AI-generated Key Takeaways
-
Supervised similarity measures leverage deep neural networks (DNNs) to learn embeddings, which are lower-dimensional representations of feature data, for comparing items like YouTube videos.
-
Unlike manual similarity measures, supervised measures excel with large datasets and automatically handle redundant information, but they lack the interpretability of manual methods.
-
To create a supervised similarity measure, you train a DNN (either an autoencoder predicting its own input or a predictor focusing on key features) to generate embeddings that capture item similarity.
-
When designing the DNN, prioritize numerical features as labels and avoid label leakage by removing the label feature from the input data.
-
Embeddings from similar items will be clustered closer together in the embedding space, allowing for similarity comparisons using distance-based metrics.
Instead of comparing manually-combined feature data, you can reduce the feature data to representations called embeddings, then compare the embeddings. Embeddings are generated by training a supervised deep neural network (DNN) on the feature data itself. The embeddings map the feature data to a vector in an embedding space with typically fewer dimensions than the feature data. Embeddings are discussed in the Embeddings module of Machine Learning Crash Course, while neural nets are discussed in the Neural nets module. Embedding vectors for similar examples, such as YouTube videos on similar topics watched by the same users, end up close together in the embedding space. A supervised similarity measure uses this "closeness" to quantify the similarity for pairs of examples.
Remember, we're discussing supervised learning only to create our similarity measure. The similarity measure, whether manual or supervised, is then used by an algorithm to perform unsupervised clustering.
Comparison of Manual and Supervised Measures
This table describes when to use a manual or supervised similarity measure depending on your requirements.
| Requirement | Manual | Supervised |
|---|---|---|
| Eliminates redundant information in correlated features? | No, you need to investigate any correlations between features. | Yes, DNN eliminates redundant information. |
| Gives insight into calculated similarities? | Yes | No, embeddings cannot be deciphered. |
| Suitable for small datasets with few features? | Yes. | No, small datasets don't provide enough training data for a DNN. |
| Suitable for large datasets with many features? | No, manually eliminating redundant information from multiple features and then combining them is very difficult. | Yes, the DNN automatically eliminates redundant information and combines features. |
Creating a supervised similarity measure
Here's an overview of the process to create a supervised similarity measure:

This page discusses DNNs, while the following pages cover the remaining steps.
Choose DNN based on training labels
Reduce your feature data to lower-dimensional embeddings by training a DNN that uses the same feature data both as input and as the labels. For example, in the case of house data, the DNN would use the features—such as price, size, and postal code—to predict those features themselves.
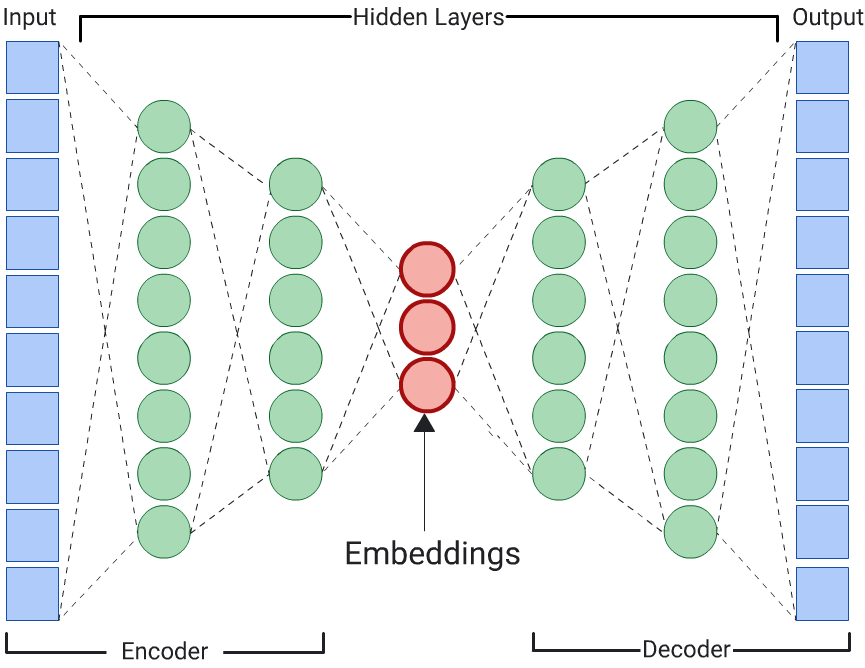
Autoencoder
A DNN that learns embeddings of input data by predicting the input data itself is called an autoencoder. Because an autoencoder's hidden layers are smaller than the input and output layers, the autoencoder is forced to learn a compressed representation of the input feature data. Once the DNN is trained, extract the embeddings from the smallest hidden layer to calculate similarity.
Predictor
An autoencoder is the simplest choice to generate embeddings. However, an autoencoder isn't the optimal choice when certain features could be more important than others in determining similarity. For example, in house data, assume price is more important than postal code. In such cases, use only the important feature as the training label for the DNN. Since this DNN predicts a specific input feature instead of predicting all input features, it is called a predictor DNN. Embeddings should usually be extracted from the last embedding layer.
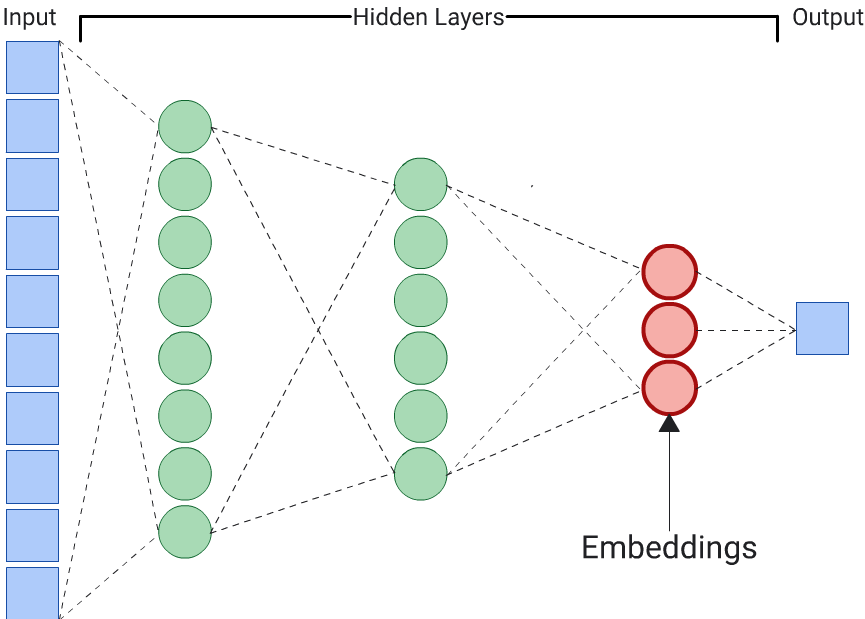
When choosing a feature to be the label:
Prefer numerical to categorical features because loss is easier to calculate and interpret for numeric features.
Remove the feature that you use as the label from the input to the DNN, or else the DNN will use that feature to perfectly predict the output. (This is an extreme example of label leakage.)
Depending on your choice of labels, the resulting DNN is either an autoencoder or a predictor.