Em vez de comparar dados de recursos combinados manualmente, você pode reduzir os dados de recursos a representações chamadas de embeddings e, em seguida, comparar os embeddings. As incorporações são geradas treinando uma rede neural profunda (DNN, na sigla em inglês) supervisionada nos dados de atributos. Os embeddings mapeiam os dados de atributos para um vetor em um espaço de embedding com, normalmente, menos dimensões do que os dados de atributos. Os embeddings são discutidos no módulo Embeddings do curso intensivo de machine learning, enquanto as redes neurais são discutidas no módulo Redes neurais. Os vetores de embedding para exemplos semelhantes, como vídeos do YouTube sobre tópicos semelhantes assistidos pelos mesmos usuários, ficam próximos no espaço de embedding. Uma medida de semelhança supervisionada usa essa "proximidade" para quantificar a semelhança de pares de exemplos.
Lembre-se de que estamos discutindo o aprendizado supervisionado apenas para criar nossa medida de semelhança. A medida de similaridade, manual ou supervisionada, é usada por um algoritmo para realizar o agrupamento não supervisionado.
Comparação entre medidas manuais e supervisionadas
Esta tabela descreve quando usar uma medida de similaridade manual ou supervisionada, dependendo dos seus requisitos.
| Requisito | Manual | Supervisionado |
|---|---|---|
| Elimina informações redundantes em recursos correlacionados? | Não, você precisa investigar as correlações entre os recursos. | Sim, o DNN elimina informações redundantes. |
| Fornece insights sobre as semelhanças calculadas? | Sim | Não, as incorporações não podem ser decifradas. |
| É adequado para conjuntos de dados pequenos com poucos recursos? | Sim. | Não, conjuntos de dados pequenos não fornecem dados de treinamento suficientes para uma DNN. |
| Adequado para grandes conjuntos de dados com muitos recursos? | Não, eliminar manualmente informações redundantes de vários recursos e combiná-los é muito difícil. | Sim, o DNN elimina automaticamente informações redundantes e combina recursos. |
Como criar uma medida de similaridade supervisionada
Confira uma visão geral do processo para criar uma medida de similaridade supervisionada:

Esta página aborda as DNNs, e as páginas a seguir abordam as etapas restantes.
Escolher DNN com base em rótulos de treinamento
Reduza os dados de atributos para embeddings de menor dimensão treinando um DNN que use os mesmos dados de atributos como entrada e como rótulos. Por exemplo, no caso de dados de casas, a DNN usaria os atributos, como preço, tamanho e CEP, para prever esses atributos.
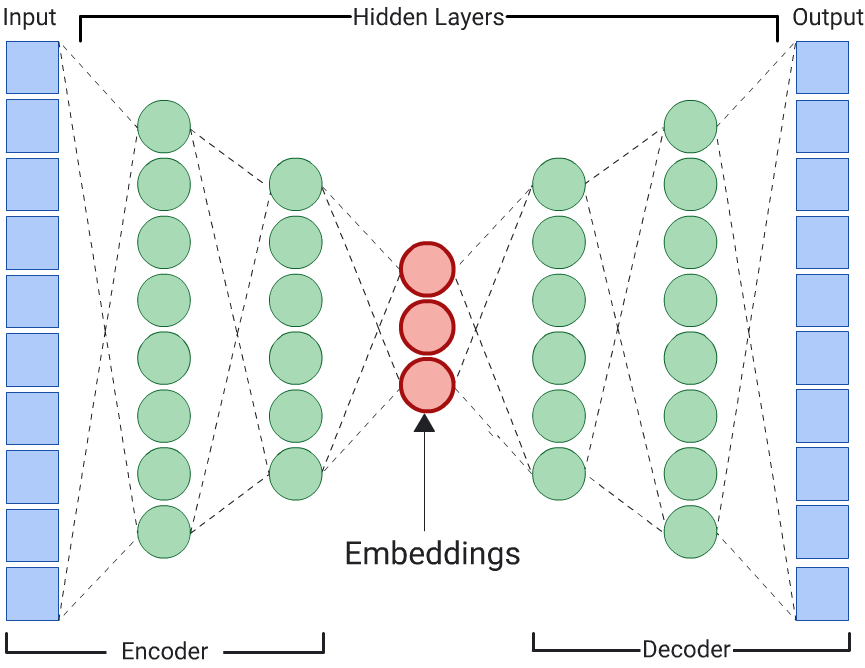
Codificador automático
Um DNN que aprende embeddings de dados de entrada prevendo os próprios dados de entrada é chamado de autoencoder. Como as camadas ocultas de um autoencoder são menores do que as camadas de entrada e saída, o autoencoder é forçado a aprender uma representação compactada dos dados de recursos de entrada. Depois que o DNN for treinado, extraia as embeddings da menor camada oculta para calcular a semelhança.
Previsões
Um autoencoder é a opção mais simples para gerar embeddings. No entanto, um autoencoder não é a escolha ideal quando determinados recursos podem ser mais importantes do que outros na determinação da semelhança. Por exemplo, nos dados internos, suponha que o preço seja mais importante do que o CEP. Nesses casos, use apenas o atributo importante como o rótulo de treinamento para a DNN. Como esse DNN prevê um atributo de entrada específico em vez de todos os atributos de entrada, ele é chamado de DNN de previsão. As incorporação geralmente precisam ser extraídas da última camada de incorporação.
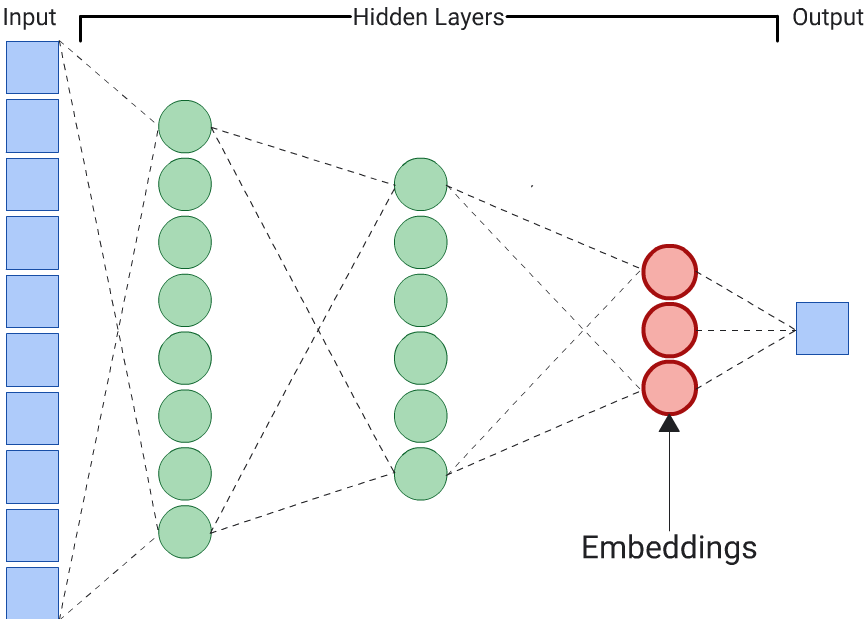
Ao escolher um recurso para ser o rótulo:
Prefira recursos categóricos a numéricos, porque a perda é mais fácil de calcular e interpretar em recursos numéricos.
Remova o atributo usado como rótulo da entrada para a DNN. Caso contrário, ela vai usar esse atributo para prever perfeitamente a saída. Esse é um exemplo extremo de vazamento de rótulo.
Dependendo da escolha de rótulos, o DNN resultante é um autoencoder ou um preditor.