Giới thiệu về lập trình và C++
Hướng dẫn trực tuyến này tiếp tục với những khái niệm nâng cao hơn – vui lòng đọc Phần III. Trọng tâm của chúng ta trong học phần này sẽ là sử dụng con trỏ và bắt đầu với đối tượng.
Tìm hiểu theo Ví dụ 2
Trong học phần này, chúng ta sẽ tập trung vào việc thực hành phân ly, hiểu con trỏ và làm quen với đối tượng và lớp. Hãy xem các ví dụ sau. Tự viết chương trình khi được yêu cầu hoặc tự thử nghiệm. Chúng tôi không thể nhấn mạnh đủ rằng chìa khoá để trở thành một lập trình viên giỏi là thực hành, thực hành và thực hành!
Ví dụ 1: Thực hành phân rã thêm
Hãy xem xét kết quả sau đây từ một trò chơi đơn giản:
Welcome to Artillery. You are in the middle of a war and being charged by thousands of enemies. You have one cannon, which you can shoot at any angle. You only have 10 cannonballs for this target.. Let's begin... The enemy is 507 feet away!!! What angle? 25< You over shot by 445 What angle? 15 You over shot by 114 What angle? 10 You under shot by 82 What angle? 12 You under shot by 2 What angle? 12.01 You hit him!!! It took you 4 shots. You have killed 1 enemy. I see another one, are you ready? (Y/N) n You killed 1 of the enemy.
Quan sát đầu tiên là văn bản giới thiệu được hiển thị một lần cho mỗi chương trình thực thi. Chúng ta cần một trình tạo số ngẫu nhiên để xác định khoảng cách của kẻ địch mỗi lần tròn. Chúng ta cần một cơ chế để nhận thông tin đầu vào góc từ người chơi và điều này rõ ràng là ở trong một cấu trúc vòng lặp do lặp đi lặp lại cho đến khi chúng ta đánh trúng kẻ thù. Chúng tôi cũng cần một hàm để tính khoảng cách và góc. Cuối cùng, chúng ta phải theo dõi số lượng phát súng để bắn trúng kẻ thù, cũng như số lượng kẻ thù của chúng ta gặp phải trong quá trình thực thi chương trình. Sau đây là sơ lược về chương trình chính.
StartUp(); // This displays the introductory script.
killed = 0;
do {
killed = Fire(); // Fire() contains the main loop of each round.
cout << "I see another one, care to shoot again? (Y/N) " << endl;
cin >> done;
} while (done != 'n');
cout << "You killed " << killed << " of the enemy." << endl;
Quy trình Fire xử lý quá trình chơi trò chơi. Trong hàm đó, chúng ta gọi một trình tạo số ngẫu nhiên để xác định khoảng cách của kẻ địch, sau đó thiết lập vòng lặp để lấy thông tin đầu vào của người chơi và tính toán xem họ đã bắn được kẻ địch hay chưa. Chiến lược phát hành đĩa đơn điều kiện phòng thủ trong vòng lặp là việc chúng ta đã tiến gần đến việc bắn được kẻ địch đến mức nào.
In case you are a little rusty on physics, here are the calculations: Velocity = 200.0; // initial velocity of 200 ft/sec Gravity = 32.2; // gravity for distance calculation // in_angle is the angle the player has entered, converted to radians. time_in_air = (2.0 * Velocity * sin(in_angle)) / Gravity; distance = round((Velocity * cos(in_angle)) * time_in_air);
Do các lệnh gọi đến cos() và sin(), bạn sẽ cần đưa vào". Thử viết chương trình này – đây là một phương pháp tuyệt vời trong việc phân rã vấn đề và xem lại C++ cơ bản. Hãy nhớ chỉ làm một tác vụ trong mỗi hàm. Đây là chương trình tinh vi nhất mà chúng tôi đã viết từ trước đến nay. Do đó, bạn có thể mất chút thời gian đã đến lúc thực hiện việc đó.Đây là giải pháp của chúng tôi.
Ví dụ 2: Thực hành bằng con trỏ
Có 4 điều cần nhớ khi dùng con trỏ:- Con trỏ là biến lưu giữ địa chỉ bộ nhớ. Khi một chương trình đang thực thi,
tất cả biến đều được lưu trữ trong bộ nhớ, mỗi biến tại một địa chỉ hoặc vị trí duy nhất riêng.
Con trỏ là một loại biến đặc biệt có chứa địa chỉ bộ nhớ thay vì
so với giá trị dữ liệu. Giống như khi dữ liệu được sửa đổi khi sử dụng biến thông thường,
giá trị của địa chỉ lưu trữ trong con trỏ được sửa đổi dưới dạng biến con trỏ
bị bóp méo. Ví dụ:
int *intptr; // Declare a pointer that holds the address // of a memory location that can store an integer. // Note the use of * to indicate this is a pointer variable. intptr = new int; // Allocate memory for the integer. *intptr = 5; // Store 5 in the memory address stored in intptr. - Chúng ta thường nói rằng một con trỏ "trỏ" vào vị trí đang lưu trữ
("con trỏ"). Vì vậy, trong ví dụ trên, intptr trỏ đến điểm tương tác
5 điểm.
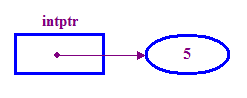
Lưu ý việc sử dụng cụm từ "mới" để phân bổ bộ nhớ cho số nguyên con trỏ. Đây là việc chúng ta phải làm trước khi cố gắng truy cập vào điểm được trỏ.
int *ptr; // Declare integer pointer. ptr = new int; // Allocate some memory for the integer. *ptr = 5; // Dereference to initialize the pointee. *ptr = *ptr + 1; // We are dereferencing ptr in order // to add one to the value stored // at the ptr address.Toán tử * được dùng để huỷ tham chiếu trong C. Một trong những lỗi phổ biến nhất Lập trình viên C/C++ làm việc với con trỏ đang quên khởi chạy con trỏ. Điều này đôi khi có thể gây ra sự cố trong thời gian chạy do chúng ta đang truy cập một vị trí trong bộ nhớ có chứa dữ liệu không xác định. Nếu chúng ta thử và sửa đổi dữ liệu, chúng tôi có thể gây hỏng bộ nhớ tinh vi, khiến đây trở thành một lỗi khó phát hiện.
- Việc gán con trỏ giữa hai con trỏ khiến chúng trỏ đến cùng một con trỏ.
Vậy phép gán y = x; làm cho y trỏ đến cùng điểm được trỏ đến x. Chỉ định con trỏ
không tiếp xúc với con trỏ. Nó chỉ thay đổi một con trỏ để có cùng một vị trí
làm con trỏ khác. Sau khi gán con trỏ, hai con trỏ sẽ "chia sẻ" thời gian
con trỏ.
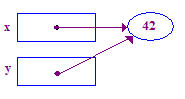
void main() {
int* x; // Allocate the pointers x and y
int* y; // (but not the pointees).
x = new int; // Allocate an int pointee and set x to point to it.
*x = 42; // Dereference x and store 42 in its pointee
*y = 13; // CRASH -- y does not have a pointee yet
y = x; // Pointer assignment sets y to point to x's pointee
*y = 13; // Dereference y to store 13 in its (shared) pointee
}
Dưới đây là dấu vết của mã này:
| 1. Phân bổ hai con trỏ x và y. Việc phân bổ con trỏ sẽ thực hiện không phân bổ bất kỳ điểm nào. | 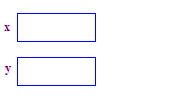 |
| 2. Phân bổ một người được trỏ đến và đặt x để trỏ đến điểm đó. | 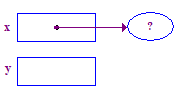 |
| 3. Tham chiếu x để lưu trữ 42 trong điểm tương tác. Đây là một ví dụ cơ bản của toán tử tham chiếu. Bắt đầu tại x, đi theo mũi tên qua để truy cập con trỏ. | 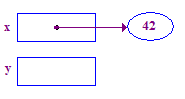 |
| 4. Hãy cố gắng loại bỏ y để lưu trữ 13 trong điểm trỏ. Ứng dụng này gặp sự cố vì có không có người được chỉ định -- người này chưa bao giờ được chỉ định người đó. | 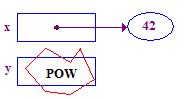 |
| 5. Cho y = x; sao cho y trỏ đến con trỏ của x. Bây giờ x và y trỏ đến cùng một người được chỉ định -- chúng "đang chia sẻ". | 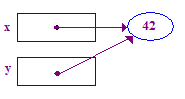 |
| 6. Hãy cố gắng loại bỏ y để lưu trữ 13 trong điểm trỏ. Lần này tính năng này sẽ hoạt động. vì bài tập trước đã cho bạn một con trỏ. | 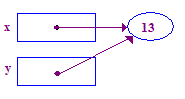 |
Như bạn có thể thấy, hình ảnh rất hữu ích trong việc hiểu cách sử dụng con trỏ. Sau đây là một ví dụ khác.
int my_int = 46; // Declare a normal integer variable.
// Set it to equal 46.
// Declare a pointer and make it point to the variable my_int
// by using the address-of operator.
int *my_pointer = &my_int;
cout << my_int << endl; // Displays 46.
*my_pointer = 107; // Derefence and modify the variable.
cout << my_int << endl; // Displays 107.
cout << *my_pointer << endl; // Also 107.
Lưu ý trong ví dụ này là chúng ta chưa bao giờ phân bổ bộ nhớ bằng giá trị "new" toán tử. Chúng ta đã khai báo một biến số nguyên thông thường và thao tác biến đó thông qua con trỏ.
Trong ví dụ này, chúng tôi minh hoạ việc sử dụng toán tử xoá để huỷ phân bổ bộ nhớ vùng nhớ khối xếp và cách chúng ta có thể phân bổ cho các cấu trúc phức tạp hơn. Chúng ta sẽ tìm hiểu tổ chức bộ nhớ (vùng nhớ khối xếp và ngăn xếp thời gian chạy) trong một bài học khác. Hiện tại, chỉ hãy xem vùng nhớ khối xếp là nơi lưu trữ bộ nhớ trống dùng được để chạy các chương trình.
int *ptr1; // Declare a pointer to int. ptr1 = new int; // Reserve storage and point to it. float *ptr2 = new float; // Do it all in one statement. delete ptr1; // Free the storage. delete ptr2;
Trong ví dụ cuối cùng này, chúng tôi cho thấy cách dùng con trỏ để truyền giá trị bằng cách tham chiếu vào một hàm. Đây là cách chúng ta sửa đổi giá trị của các biến trong hàm.
// Passing parameters by reference.
#include <iostream>
using namespace std;
void Duplicate(int& a, int& b, int& c) {
a *= 2;
b *= 2;
c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(x, y, z);
// The following outputs: x=2, y=6, z=14.
cout << "x="<< x << ", y="<< y << ", z="<< z;
return 0;
}
Nếu chúng ta bỏ và tắt đối số trong định nghĩa Hàm trùng lặp, chúng ta truyền các biến "theo giá trị", tức là một bản sao được tạo từ giá trị của biến. Mọi thay đổi đối với biến trong hàm đều sẽ sửa đổi bản sao. Chúng không sửa đổi biến gốc.
Khi một biến được truyền bằng tham chiếu, chúng ta sẽ không chuyển bản sao giá trị của biến đó, chúng ta sẽ truyền địa chỉ của biến vào hàm. Bất kỳ sửa đổi nào chúng ta sẽ làm với biến cục bộ thực sự sửa đổi biến gốc được truyền vào.
Nếu bạn là lập trình viên C, đây là một bước ngoặt mới. Chúng tôi có thể làm tương tự trong C bằng cách khai báo Duplicate() dưới dạng Duplicate(int *x), trong trường hợp đó, x là một con trỏ đến một int, sau đó gọi Duplicate() với đối số &x (địa chỉ của x) và sử dụng quy trình loại bỏ tham chiếu của x trong Duplicate() (xem bên dưới). Tuy nhiên, C++ cung cấp một phương pháp đơn giản hơn để truyền giá trị vào các hàm bằng cách tham chiếu, mặc dù "C" cũ vẫn hoạt động hiệu quả.
void Duplicate(int *a, int *b, int *c) {
*a *= 2;
*b *= 2;
*c *= 2;
}
int main() {
int x = 1, y = 3, z = 7;
Duplicate(&x, &y, &z);
// The following outputs: x=2, y=6, z=14.
cout << "x=" << x << ", y=" << y << ", z=" << z;
return 0;
}
Lưu ý với tham chiếu C++, chúng ta không cần truyền địa chỉ của biến, cũng như chúng ta có cần tham chiếu biến bên trong hàm được gọi không.
Chương trình sau đây tạo ra gì? Vẽ một bức tranh kỷ niệm để tìm hiểu.
void DoIt(int &foo, int goo);
int main() {
int *foo, *goo;
foo = new int;
*foo = 1;
goo = new int;
*goo = 3;
*foo = *goo + 3;
foo = goo;
*goo = 5;
*foo = *goo + *foo;
DoIt(*foo, *goo);
cout << (*foo) << endl;
}
void DoIt(int &foo, int goo) {
foo = goo + 3;
goo = foo + 4;
foo = goo + 3;
goo = foo;
} Chạy chương trình để xem bạn có trả lời đúng hay không.
Ví dụ 3: Chuyển giá trị theo tham chiếu
Viết một hàm có tên là tăng tốc(). Hàm này lấy dữ liệu đầu vào về vận tốc của xe và một số tiền. Hàm này thêm giá trị tốc độ để tăng tốc xe. Tham số tốc độ phải được truyền qua tham chiếu và số tiền theo giá trị. Đây là giải pháp của chúng tôi.
Ví dụ 4: Lớp và Đối tượng
Hãy xem xét lớp sau:
// time.cpp, Maggie Johnson
// Description: A simple time class.
#include <iostream>
using namespace std;
class Time {
private:
int hours_;
int minutes_;
int seconds_;
public:
void set(int h, int m, int s) {hours_ = h; minutes_ = m; seconds_ = s; return;}
void increment();
void display();
};
void Time::increment() {
seconds_++;
minutes_ += seconds_/60;
hours_ += minutes_/60;
seconds_ %= 60;
minutes_ %= 60;
hours_ %= 24;
return;
}
void Time::display() {
cout << (hours_ % 12 ? hours_ % 12:12) << ':'
<< (minutes_ < 10 ? "0" :"") << minutes_ << ':'
<< (seconds_ < 10 ? "0" :"") << seconds_
<< (hours_ < 12 ? " AM" : " PM") << endl;
}
int main() {
Time timer;
timer.set(23,59,58);
for (int i = 0; i < 5; i++) {
timer.increment();
timer.display();
cout << endl;
}
}
Lưu ý rằng các biến thành phần của lớp có dấu gạch dưới ở cuối. Việc này được thực hiện để phân biệt giữa biến cục bộ và biến lớp.
Hãy thêm một phương thức giảm vào lớp này. Đây là giải pháp của chúng tôi.
Điều kỳ diệu của Khoa học: Khoa học máy tính
Bài tập
Như trong học phần đầu tiên của khóa học này, chúng tôi không cung cấp giải pháp cho các bài tập thể dục và dự án.
Đừng quên rằng đây là một chương trình tốt...
... được phân rã theo logic thành các hàm mà một hàm bất kỳ thực hiện một và chỉ một nhiệm vụ.
... có một chương trình chính đọc như một dàn ý về những việc mà chương trình này sẽ làm.
... có hàm mô tả, tên hằng số và tên biến.
... dùng hằng số để tránh mọi "phép thuật" trong chương trình.
... có giao diện người dùng thân thiện.
Bài tập khởi động
- Bài tập 1
Số nguyên 36 có một đặc điểm riêng: đó là một số chính phương và tổng các số nguyên từ 1 đến 8. Số tiếp theo là 1225 là 352 và tổng của các số nguyên từ 1 đến 49. Tìm số tiếp theo đó là số chính phương và tổng của chuỗi 1...n. Số tiếp theo này có thể lớn hơn 32767. Bạn có thể sử dụng các hàm thư viện mà bạn biết, (hoặc các công thức toán học) để làm cho chương trình của bạn chạy nhanh hơn. Cũng có thể để viết chương trình này bằng cách sử dụng vòng lặp để xác định xem một số có hoàn hảo hay không bình phương hoặc tổng của một chuỗi. (Lưu ý: tuỳ thuộc vào máy và chương trình của bạn, có thể mất khá nhiều thời gian để tìm thấy số này).
- Bài tập 2
Cửa hàng sách trường đại học của bạn cần bạn giúp ước tính công việc kinh doanh tiếp theo năm. Kinh nghiệm cho thấy rằng doanh số bán hàng phụ thuộc rất lớn vào việc có cần sách hay không cho một khoá học hay chỉ không bắt buộc và liệu khoá học đó có được sử dụng trong lớp hay không trước đó. Một cuốn sách giáo khoa bắt buộc mới sẽ bán được cho 90% số học sinh đăng ký học, nhưng nếu trước đó nó đã được sử dụng trong lớp học thì chỉ 65% sẽ mua. Tương tự, 40% số người ghi danh tiềm năng sẽ mua sách giáo khoa mới, không bắt buộc, nhưng nếu nó đã được sử dụng trong lớp học trước khi chỉ có 20% mua. (Lưu ý rằng từ "đã qua sử dụng" ở đây không có nghĩa là sách đã qua sử dụng.)
Viết một chương trình chấp nhận nhập một bộ sách làm dữ liệu đầu vào (cho đến khi người dùng nhập một giám sát). Đối với mỗi cuốn sách, yêu cầu: một mã cho sách, chi phí một bản sao cho sách, số lượng sách hiện có trong tay, số lượng đăng ký lớp học dự kiến, và dữ liệu cho biết sách đó là bắt buộc/không bắt buộc, mới/đã qua sử dụng hay chưa. Như đầu ra, hãy hiển thị tất cả thông tin đầu vào trong một màn hình được định dạng đẹp mắt cùng với số lượng sách phải đặt hàng (nếu có, lưu ý rằng chỉ đặt mua sách mới), tổng chi phí của mỗi đơn đặt hàng.
Sau khi nhập xong toàn bộ thông tin, hãy hiện tổng chi phí của tất cả các đơn đặt hàng sách, và lợi nhuận dự kiến nếu cửa hàng thanh toán 80% giá niêm yết. Vì chúng tôi chưa thảo luận về mọi cách xử lý một tập hợp lớn dữ liệu được đưa vào một chương trình (giữ nguyên đã điều chỉnh!), bạn chỉ cần xử lý mỗi lần một cuốn sách và hiển thị màn hình đầu ra cho cuốn sách đó. Sau đó, khi người dùng đã nhập xong tất cả dữ liệu, chương trình của bạn sẽ hiển thị giá trị tổng cộng và lợi nhuận.
Trước khi bắt đầu viết mã, hãy dành thời gian suy nghĩ về thiết kế của chương trình này. Phân rã thành một tập hợp hàm và tạo một hàm main() có dạng như bản phác thảo cho giải pháp của bạn cho vấn đề. Hãy đảm bảo mỗi hàm thực hiện một tác vụ.
Dưới đây là kết quả mẫu:
Please enter the book code: 1221 single copy price: 69.95 number on hand: 30 prospective enrollment: 150 1 for reqd/0 for optional: 1 1 for new/0 for used: 0 *************************************************** Book: 1221 Price: $69.95 Inventory: 30 Enrollment: 150 This book is required and used. *************************************************** Need to order: 67 Total Cost: $4686.65 *************************************************** Enter 1 to do another book, 0 to stop. 0 *************************************************** Total for all orders: $4686.65 Profit: $937.33 ***************************************************
Dự án cơ sở dữ liệu
Trong dự án này, chúng tôi sẽ tạo một chương trình C++ có đầy đủ chức năng để triển khai một chương trình ứng dụng cơ sở dữ liệu.
Chương trình của chúng tôi sẽ giúp chúng tôi quản lý một cơ sở dữ liệu về các nhạc sĩ và thông tin liên quan về họ. Các tính năng của chương trình bao gồm:
- Có thể thêm một nhà soạn nhạc mới
- Khả năng xếp hạng một nhà soạn nhạc (ví dụ: cho biết mức độ chúng tôi thích hoặc không thích nhạc của nhà soạn nhạc)
- Có thể xem tất cả các nhà soạn nhạc trong cơ sở dữ liệu
- Có thể xem tất cả các nhà soạn nhạc theo thứ hạng
"Có hai cách để tạo thiết kế phần mềm: Một cách là làm cho phần mềm trở nên đơn giản đến mức không có khuyết điểm nào, và một cách khác là làm cho quy trình trở nên phức tạp đến mức không không có thiếu sót rõ ràng nào. Phương pháp đầu tiên khó hơn nhiều." – C.A.R. Hoare
Nhiều người trong chúng ta đã học cách thiết kế và lập trình bằng cách sử dụng "quy trình" phương pháp tiếp cận. Câu hỏi trọng tâm mà chúng tôi bắt đầu là "Chương trình phải làm gì?". T4 phân tách giải pháp cho một bài toán thành các nhiệm vụ, mỗi nhiệm vụ giải một phần của sự cố. Các tác vụ này liên kết đến các hàm trong chương trình của chúng ta được gọi tuần tự từ main() hoặc từ các hàm khác. Phương pháp từng bước này phù hợp với một số những vấn đề mà chúng tôi cần giải quyết. Nhưng thực tế là các chương trình của chúng tôi không chỉ đơn thuần là mô hình tuyến tính trình tự của các nhiệm vụ hoặc sự kiện.
Với cách tiếp cận hướng đối tượng (OO), chúng tôi bắt đầu với câu hỏi "Thế giới thực nào mà tôi đang lập mô hình?" Thay vì chia chương trình thành các tác vụ như mô tả ở trên, chúng tôi chia thành các mô hình đối tượng thực tế. Những vật thể này có một trạng thái được xác định bởi một tập hợp các thuộc tính và một tập hợp các hành vi hoặc hành động mà chúng có thể thực hiện. Các hành động có thể làm thay đổi trạng thái của đối tượng hoặc có thể gọi hành động của các đối tượng khác. Tiền đề cơ bản là một đối tượng "biết" cách thức để tự làm mọi việc.
Trong thiết kế OO, chúng ta xác định các đối tượng thực tế theo lớp và đối tượng; thuộc tính và hành vi. Nhìn chung, có một số lượng lớn đối tượng trong một chương trình OO. Tuy nhiên, nhiều đối tượng trong số này về cơ bản là giống nhau. Hãy cân nhắc những điều sau.
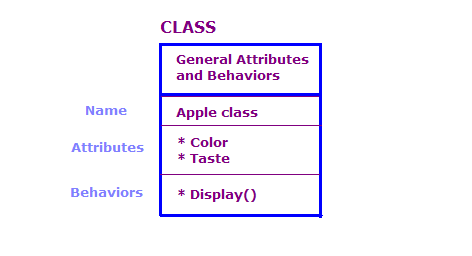
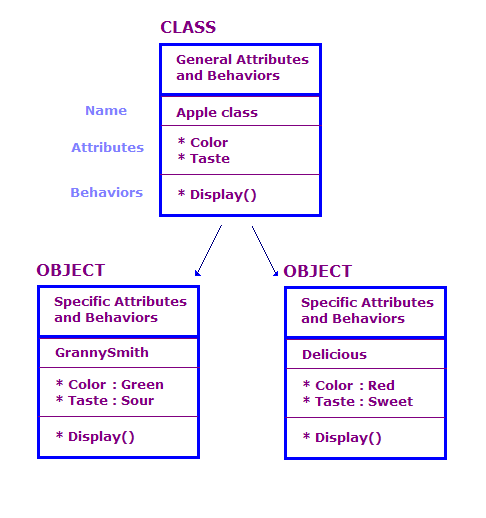
Trong sơ đồ này, chúng ta đã xác định 2 đối tượng thuộc lớp Apple. Mỗi đối tượng có các thuộc tính và hành động giống như lớp, nhưng đối tượng xác định các thuộc tính cho một loại táo cụ thể. Ngoài ra, màn hình thì hành động hiển thị các thuộc tính cho đối tượng cụ thể đó, ví dụ: "Xanh lục" và "Sour".
Một thiết kế OO bao gồm một tập hợp các lớp, dữ liệu được liên kết với các lớp này, và tập hợp hành động mà các lớp có thể thực hiện. Chúng tôi cũng cần xác định cách các lớp khác nhau tương tác. Hoạt động tương tác này có thể do các đối tượng thực hiện của một lớp gọi hành động của đối tượng của các lớp khác. Ví dụ: chúng tôi có thể có lớp AppleOutputer để xuất ra màu sắc và vị của một mảng của đối tượng Apple, bằng cách gọi phương thức Display() của từng đối tượng Apple.
Dưới đây là các bước chúng tôi thực hiện trong quá trình thiết kế OO:
- Xác định các lớp và định nghĩa chung về một đối tượng của mỗi lớp lưu trữ dưới dạng dữ liệu và những gì đối tượng có thể làm.
- Xác định các phần tử dữ liệu của từng lớp
- Xác định các thao tác của từng lớp và cách thực hiện một số thao tác của một lớp
được triển khai bằng cách sử dụng hành động của các lớp liên quan khác.
Đối với một hệ thống lớn, các bước này diễn ra lặp đi lặp lại ở các mức độ chi tiết khác nhau.
Đối với hệ thống cơ sở dữ liệu trình soạn thảo, chúng ta cần một lớp Composer đóng gói tất cả dữ liệu chúng tôi muốn lưu trữ trên từng nhạc sĩ. Một đối tượng của lớp này có thể tự thăng cấp hoặc giảm hạng (thay đổi thứ hạng) và hiển thị các thuộc tính của trang web đó.
Chúng ta cũng cần một tập hợp các đối tượng Composer. Để làm được điều này, chúng ta xác định lớp Cơ sở dữ liệu để quản lý từng bản ghi. Một đối tượng của lớp này có thể thêm hoặc truy xuất đối tượng Compose và hiện các đối tượng riêng lẻ bằng cách gọi thao tác hiển thị đối tượng Composer.
Cuối cùng, chúng ta cần một số loại giao diện người dùng để cung cấp các thao tác tương tác trên cơ sở dữ liệu. Đây là một lớp giữ chỗ, tức là chúng tôi thực sự không biết giao diện người dùng vẫn chưa hoàn thiện, nhưng chúng tôi biết mình sẽ cần có. Có thể hình ảnh sẽ ở dạng đồ hoạ, có thể dưới dạng văn bản. Hiện tại, chúng tôi xác định trình giữ chỗ chúng tôi có thể điền sau.
Bây giờ, chúng ta đã xác định được các lớp cho ứng dụng cơ sở dữ liệu trình soạn thảo, bước tiếp theo là xác định thuộc tính và thao tác cho các lớp. Xem thêm đơn đăng ký phức tạp, chúng tôi sẽ thảo luận với bút chì và giấy hoặc UML hoặc thẻ CRC hoặc OOD để liên kết hệ phân cấp lớp và cách các đối tượng tương tác.
Đối với cơ sở dữ liệu Compose, chúng ta xác định một lớp Composer chứa thông tin liên quan mà chúng tôi muốn lưu trữ trên mỗi trình soạn thảo. Lớp này cũng chứa các phương thức điều khiển thứ hạng và hiển thị dữ liệu.
Lớp Cơ sở dữ liệu cần một loại cấu trúc nào đó để lưu giữ các đối tượng Composer. Chúng ta cần có khả năng thêm một đối tượng Composer mới vào cấu trúc, cũng như truy xuất một đối tượng Composer cụ thể. Chúng tôi cũng muốn hiển thị tất cả các đối tượng theo thứ tự xuất hiện hoặc thứ hạng.
Lớp Giao diện người dùng triển khai giao diện dựa trên trình đơn, với các trình xử lý trong lớp Cơ sở dữ liệu.
Nếu các lớp dễ hiểu và các thuộc tính cũng như hành động của chúng rõ ràng, như trong ứng dụng trình soạn thảo, việc thiết kế các lớp tương đối dễ dàng. Nhưng nếu có thắc mắc về mối liên hệ và tương tác giữa các lớp học, tốt nhất là bạn nên vẽ ra trước rồi xem xét các chi tiết trước khi bắt đầu để lập trình.
Sau khi chúng tôi nắm được rõ ràng thiết kế và đánh giá thiết kế đó (thông tin thêm về sớm), chúng ta sẽ xác định giao diện cho từng lớp. Chúng tôi không lo lắng về việc triển khai chi tiết vào thời điểm này – chỉ các thuộc tính và hành động là gì và những phần nào của một lớp trạng thái và thao tác có sẵn cho các lớp khác.
Trong C++, chúng ta thường thực hiện việc này bằng cách xác định tệp tiêu đề cho mỗi lớp. Composer (Nhà soạn nhạc) có các thành phần dữ liệu riêng tư cho tất cả dữ liệu chúng ta muốn lưu trữ trên trình soạn thảo. Chúng ta cần có các phương thức truy cập (phương thức "get") và phương thức biến đổi (mutator) ("set"), cũng như các thao tác chính cho lớp.
// composer.h, Maggie Johnson
// Description: The class for a Composer record.
// The default ranking is 10 which is the lowest possible.
// Notice we use const in C++ instead of #define.
const int kDefaultRanking = 10;
class Composer {
public:
// Constructor
Composer();
// Here is the destructor which has the same name as the class
// and is preceded by ~. It is called when an object is destroyed
// either by deletion, or when the object is on the stack and
// the method ends.
~Composer();
// Accessors and Mutators
void set_first_name(string in_first_name);
string first_name();
void set_last_name(string in_last_name);
string last_name();
void set_composer_yob(int in_composer_yob);
int composer_yob();
void set_composer_genre(string in_composer_genre);
string composer_genre();
void set_ranking(int in_ranking);
int ranking();
void set_fact(string in_fact);
string fact();
// Methods
// This method increases a composer's rank by increment.
void Promote(int increment);
// This method decreases a composer's rank by decrement.
void Demote(int decrement);
// This method displays all the attributes of a composer.
void Display();
private:
string first_name_;
string last_name_;
int composer_yob_; // year of birth
string composer_genre_; // baroque, classical, romantic, etc.
string fact_;
int ranking_;
};
Lớp Cơ sở dữ liệu cũng dễ dàng.
// database.h, Maggie Johnson
// Description: Class for a database of Composer records.
#include <iostream>
#include "Composer.h"
// Our database holds 100 composers, and no more.
const int kMaxComposers = 100;
class Database {
public:
Database();
~Database();
// Add a new composer using operations in the Composer class.
// For convenience, we return a reference (pointer) to the new record.
Composer& AddComposer(string in_first_name, string in_last_name,
string in_genre, int in_yob, string in_fact);
// Search for a composer based on last name. Return a reference to the
// found record.
Composer& GetComposer(string in_last_name);
// Display all composers in the database.
void DisplayAll();
// Sort database records by rank and then display all.
void DisplayByRank();
private:
// Store the individual records in an array.
Composer composers_[kMaxComposers];
// Track the next slot in the array to place a new record.
int next_slot_;
};
Hãy chú ý cách chúng tôi đóng gói cẩn thận dữ liệu dành riêng cho nhà soạn nhạc trong một . Chúng ta có thể đặt một cấu trúc hoặc lớp trong lớp Cơ sở dữ liệu để biểu thị Composer ghi lại và truy cập trực tiếp vào đó. Nhưng đó sẽ là "dưới đối tượng", tức là chúng tôi không lập mô hình bằng các đối tượng nhiều như nhiều nhất có thể.
Bạn sẽ thấy khi bắt đầu thực hiện việc triển khai Composer và Database các lớp này, rằng việc có một lớp Composer riêng biệt sẽ gọn gàng hơn nhiều. Cụ thể, có các hoạt động nguyên tử riêng biệt trên đối tượng Composer giúp đơn giản hoá đáng kể việc triển khai của phương thức Display() trong lớp Database.
Đương nhiên, vấn đề này cũng có những vấn đề như "đối tượng quá mức" ở đâu chúng ta cố gắng biến mọi thứ thành một lớp hoặc chúng ta có nhiều lớp hơn mức cần thiết. Cần thực hành để tìm ra điểm cân bằng phù hợp và bạn sẽ thấy rằng từng lập trình viên sẽ có ý kiến khác nhau.
Việc xác định xem bạn đặt mình quá mức hay quá thấp thường có thể được sắp xếp bằng cách cẩn thận lập biểu đồ cho các lớp của mình. Như đã đề cập trước đó, bạn cần phải tạo một lớp thiết kế trước khi bắt đầu lập trình và điều này có thể giúp bạn phân tích phương pháp tiếp cận của mình. Điểm chung ký hiệu được sử dụng cho mục đích này là UML (Ngôn ngữ lập mô hình hợp nhất) Bây giờ, chúng ta đã xác định các lớp cho đối tượng Composer và Database (Cơ sở dữ liệu), chúng ta cần một giao diện cho phép người dùng tương tác với cơ sở dữ liệu. Một trình đơn đơn giản sẽ thực hiện thủ thuật:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Chúng ta có thể triển khai giao diện người dùng dưới dạng lớp hoặc chương trình quy trình. Không phải mọi thứ trong chương trình C++ đều phải là một lớp. Trên thực tế, nếu quá trình xử lý diễn ra tuần tự hoặc theo tác vụ, như trong chương trình trình đơn này, bạn có thể triển khai theo quy trình. Bạn cần phải triển khai mã này sao cho mã vẫn là một "phần giữ chỗ", tức là, nếu chúng ta muốn tạo giao diện người dùng đồ hoạ tại một thời điểm nào đó, chúng ta phải không phải thay đổi gì trong hệ thống trừ giao diện người dùng.
Điều cuối cùng chúng ta cần hoàn tất đơn đăng ký là một chương trình kiểm thử các lớp. Đối với lớp Composer, chúng ta cần có một chương trình main() nhận thông tin đầu vào, điền sẵn đối tượng Compose rồi cho thấy đối tượng này để đảm bảo lớp hoạt động đúng cách. Chúng ta cũng muốn gọi tất cả các phương thức của lớp Composer.
// test_composer.cpp, Maggie Johnson
//
// This program tests the Composer class.
#include <iostream>
#include "Composer.h"
using namespace std;
int main()
{
cout << endl << "Testing the Composer class." << endl << endl;
Composer composer;
composer.set_first_name("Ludwig van");
composer.set_last_name("Beethoven");
composer.set_composer_yob(1770);
composer.set_composer_genre("Romantic");
composer.set_fact("Beethoven was completely deaf during the latter part of "
"his life - he never heard a performance of his 9th symphony.");
composer.Promote(2);
composer.Demote(1);
composer.Display();
}
Chúng ta cần một chương trình kiểm thử tương tự cho lớp Cơ sở dữ liệu.
// test_database.cpp, Maggie Johnson
//
// Description: Test driver for a database of Composer records.
#include <iostream>
#include "Database.h"
using namespace std;
int main() {
Database myDB;
// Remember that AddComposer returns a reference to the new record.
Composer& comp1 = myDB.AddComposer("Ludwig van", "Beethoven", "Romantic", 1770,
"Beethoven was completely deaf during the latter part of his life - he never "
"heard a performance of his 9th symphony.");
comp1.Promote(7);
Composer& comp2 = myDB.AddComposer("Johann Sebastian", "Bach", "Baroque", 1685,
"Bach had 20 children, several of whom became famous musicians as well.");
comp2.Promote(5);
Composer& comp3 = myDB.AddComposer("Wolfgang Amadeus", "Mozart", "Classical", 1756,
"Mozart feared for his life during his last year - there is some evidence "
"that he was poisoned.");
comp3.Promote(2);
cout << endl << "all Composers: " << endl << endl;
myDB.DisplayAll();
}
Lưu ý rằng các chương trình thử nghiệm đơn giản này là bước đầu tiên tốt, nhưng chúng đòi hỏi chúng tôi để kiểm tra đầu ra theo cách thủ công nhằm đảm bảo chương trình đang hoạt động chính xác. Như một hệ thống trở nên lớn hơn, nên việc kiểm tra đầu ra theo cách thủ công nhanh chóng trở nên không thực tế. Trong bài học tiếp theo, chúng tôi sẽ giới thiệu chương trình kiểm tra tự kiểm tra ở dạng biểu mẫu kiểm thử đơn vị.
Thiết kế cho ứng dụng của chúng ta hiện đã hoàn tất. Bước tiếp theo là triển khai tệp .cpp cho các lớp và giao diện người dùng.Để bắt đầu, hãy tiếp tục và sao chép/dán mã .h và mã trình điều khiển kiểm thử ở trên vào các tệp rồi biên dịch các tệp đó.Sử dụng trình điều khiển thử nghiệm để kiểm tra lớp học của bạn. Sau đó, hãy triển khai giao diện sau:
Composer Database --------------------------------------------- 1) Add a new composer 2) Retrieve a composer's data 3) Promote/demote a composer's rank 4) List all composers 5) List all composers by rank 0) Quit
Dùng các phương thức mà bạn đã xác định trong lớp Cơ sở dữ liệu để triển khai giao diện người dùng. Đảm bảo phương thức của bạn không bị lỗi. Ví dụ: thứ hạng phải luôn nằm trong phạm vi 1 – 10. Cũng không cho phép bất kỳ ai thêm 101 nhà soạn nhạc, trừ phi bạn định thay đổi cấu trúc dữ liệu trong lớp Cơ sở dữ liệu.
Hãy nhớ rằng tất cả mã của bạn đều cần tuân theo quy ước lập trình của chúng tôi, chẳng hạn như tại đây để thuận tiện cho bạn:
- Mỗi chương trình chúng tôi viết đều bắt đầu với một chú thích ở tiêu đề, cung cấp tên của tác giả, thông tin liên hệ của họ, mô tả ngắn và cách sử dụng (nếu thích hợp). Mỗi hàm/phương thức bắt đầu bằng một nhận xét về hoạt động và cách sử dụng.
- Chúng tôi thêm nhận xét giải thích bằng cách sử dụng câu đầy đủ, bất cứ khi nào mã này không ghi lại chính nó, ví dụ: nếu quá trình xử lý phức tạp, không rõ ràng, thú vị hoặc quan trọng.
- Luôn sử dụng tên mô tả: biến là các từ viết thường được phân tách bằng _, như trong my_variable. Tên hàm/phương thức sử dụng chữ hoa để đánh dấu các từ, như trong MyExciteFunction(). Hằng số bắt đầu bằng một chữ "k" và sử dụng chữ hoa để đánh dấu từ, như trong kDaysInWeek.
- Thụt lề là bội số của 2. Cấp đầu tiên là hai không gian; nếu tiếp tục cần thụt lề, chúng tôi sử dụng 4 dấu cách, 6 dấu cách, v.v.
Chào mừng bạn đến với Thế giới thực!
Trong học phần này, chúng tôi giới thiệu hai công cụ rất quan trọng được sử dụng trong hầu hết kỹ thuật phần mềm tổ chức. Phần đầu tiên là một công cụ xây dựng và phần thứ hai là quản lý cấu hình hệ thống. Cả hai công cụ này đều cần thiết trong kỹ thuật phần mềm công nghiệp, nơi mà nhiều kỹ sư thường làm việc trên một hệ thống lớn. Những công cụ này hỗ trợ bạn sắp xếp và kiểm soát các thay đổi đối với cơ sở mã và cung cấp phương tiện hiệu quả để biên dịch và liên kết một hệ thống từ nhiều tệp chương trình và tệp tiêu đề.
Tệp tạo tệp
Quá trình xây dựng một chương trình thường được quản lý bằng một công cụ xây dựng, công cụ này sẽ biên dịch rồi liên kết các tệp bắt buộc theo đúng thứ tự. Thông thường, tệp C++ có các phần phụ thuộc, ví dụ: hàm được gọi trong một chương trình nằm trong một chương trình khác . Hoặc có thể một số tệp .cpp sẽ cần tệp tiêu đề. Đáp công cụ tạo bản dựng sẽ chỉ ra thứ tự biên dịch chính xác từ các phần phụ thuộc này. Việc này sẽ chỉ biên dịch các tệp đã thay đổi kể từ bản dựng gần nhất. Điều này có thể lưu trong các hệ thống gồm hàng trăm hoặc hàng nghìn tệp.
Công cụ tạo nguồn mở có tên là make thường được sử dụng. Để tìm hiểu về công cụ này, hãy đọc thông qua hình thức này bài viết này. Xem liệu bạn có thể tạo biểu đồ phần phụ thuộc cho ứng dụng Cơ sở dữ liệu Composer hay không, rồi dịch tệp này vào một tệp makefile.Đây là giải pháp của chúng tôi.
Hệ thống quản lý cấu hình
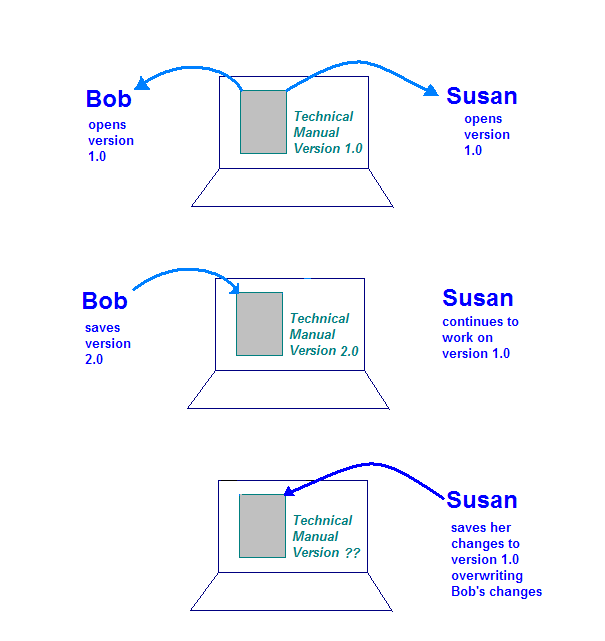
Công cụ thứ hai được dùng trong kỹ thuật phần mềm công nghiệp là Quản lý cấu hình (Quản trị viên diễn đàn). Giá trị này được dùng để quản lý thay đổi. Giả sử Bob và Susan đều là nhà văn công nghệ và cả hai đều đang nghiên cứu bản cập nhật cho một hướng dẫn kỹ thuật. Trong cuộc họp, người quản lý sẽ chỉ định cho họ một phần của cùng một tài liệu cần cập nhật.
Hướng dẫn kỹ thuật được lưu trữ trên máy tính mà cả Bob và Susan đều có thể truy cập. Nếu không có sẵn bất kỳ công cụ hoặc quy trình CM nào, một số vấn đề có thể phát sinh. Một trường hợp có thể xảy ra là máy tính lưu trữ tài liệu có thể được thiết lập sao cho Cả Bob và Susan không thể cùng làm việc trên tài liệu hướng dẫn. Quá trình này sẽ làm chậm giảm đáng kể.
Một tình huống nguy hiểm hơn sẽ xảy ra khi máy tính lưu trữ cho phép tài liệu để cả Bob và Susan mở cùng một lúc. Dưới đây là những gì có thể xảy ra:
- Bob mở tài liệu trên máy tính và làm theo phần của mình.
- Susan mở tài liệu trên máy tính và làm theo phần của mình.
- Bob hoàn tất các thay đổi và lưu tài liệu vào máy tính lưu trữ.
- Susan hoàn tất các thay đổi và lưu tài liệu vào máy tính lưu trữ.
Hình minh hoạ này cho thấy vấn đề có thể xảy ra nếu không có chế độ kiểm soát trên một bản sao của hướng dẫn kỹ thuật. Khi Susan lưu những thay đổi của mình, cô ấy sẽ ghi đè những nội dung do Bob tạo.
Đây chính xác là loại tình huống mà hệ thống CM có thể kiểm soát. Có quản trị viên diễn đàn cả Bob và Susan đều "thanh toán" bản sao nội dung kỹ thuật của riêng họ và xử lý chúng theo cách thủ công. Khi Bob kiểm tra lại thay đổi của mình, hệ thống sẽ biết Susan đã tự mình thanh toán một bản sao. Khi Susan kiểm tra trong bản sao của mình, hệ thống phân tích những thay đổi mà cả Bob và Susan đã thực hiện và tạo một phiên bản mới hợp nhất hai nhóm thay đổi lại với nhau.
Hệ thống CM có một số tính năng ngoài việc quản lý những thay đổi đồng thời như mô tả ở trên. Nhiều hệ thống lưu trữ các bản lưu trữ của tất cả các phiên bản của một tài liệu, từ thời gian tạo bản dựng. Trong trường hợp hướng dẫn kỹ thuật, điều này có thể rất hữu ích khi người dùng sử dụng phiên bản hướng dẫn cũ và đặt câu hỏi cho người viết về công nghệ. Hệ thống CM sẽ cho phép người viết công nghệ truy cập vào phiên bản cũ và có thể để biết những gì người dùng đang nhìn thấy.
Hệ thống CM đặc biệt hữu ích trong việc kiểm soát các thay đổi được thực hiện đối với phần mềm. Chẳng hạn được gọi là hệ thống Quản lý cấu hình phần mềm (SCM). Nếu bạn cân nhắc số lượng lớn các tệp mã nguồn riêng lẻ trong một kỹ thuật phần mềm lớn tổ chức của mình và số lượng lớn kỹ sư phải thay đổi chúng, thì rõ ràng hệ thống SCM rất quan trọng.
Quản lý cấu hình phần mềm
Hệ thống SCM được xây dựng dựa trên một ý tưởng đơn giản: các bản sao chính thức của các tệp đều được lưu trữ trong kho lưu trữ trung tâm. Mọi người xem bản sao của các tệp trong kho lưu trữ, làm việc trên các bản sao đó, sau đó kiểm tra lại khi hoàn thành. SCM các hệ thống quản lý và theo dõi các bản sửa đổi do nhiều người thực hiện so với một trang chính thiết lập.
Tất cả hệ thống SCM đều cung cấp những tính năng thiết yếu sau đây:
- Quản lý đồng thời
- Lập phiên bản
- Đồng bộ hoá
Hãy cùng tìm hiểu kỹ hơn về từng tính năng này.
Quản lý đồng thời
Tính năng đồng thời là việc nhiều người chỉnh sửa cùng lúc một tệp. Với một kho lưu trữ lớn, chúng tôi muốn mọi người có thể làm việc này, nhưng nó có thể dẫn đến một số vấn đề.
Hãy xem xét một ví dụ đơn giản trong lĩnh vực kỹ thuật: Giả sử chúng ta cho phép các kỹ sư sửa đổi đồng thời cùng một tệp trong kho lưu trữ mã nguồn trung tâm. Cả Client1 và Client2 đều cần phải thực hiện các thay đổi đối với tệp cùng một lúc:
- Client1 mở bar.cpp.
- Client2 mở bar.cpp.
- Client1 thay đổi tệp và lưu tệp đó.
- Client2 thay đổi tệp và lưu tệp ghi đè lên các thay đổi của Client1.
Rõ ràng là chúng tôi không muốn điều này xảy ra. Ngay cả khi chúng tôi kiểm soát tình hình bằng để hai kỹ sư làm việc trên các bản sao riêng biệt thay vì trực tiếp trên một bản đặt (như trong hình minh hoạ bên dưới), các bản sao phải được điều chỉnh theo cách nào đó. Thường gặp nhất Hệ thống SCM xử lý vấn đề này bằng cách cho phép nhiều kỹ sư kiểm tra một tệp ("đồng bộ hoá" hoặc "cập nhật") và thực hiện thay đổi nếu cần. SCM sau đó chạy thuật toán để hợp nhất các thay đổi khi tệp được kiểm tra lại ("gửi" hoặc "cam kết") đến kho lưu trữ.
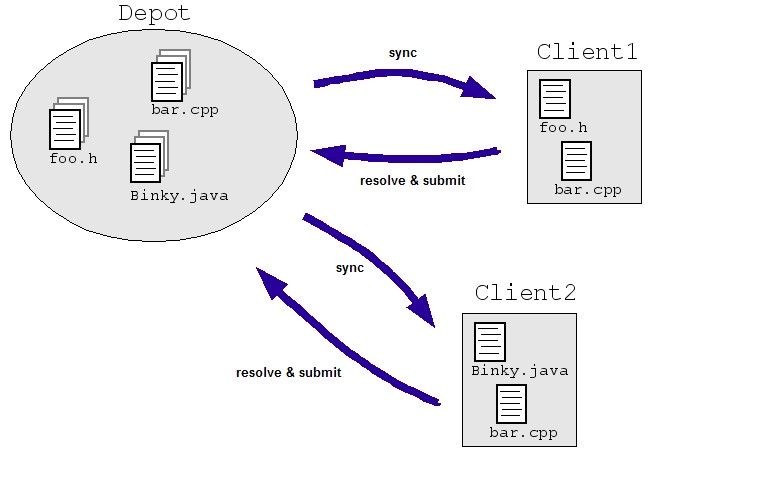
Những thuật toán này có thể đơn giản (hãy yêu cầu kỹ sư giải quyết những thay đổi gây mâu thuẫn) hoặc không quá đơn giản (xác định cách hợp nhất các thay đổi gây mâu thuẫn một cách thông minh và chỉ hỏi kỹ sư nếu hệ thống thực sự gặp sự cố).
Lập phiên bản
Tạo phiên bản nghĩa là theo dõi các bản sửa đổi tệp giúp bạn có thể tạo lại (hoặc khôi phục về) phiên bản trước của tệp. Thao tác này được thực hiện bằng một trong hai cách sau: bằng cách tạo bản sao lưu trữ của mọi tệp khi tệp đó được kiểm tra trong kho lưu trữ, hoặc bằng cách lưu mọi thay đổi đối với tệp. Bất cứ lúc nào, chúng tôi có thể sử dụng các kho lưu trữ hoặc thay đổi thông tin để tạo phiên bản trước đó. Hệ thống tạo phiên bản cũng có thể tạo báo cáo nhật ký về người đã đăng ký thay đổi, thời điểm họ được đăng ký và những gì thay đổi.
Đồng bộ hoá
Đối với một số hệ thống SCM, các tệp riêng lẻ sẽ được đăng nhập và rời khỏi kho lưu trữ. Các hệ thống mạnh mẽ hơn giúp bạn xem nhiều tệp cùng một lúc. Kỹ sư xem kho lưu trữ hoàn chỉnh, hoàn chỉnh, bản sao của kho lưu trữ (hoặc một phần trong đó) và công việc vào các tệp khi cần. Sau đó, họ xác nhận thay đổi quay lại kho lưu trữ chính định kỳ và cập nhật bản sao cá nhân của mình để luôn nắm bắt những thay đổi những người khác đã tạo ra. Quá trình này gọi là đồng bộ hoá hoặc cập nhật.
Phiên bản phụ
Subversion (SVN) là một hệ thống quản lý phiên bản nguồn mở. Nền tảng này có tất cả các tính năng được mô tả ở trên.
SVN áp dụng một phương pháp đơn giản khi xung đột xảy ra. Xung đột là khi hai một hoặc nhiều kỹ sư hơn thực hiện các thay đổi khác nhau đối với cùng một khu vực của cơ sở mã và sau đó cả hai gửi thay đổi. SVN chỉ thông báo cho các kỹ sư rằng có xung đột – việc giải quyết là tuỳ thuộc vào các kỹ sư.
Chúng tôi sẽ dùng SVN trong suốt khoá học này để giúp bạn làm quen với quản lý cấu hình. Những hệ thống như vậy rất phổ biến trong công nghiệp.
Bước đầu tiên là cài đặt SVN trên hệ thống của bạn. Nhấp chuột tại đây để . Tìm hệ điều hành của bạn và tải tệp nhị phân thích hợp xuống.
Một số thuật ngữ SVN
- Bản sửa đổi: Sự thay đổi về một tệp hoặc nhóm tệp. Bản sửa đổi là một "ảnh chụp nhanh" trong một dự án liên tục thay đổi.
- Kho lưu trữ: Bản sao chính nơi SVN lưu trữ toàn bộ nhật ký sửa đổi của dự án. Mỗi dự án có một kho lưu trữ.
- Bản sao làm việc: Bản sao trong đó kỹ sư thực hiện thay đổi đối với dự án. Có có thể là nhiều bản sao hoạt động của một dự án nhất định, mỗi bản đều do một kỹ sư sở hữu.
- Xem: Để yêu cầu một bản sao đang hoạt động từ kho lưu trữ. Một bản sao đang làm việc bằng với trạng thái của dự án khi được kiểm tra.
- Xác nhận: Gửi nội dung thay đổi từ bản sao đang hoạt động vào kho lưu trữ trung tâm. Còn gọi là đăng ký hoặc gửi.
- Thông tin cập nhật: Để đưa video của người khác các thay đổi từ kho lưu trữ thành bản sao làm việc của bạn, hoặc để cho biết bản sao làm việc của bạn có bất kỳ thay đổi nào chưa được cam kết hay không. Đây là giống như quá trình đồng bộ hoá, như được mô tả ở trên. Vì vậy, cập nhật/đồng bộ hoá mang đến bản sao làm việc của bạn được cập nhật với bản sao kho lưu trữ.
- Xung đột: Tình huống khi hai kỹ sư cố gắng thực hiện các thay đổi cho cùng một của một tệp. SVN cho thấy xung đột nhưng kỹ sư phải giải quyết xung đột.
- Thông điệp nhật ký: Nhận xét bạn đính kèm vào bản sửa đổi khi cam kết nhận xét đó mô tả các thay đổi của bạn. Nhật ký cung cấp bản tóm tắt về những gì đang diễn ra trong một dự án.
Bây giờ, sau khi bạn đã cài đặt SVN, chúng ta sẽ chạy qua một số lệnh cơ bản. Chiến lược phát hành đĩa đơn việc cần làm đầu tiên là thiết lập kho lưu trữ trong một thư mục được chỉ định. Sau đây là các lệnh:
$ svnadmin create /usr/local/svn/newrepos $ svn import mytree file:///usr/local/svn/newrepos/project -m "Initial import" Adding mytree/foo.c Adding mytree/bar.c Adding mytree/subdir Adding mytree/subdir/foobar.h Committed revision 1.
Lệnh nhập sẽ sao chép nội dung của thư mục mytree vào dự án thư mục trong kho lưu trữ. Chúng ta có thể xem thư mục trong kho lưu trữ bằng lệnhlist
$ svn list file:///usr/local/svn/newrepos/project bar.c foo.c subdir/
Việc nhập này không tạo ra một bản sao làm việc. Để thực hiện việc này, bạn cần sử dụng svn checkout. Thao tác này sẽ tạo một bản sao đang hoạt động của cây thư mục. Hãy làm điều đó ngay bây giờ:
$ svn checkout file:///usr/local/svn/newrepos/project A foo.c A bar.c A subdir A subdir/foobar.h … Checked out revision 215.
Giờ đây, khi đã có một bản sao đang hoạt động, bạn có thể thực hiện các thay đổi đối với các tệp và thư mục ở đó. Bản sao làm việc của bạn cũng giống như mọi tập hợp tệp và thư mục khác - các em có thể thêm mẫu mới hoặc chỉnh sửa, di chuyển chúng, thậm chí xoá toàn bộ nội dung đang làm việc. Xin lưu ý rằng nếu bạn sao chép và di chuyển tệp trong bản sao đang làm việc, điều quan trọng là sử dụng bản sao svn và di chuyển svn thay vì các lệnh của hệ điều hành. Để thêm tệp mới, hãy sử dụng svn add và để xóa một tệp hãy sử dụng svn delete. Nếu bạn chỉ muốn chỉnh sửa, chỉ cần mở với trình chỉnh sửa của bạn và chỉnh sửa ngay!
Có một số tên thư mục chuẩn thường được dùng với Subversion. "Thân cây" thư mục giữ dây chuyền phát triển chính cho dự án của bạn. Một "chi nhánh" thư mục có bất kỳ phiên bản nhánh nào mà bạn có thể đang xử lý.
$ svn list file:///usr/local/svn/repos /trunk /branches
Giả sử bạn đã thực hiện tất cả những thay đổi cần thiết đối với nội dung làm việc và mà bạn muốn đồng bộ hoá với kho lưu trữ. Nếu có nhiều kỹ sư khác làm việc trong phần này của kho lưu trữ, bạn cần phải cập nhật bản sao đang làm việc của mình. Bạn có thể sử dụng lệnh svn status để xem các thay đổi mà mình có đã thực hiện.
A subdir/new.h # file is scheduled for addition D subdir/old.c # file is scheduled for deletion M bar.c # the content in bar.c has local modifications
Lưu ý rằng có rất nhiều cờ trong lệnh trạng thái để kiểm soát đầu ra này. Nếu bạn muốn xem những thay đổi cụ thể trong tệp đã sửa đổi, hãy sử dụng svn diff.
$ svn diff bar.c
Index: bar.c
===================================================================
--- bar.c (revision 5)
+++ bar.c (working copy)
## -1,18 +1,19 ##
+#include
+#include
int main(void) {
- int temp_var;
+ int new_var;
...Cuối cùng, để cập nhật bản sao đang làm việc từ kho lưu trữ, hãy sử dụng lệnh svn update.
$ svn update U foo.c U bar.c G subdir/foobar.h C subdir/new.h Updated to revision 2.
Đây là nơi có thể xảy ra xung đột. Trong dữ liệu đầu ra ở trên, ký tự "U" cho biết không có thay đổi nào đối với phiên bản kho lưu trữ của những tệp này và bản cập nhật đã hoàn tất. Chữ "G" có nghĩa là đã xảy ra hợp nhất. Phiên bản kho lưu trữ có đã bị thay đổi, nhưng các thay đổi không xung đột với thay đổi của bạn. Chữ "C" cho biết xung đột. Điều này có nghĩa là những thay đổi từ kho lưu trữ chồng chéo với kho lưu trữ của bạn, và bây giờ bạn phải chọn giữa chúng.
Đối với mỗi tệp có xung đột, Subversion sẽ đặt ba tệp vào hoạt động của bạn nội dung:
- file.mine: Đây là tệp của bạn vì đã tồn tại trong bản sao làm việc của bạn trước khi bạn đã cập nhật bản sao làm việc của bạn.
- file.rOLDREV: Đây là tệp mà bạn đã đăng xuất khỏi kho lưu trữ trước khi thực hiện thay đổi của bạn.
- file.rNEWREV: Tệp này là phiên bản hiện tại trong kho lưu trữ.
Bạn có thể làm một trong ba việc sau để giải quyết xung đột:
- Xem qua các tệp và hợp nhất theo cách thủ công.
- Sao chép một trong các tệp tạm thời do SVN tạo qua phiên bản bản sao đang làm việc của bạn.
- Chạy svn huỷ để loại bỏ tất cả thay đổi của bạn.
Sau khi giải quyết xong xung đột, bạn thông báo cho SVN biết bằng cách chạy svn đã giải quyết. Thao tác này sẽ xoá 3 tệp tạm thời và SVN không còn xem tệp trong trạng thái xung đột.
Việc cuối cùng cần làm là chuyển phiên bản cuối cùng vào kho lưu trữ. Chiến dịch này được thực hiện bằng lệnh svn cam kết. Khi thực hiện thay đổi, bạn cần để cung cấp thông điệp nhật ký mô tả các thay đổi của bạn. Thông điệp nhật ký này được đính kèm đối với bản sửa đổi mà bạn tạo.
svn commit -m "Update files to include new headers."
Có rất nhiều điều cần tìm hiểu về SVN và cách SVN có thể hỗ trợ các phần mềm lớn dự án kỹ thuật. Có sẵn nhiều tài nguyên trên web, chỉ cần tìm kiếm "Subversion" trên Google.
Để thực hành, hãy tạo kho lưu trữ cho hệ thống Cơ sở dữ liệu Composer và nhập tất cả tệp của bạn. Sau đó, kiểm tra một bản sao đang hoạt động và thực hiện các lệnh được mô tả ở trên.
Tài liệu tham khảo
Bài viết trên Wikipedia về SVN
Ứng dụng: Nghiên cứu về giải phẫu
Khám phá eSkeletons của trường Đại học Texas tại Austin