Au lieu de comparer des données d'éléments géographiques combinées manuellement, vous pouvez réduire les données d'éléments géographiques à des représentations appelées embeddings, puis comparer les embeddings. Les représentations vectorielles continues sont générées en entraînant un réseau de neurones profonds (DNN) supervisé sur les données de caractéristiques elles-mêmes. Les embeddings mappent les données de fonctionnalités à un vecteur dans un espace d'embedding qui compte généralement moins de dimensions que les données de fonctionnalités. Les représentations vectorielles continues sont abordées dans le module Représentations vectorielles continues du cours d'initiation au machine learning, tandis que les réseaux de neurones sont abordés dans le module Réseaux de neurones. Les vecteurs d'embedding pour des exemples similaires, tels que des vidéos YouTube sur des sujets similaires regardées par les mêmes utilisateurs, se retrouvent proches les uns des autres dans l'espace d'embedding. Une mesure de similarité supervisée utilise cette "proximité" pour quantifier la similarité pour des paires d'exemples.
N'oubliez pas que nous ne parlons de l'apprentissage supervisé que pour créer notre mesure de similarité. La mesure de similarité, qu'elle soit manuelle ou supervisée, est ensuite utilisée par un algorithme pour effectuer un clustering non supervisé.
Comparaison des mesures manuelles et supervisées
Ce tableau décrit quand utiliser une mesure de similarité manuelle ou supervisée en fonction de vos exigences.
| Exigence | Manuel | Supervisé |
|---|---|---|
| élimine les informations redondantes dans les fonctionnalités corrélées ? | Non, vous devez examiner les corrélations entre les caractéristiques. | Oui, le DNN élimine les informations redondantes. |
| Fournit des insights sur les similitudes calculées ? | Oui | Non, les représentations vectorielles continues ne peuvent pas être déchiffrées. |
| Convient-il aux petits ensembles de données comportant peu de fonctionnalités ? | Oui. | Non, les petits ensembles de données ne fournissent pas suffisamment de données d'entraînement pour un RNN. |
| Convient-il aux grands ensembles de données comportant de nombreuses fonctionnalités ? | Non, il est très difficile d'éliminer manuellement les informations redondantes de plusieurs éléments géographiques, puis de les combiner. | Oui, le DNN élimine automatiquement les informations redondantes et combine les fonctionnalités. |
Créer une mesure de similarité supervisée
Voici un aperçu du processus de création d'une mesure de similarité supervisée:

Cette page traite des réseaux de neurones profonds, tandis que les pages suivantes couvrent les étapes restantes.
Choisir un RNN en fonction des libellés d'entraînement
Réduisez vos données de caractéristiques à des représentations vectorielles continues à faible dimension en entraînant un DNN qui utilise les mêmes données de caractéristiques à la fois en entrée et en tant qu'étiquettes. Par exemple, dans le cas de données sur des maisons, le DNN utiliserait les caractéristiques (telles que le prix, la taille et le code postal) pour prédire ces caractéristiques elles-mêmes.
Auto-encodeur
Un RNN qui apprend des représentations vectorielles continues des données d'entrée en prédisant les données d'entrée elles-mêmes est appelé autoencodeur. Étant donné que les couches cachées d'un autoencodeur sont plus petites que les couches d'entrée et de sortie, l'autoencodeur est obligé d'apprendre une représentation compressée des données de caractéristiques d'entrée. Une fois le RNN entraîné, extrayez les représentations vectorielles continues de la plus petite couche cachée pour calculer la similarité.
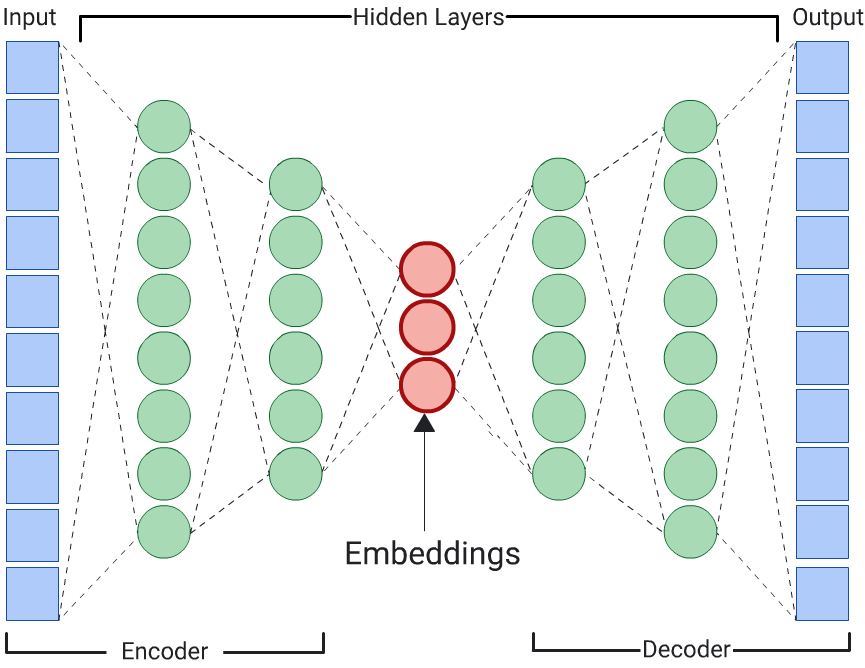
Prédicteur
Un autoencodeur est le choix le plus simple pour générer des représentations vectorielles continues. Toutefois, un autoencodeur n'est pas le choix optimal lorsque certaines caractéristiques peuvent être plus importantes que d'autres pour déterminer la similarité. Par exemple, dans les données sur les maisons, supposons que le prix soit plus important que le code postal. Dans ce cas, n'utilisez que la caractéristique importante comme étiquette d'entraînement pour le RNN. Étant donné que ce RNN prédit une caractéristique d'entrée spécifique au lieu de toutes les caractéristiques d'entrée, il est appelé RNN prédicteur. Les représentations vectorielles continues doivent généralement être extraites de la dernière couche d'embedding.
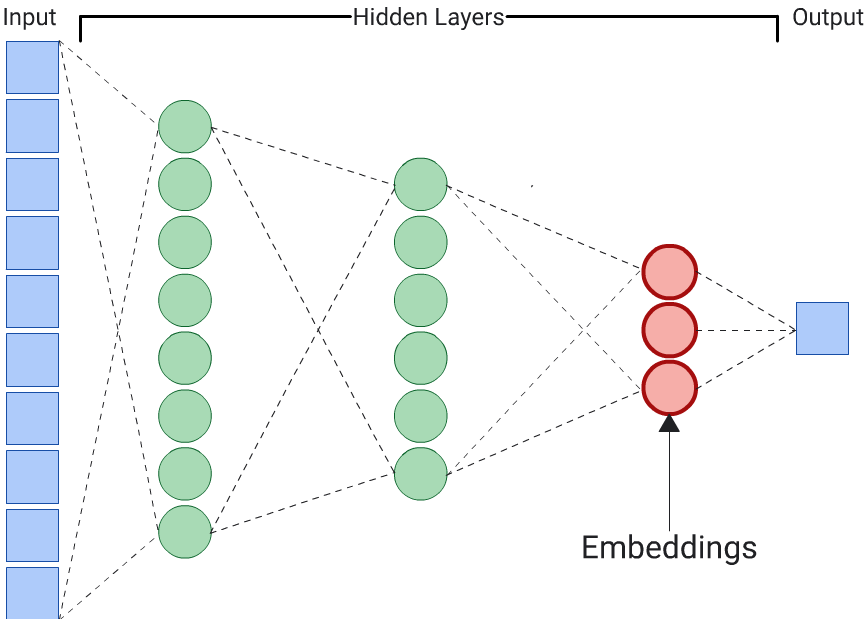
Lorsque vous choisissez une fonctionnalité pour le libellé:
Privilégiez les caractéristiques numériques aux caractéristiques catégorielles, car la perte est plus facile à calculer et à interpréter pour les caractéristiques numériques.
Supprimez la caractéristique que vous utilisez comme libellé de l'entrée du DNN, sinon il l'utilisera pour prédire parfaitement la sortie. (Il s'agit d'un exemple extrême de fuite de libellé.)
Selon votre choix de libellés, le RNN obtenu est un autoencodeur ou un prédicteur.