Zamiast porównywać dane funkcji połączone ręcznie, możesz zredukować dane funkcji do reprezentacji zwanych embeddingami, a następnie porównać te embeddingi. Wpisy są generowane przez trenowanie nadzorowane głębokiej sieci neuronowej (DNN) na danych funkcji. Wektory te mapują dane cech na wektor w przestrzeni osadzania, która ma zwykle mniej wymiarów niż dane cech. Wprowadzenie do uczenia maszynowego omawiają moduły dotyczące uczenia maszynowego, a sieci neuronowe – moduły dotyczące sieci neuronowych. Wektory umieszczania w przypadku podobnych przykładów, np. filmów w YouTube na podobne tematy oglądanych przez tych samych użytkowników, znajdują się blisko siebie w przestrzeni umieszczania. Kontrolowana miara podobieństwa używa tej „odległości” do ilościowego określenia podobieństwa par przykładów.
Pamiętaj, że omawiamy uczenie nadzorowane tylko po to, aby utworzyć miarę podobieństwa. Wynik pomiaru podobieństwa (ręczny lub nadzorowany) jest następnie wykorzystywany przez algorytm do nienadzorowanego grupowania.
Porównanie pomiarów ręcznych i nadzorowanych
Z tabeli dowiesz się, kiedy używać ręcznego lub nadzorowanego pomiaru podobieństwa, w zależności od wymagań.
| Wymaganie | Ręcznie | Nadzorowane |
|---|---|---|
| eliminuje zbędne informacje w skorelowanych cechach; | Nie. Musisz sprawdzić, czy występują korelacje między funkcjami. | Tak, DNN usuwa zbędne informacje. |
| Czy zawiera informacje o obliczonych podobieństwach? | Tak | Nie, nie można ich rozszyfrować. |
| Czy nadaje się do małych zbiorów danych z niewielką liczbą cech? | Tak. | Nie. Małe zbiory danych nie zapewniają wystarczającej ilości danych szkoleniowych dla DNN. |
| Czy ta metoda jest odpowiednia dla dużych zbiorów danych z wiele cechami? | Nie. Ręczne usuwanie zbędących informacji z wielu funkcji i ich późniejsze łączenie jest bardzo trudne. | Tak, sieć neuronowa usuwa automatycznie nadmiarowe informacje i łączy funkcje. |
Tworzenie nadzorowanego miary podobieństwa
Oto omówienie procesu tworzenia nadzorowanej miary podobieństwa:

Ta strona dotyczy DNN, a na kolejnych znajdziesz pozostałe instrukcje.
Wybieranie DNN na podstawie etykiet trenowania
Zredukuj dane cech do niskowymiarowych wektorów, trenując sieć DNN, która używa tych samych danych cech zarówno jako danych wejściowych, jak i etykiet. Na przykład w przypadku danych o domach DNN używałby cech takich jak cena, wielkość czy kod pocztowy, aby przewidywać te same cechy.
Autoencoder
Sieć DNN, która uczy się osadzania danych wejściowych przez przewidywanie samych danych wejściowych, nazywana jest autoenkoderem. Ponieważ warstwy ukryte autoencodera są mniejsze niż warstwy wejściowe i wyjściowe, autoencoder jest zmuszony do nauczenia się skompresowanej reprezentacji danych funkcji wejściowych. Po wytrenowaniu sieci DNN wyodrębnij wglądy z najmniejszej warstwy ukrytej, aby obliczyć podobieństwo.
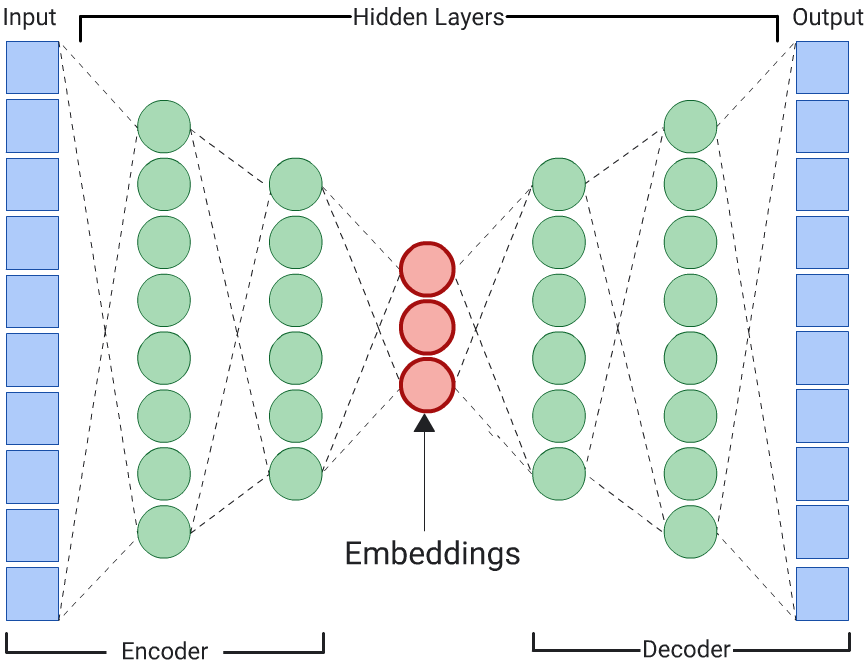
Współczynnik
Autoencoder to najprostszy sposób na wygenerowanie wektorów. Autoencoder nie jest jednak optymalnym wyborem, gdy niektóre cechy mogą być ważniejsze niż inne w określaniu podobieństwa. Na przykład w danych własnych załóż, że cena jest ważniejsza niż kod pocztowy. W takich przypadkach użyj jako etykiety treningowej tylko ważnej cechy. Ponieważ ten DNN przewiduje konkretną cechę wejściową, a nie wszystkie cechy wejściowe, nazywa się go przewidywaczem. Elementy do wklejenia powinny być zwykle wyodrębniane z ostatniej warstwy wklejenia.
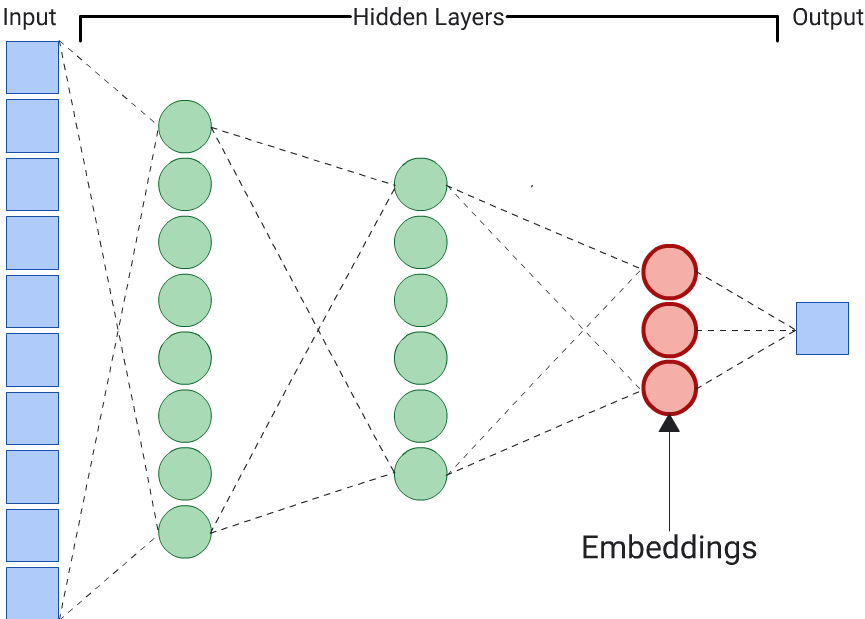
Wybierając funkcję, która ma być etykietą:
Zamiast cech kategorialnych lepiej używać cech numerycznych, ponieważ straty są w przypadku cech numerycznych łatwiejsze do obliczenia i zinterpretowania.
Usuń z wejścia do DNN cechę, której używasz jako etykiety, w przeciwnym razie DNN będzie używać tej cechy do idealnego przewidywania wartości wyjściowej. (to skrajny przykład przecieku etykiety).
W zależności od wybranych etykiet uzyskany DNN będzie albo autoenkoderem, albo predyktorem.