
DataSourceсводная таблица - диаграмма
DataSource - Формула
DataSource
Добавить таблицу источника данных BigQuery
Объект таблицы, известный в редакторе Таблиц как «извлечение», импортирует статический дамп данных из источника в Таблицы. Подобно сводной таблице, таблица указывается и привязывается к верхней левой ячейке.
В следующем примере кода показано, как использовать метод spreadsheets.batchUpdate и UpdateCellsRequest для создания таблицы источника данных, содержащей до 1000 строк из двух столбцов ( word и word_count ).
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
Замените DATA_SOURCE_ID уникальным идентификатором в области электронной таблицы, который идентифицирует источник данных.
После создания таблицы источника данных данные доступны не сразу. В редакторе таблиц они отображаются в режиме предварительного просмотра. Чтобы получить данные BigQuery, необходимо обновить таблицу источника данных. Вы можете указать запрос RefreshDataSourceRequest в том же batchUpdate . Обратите внимание, что все объекты источника данных работают аналогично. Подробнее см. в разделе Обновление объекта источника данных .
После завершения обновления и извлечения данных BigQuery таблица источника данных заполняется, как показано ниже:
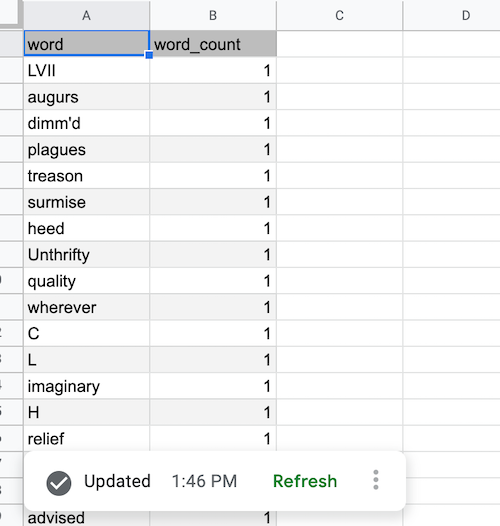
Добавить сводную таблицу источника данных BigQuery
В отличие от обычной сводной таблицы, сводная таблица с источником данных основана на источнике данных и ссылается на данные по имени столбца. В следующем примере кода показано, как использовать метод spreadsheets.batchUpdate и UpdateCellsRequest для создания сводной таблицы, отображающей общее количество слов в корпусе.
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
Замените DATA_SOURCE_ID уникальным идентификатором в области электронной таблицы, который идентифицирует источник данных.
После извлечения данных BigQuery сводная таблица источника данных заполняется, как показано ниже:
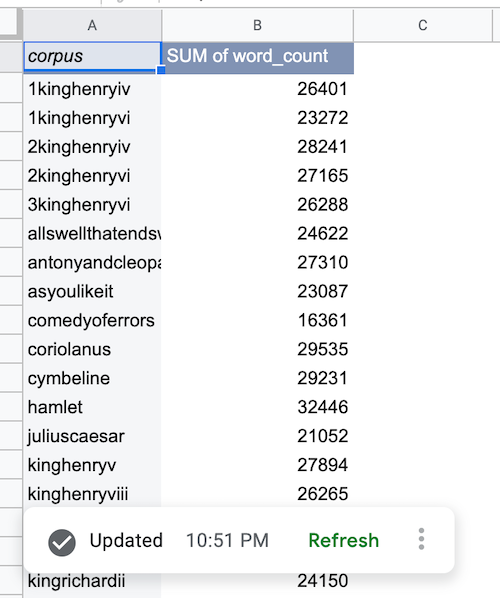
Добавить диаграмму источника данных BigQuery
В следующем примере кода показано, как использовать метод spreadsheets.batchUpdate и AddChartRequest для создания диаграммы источника данных с chartType COLUMN, отображающей общее количество слов по корпусу.
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
Замените DATA_SOURCE_ID уникальным идентификатором в области электронной таблицы, который идентифицирует источник данных.
После извлечения данных BigQuery диаграмма источника данных отображается следующим образом:
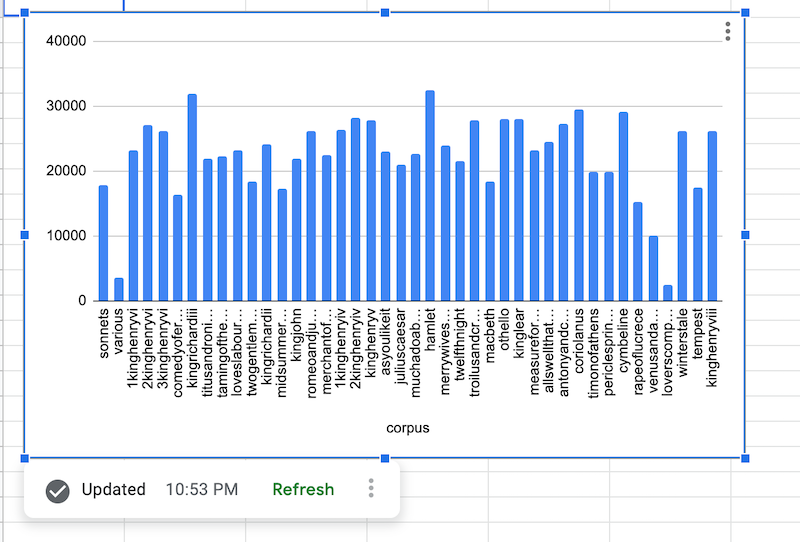
Добавить формулу источника данных BigQuery
В следующем примере кода показано, как использовать метод spreadsheets.batchUpdate и UpdateCellsRequest для создания формулы источника данных для вычисления среднего количества слов.
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
После извлечения данных BigQuery формула источника данных заполняется, как показано ниже:
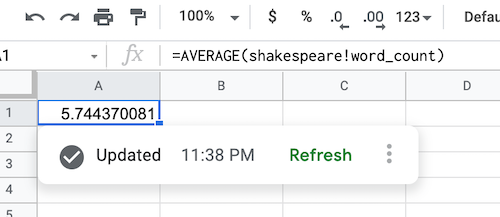
Обновить объект источника данных BigQuery
Вы можете обновить объект источника данных, чтобы получить актуальные данные из BigQuery на основе текущих спецификаций источника данных и конфигураций объекта. Вы можете использовать метод spreadsheets.batchUpdate для вызова RefreshDataSourceRequest . Затем укажите одну или несколько ссылок на объекты для обновления с помощью объекта DataSourceObjectReferences .
Обратите внимание, что вы можете как создавать, так и обновлять объекты источника данных в рамках одного запроса batchUpdate .
Управление источником данных Looker
В этом руководстве показано, как добавить источник данных Looker, обновить или удалить его, создать на его основе сводную таблицу и обновить ее.
Ваше приложение, запрашивающее данные подключенных таблиц Looker, будет повторно использовать существующую связь вашей учетной записи Google с Looker.
Добавить источник данных Looker
Чтобы добавить источник данных, отправьте запрос AddDataSourceRequest с помощью метода spreadsheets.batchUpdate . В теле запроса должно быть указано поле dataSource типа объекта DataSource .
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
Замените INSTANCE_URI , MODEL и EXPLORE на допустимый URI экземпляра Looker, имя модели и имя исследования соответственно.
После создания источника данных создается связанный лист DATA_SOURCE , который позволяет предварительно просмотреть структуру выбранного объекта Explore, включая представления, измерения, меры и описания полей.
AddDataSourceResponse содержит следующие поля:
dataSource: созданный объектDataSource.dataSourceId— это уникальный идентификатор, действующий в пределах электронной таблицы. Он заполняется и используется для создания каждого объектаDataSourceиз источника данных.dataExecutionStatus: статус выполнения импорта данных BigQuery в лист предварительного просмотра. Подробнее см. в разделе « Статус выполнения данных» .
Обновить или удалить источник данных Looker
Используйте метод spreadsheets.batchUpdate и укажите запрос UpdateDataSourceRequest или DeleteDataSourceRequest соответственно.
Управление объектами источника данных Looker
После добавления источника данных в электронную таблицу на его основе можно создать объект источника данных. Для источников данных Looker можно создать только объект DataSource pivotTable.
Невозможно создавать формулы, выдержки и диаграммы DataSource из источников данных Looker.
Обновить объект источника данных Looker
Вы можете обновить объект источника данных, чтобы получить актуальные данные из Looker на основе текущих спецификаций источника данных и конфигураций объекта. Вы можете использовать метод spreadsheets.batchUpdate для вызова RefreshDataSourceRequest . Затем укажите одну или несколько ссылок на объекты для обновления с помощью объекта DataSourceObjectReferences .
Обратите внимание, что вы можете как создавать, так и обновлять объекты источника данных в рамках одного запроса batchUpdate .
Статус выполнения данных
При создании источников данных или обновлении объектов источников данных запускается фоновое выполнение для извлечения данных из BigQuery или Looker и возврата ответа, содержащего DataExecutionStatus . Если выполнение запускается успешно, DataExecutionState обычно находится в состоянии RUNNING .
Поскольку процесс асинхронный, ваше приложение должно реализовать модель опроса для периодического получения статуса объектов источника данных. Используйте метод spreadsheets.get , пока статус не вернёт значение SUCCEEDED или FAILED . В большинстве случаев выполнение выполняется быстро, но это зависит от сложности источника данных. Обычно выполнение не превышает 10 минут.
Похожие темы
- Выберите области действия API Google Таблиц
- Начните работу с данными BigQuery в Google Таблицах
- Документация BigQuery
- BigQuery: использование подключенных таблиц
- Видеоруководство по подключенным таблицам
- Использование связанных листов для Looker
- Введение в Looker