
Cloud Search की मदद से कर्मचारी, इंटरनल डेटा रिपॉज़िटरी से जानकारी खोज सकते हैं और उसे वापस पा सकते हैं. जैसे, इंटरनल दस्तावेज़, डेटाबेस फ़ील्ड, और सीआरएम डेटा.
आर्किटेक्चर की खास जानकारी
पहली इमेज में, Cloud Search को लागू करने के मुख्य कॉम्पोनेंट दिखाए गए हैं:
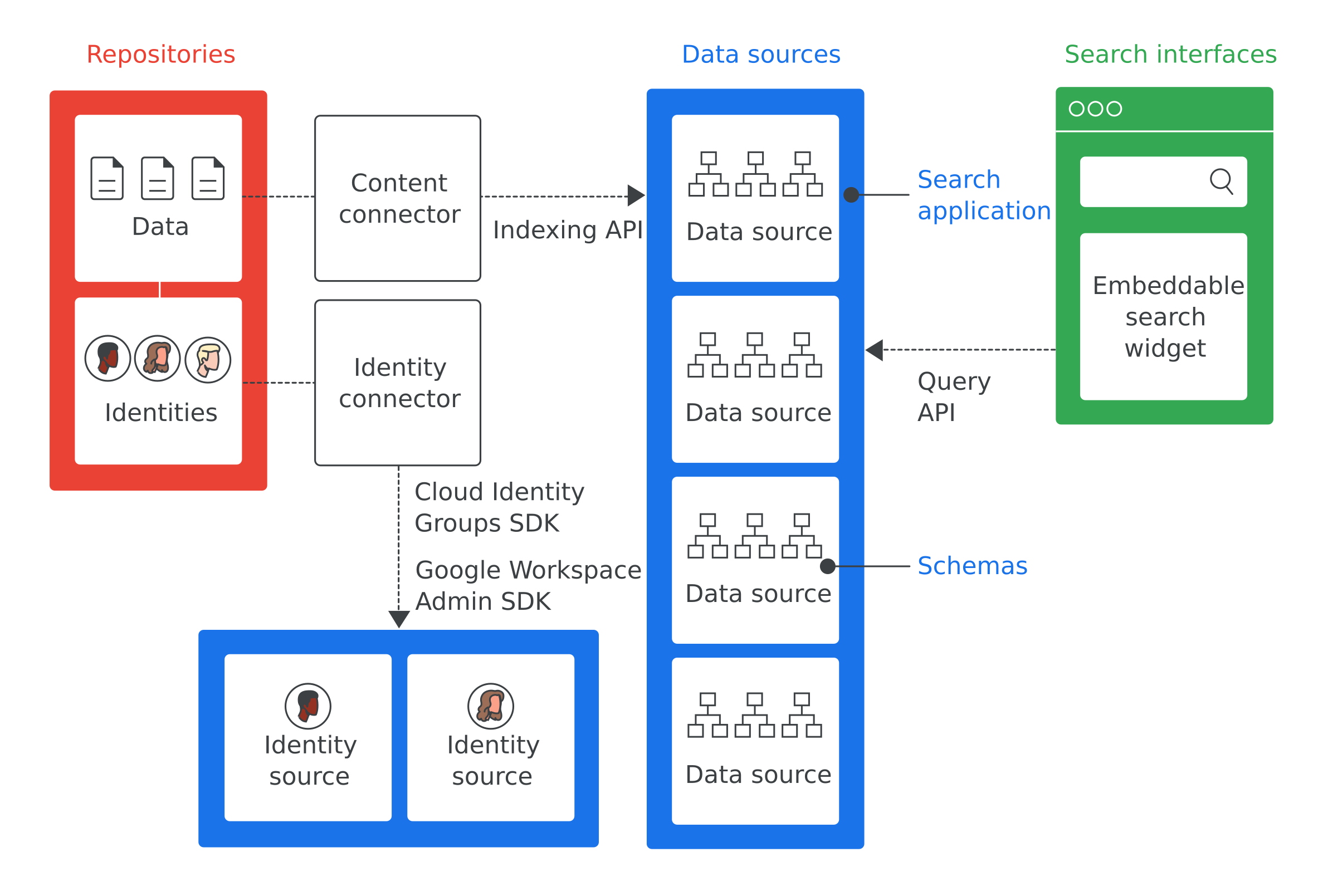
यहां इमेज 1 में दिए गए सबसे ज़रूरी शब्दों की परिभाषाएं दी गई हैं:
- डेटा स्टोर करने की जगह
- किसी कंपनी की ओर से डेटा स्टोर करने के लिए इस्तेमाल किया जाने वाला सॉफ़्टवेयर. जैसे, कर्मचारियों की जानकारी स्टोर करने के लिए इस्तेमाल किया जाने वाला डेटाबेस.
- डेटा सोर्स
- किसी ऐसी जगह से मिला डेटा जिसे Cloud Search इंडेक्स और सेव करता है.
- खोज इंटरफ़ेस
- यह यूज़र इंटरफ़ेस, कर्मचारी डेटा सोर्स खोजने के लिए इस्तेमाल करते हैं. मोबाइल फ़ोन या डेस्कटॉप कंप्यूटर जैसे किसी भी डिवाइस के लिए, खोज इंटरफ़ेस बनाया जा सकता है. Google की ओर से उपलब्ध कराए गए खोज विजेट को भी डिप्लॉय किया जा सकता है. इससे अपनी इंटरनल वेबसाइटों पर खोज करने की सुविधा चालू की जा सकती है. हर खोज में सर्च ऐप्लिकेशन आईडी शामिल होता है. इससे खोज के कॉन्टेक्स्ट की पहचान की जा सकती है. जैसे, ग्राहक सेवा टूल में. साइट cloudsearch.google.com में खोज इंटरफ़ेस होता है.
- खोज ऐप्लिकेशन
- सेटिंग का एक ग्रुप, जिसे सर्च इंटरफ़ेस से जोड़ने पर खोजों के बारे में कॉन्टेक्स्ट के हिसाब से जानकारी मिलती है. काम की जानकारी में, खोज के लिए इस्तेमाल किए गए डेटा सोर्स और खोज नतीजों में मिली रैंक शामिल होती है. खोज के लिए इस्तेमाल होने वाले ऐप्लिकेशन में, नतीजों को फ़िल्टर करने के तरीके भी शामिल होते हैं. साथ ही, ये ऐप्लिकेशन डेटा सोर्स पर रिपोर्टिंग की सुविधा देते हैं. जैसे, किसी तय समय अवधि में की गई क्वेरी की संख्या.
- स्कीमा
- यह एक डेटा स्ट्रक्चर है. इसमें बताया गया है कि Cloud Search के लिए, एंटरप्राइज़ रिपॉज़िटरी में डेटा को कैसे दिखाया जाए. स्कीमा से, कर्मचारी को Cloud Search का अनुभव मिलता है. जैसे, उपयोगकर्ता डेटा को कैसे फ़िल्टर करते हैं और देखते हैं.
- कॉन्टेंट कनेक्टर
- यह एक सॉफ़्टवेयर प्रोग्राम है. यह एंटरप्राइज़ रिपॉज़िटरी में मौजूद डेटा को प्रोसेस करता है और डेटा सोर्स में डेटा भरता है.
- पहचान कनेक्टर
- यह एक सॉफ़्टवेयर प्रोग्राम है. यह एंटरप्राइज़ आइडेंटिटी (उपयोगकर्ता और ग्रुप) को Cloud Search के लिए ज़रूरी आइडेंटिटी के साथ सिंक करता है.
Cloud Search के इस्तेमाल के उदाहरण
Cloud Search के इस्तेमाल के उदाहरण:
- कर्मचारियों को कॉर्पोरेट नीतियां, दस्तावेज़, और अन्य कर्मचारियों का बनाया गया कॉन्टेंट ढूंढना होता है.
- ग्राहक सेवा टीम के सदस्यों को, ग्राहकों को भेजने के लिए समस्या हल करने से जुड़े काम के दस्तावेज़ ढूंढने होंगे.
- कर्मचारियों को कंपनी के प्रोजेक्ट के बारे में अंदरूनी जानकारी चाहिए.
- बिक्री प्रतिनिधि को किसी खास ग्राहक के लिए, सहायता से जुड़ी सभी समस्याओं की स्थिति देखनी है.
- कर्मचारियों को कंपनी से जुड़े किसी शब्द की परिभाषा चाहिए.
Cloud Search को लागू करने का पहला चरण, काम के इस्तेमाल के उदाहरणों की पहचान करना है.
Cloud Search लागू करना
Cloud Search, डिफ़ॉल्ट रूप से Google Workspace के डेटा को इंडेक्स करता है. जैसे, Google दस्तावेज़ और स्प्रेडशीट. आपको Google Workspace डेटा के लिए, Cloud Search को लागू करने की ज़रूरत नहीं है. हालांकि, आपको Google Workspace के अलावा किसी अन्य सेवा से मिले डेटा के लिए, Cloud Search को लागू करना होगा. जैसे, तीसरे पक्ष के डेटाबेस में सेव किया गया डेटा, Windows File Share, OneDrive जैसे फ़ाइल सिस्टम या SharePoint जैसे इंट्रानेट पोर्टल. अपने एंटरप्राइज़ के लिए Cloud Search लागू करने के लिए, यह तरीका अपनाएं.
- इस्तेमाल का कोई ऐसा उदाहरण तय करें जिसे Cloud Search की मदद से हल किया जा सकता है.
- उन रिपॉज़िटरी की पहचान करें जिनमें इस्तेमाल के उदाहरण से जुड़ा डेटा मौजूद है.
- पहचान करें कि आपकी कंपनी, हर रिपॉज़िटरी में डेटा को ऐक्सेस करने की अनुमति मैनेज करने के लिए किन पहचान सिस्टम का इस्तेमाल करती है.
- Google Cloud Search API को ऐक्सेस करने की सुविधा कॉन्फ़िगर करना.
- Cloud Search में डेटा सोर्स जोड़ना.
- हर डेटा सोर्स के लिए, स्कीमा बनाएं और रजिस्टर करें.
- यह तय करें कि आपकी रिपॉज़िटरी के लिए कॉन्टेंट कनेक्टर उपलब्ध है या नहीं. पहले से बने कनेक्टर की सूची के लिए, Cloud Search कनेक्टर डायरेक्ट्री देखें. अगर कोई कॉन्टेंट कनेक्टर उपलब्ध है, तो सीधे नौवें चरण पर जाएं.
- हर रिपॉज़िटरी में मौजूद डेटा को ऐक्सेस करने और उसे Cloud Search के डेटा सोर्स में इंडेक्स करने के लिए, कॉन्टेंट कनेक्टर बनाएं.
- यह तय करें कि आपको पहचान कनेक्टर की ज़रूरत है या नहीं. अगर आपको पहचान कनेक्टर की ज़रूरत नहीं है, तो ग्यारहवें चरण पर जाएं.
- अपनी रिपॉज़िटरी या एंटरप्राइज़ की पहचानों को Google की पहचानों से मैप करने के लिए, आइडेंटिटी कनेक्टर बनाएं.
- खोज ऐप्लिकेशन सेट अप करना.
- खोज क्वेरी करने के लिए, खोज इंटरफ़ेस बनाएं.
- अपने कनेक्टर और खोज इंटरफ़ेस डिप्लॉय करें. अगर आपने पहले से बने कनेक्टर का इस्तेमाल किया है, तो कनेक्टर को पाने और डिप्लॉय करने के लिए, कनेक्टर के निर्देशों का पालन करें. उपलब्ध कनेक्टर की सूची, Cloud Search कनेक्टर डायरेक्ट्री में दी गई है.
अगले चरण
- Cloud Search का इस्तेमाल शुरू करने से जुड़ा ट्यूटोरियल देखें.
- उन इस्तेमाल के उदाहरणों के बारे में जानें जिनके लिए Cloud Search का इस्तेमाल किया जाएगा.
- इस्तेमाल के इन उदाहरणों से जुड़ी रिपॉज़िटरी की पहचान करें.
- आपकी रिपॉज़िटरी में इस्तेमाल किए गए किसी भी आइडेंटिटी सिस्टम की पहचान करें.
- Cloud Search API का ऐक्सेस कॉन्फ़िगर करें पर जाएं.