您可以将特征数据简化为称为嵌入的表示法,然后比较嵌入,而不是比较手动组合的特征数据。嵌入是通过对特征数据本身训练监督式深度神经网络 (DNN) 生成的。嵌入会将特征数据映射到嵌入空间中的向量,该向量的维度通常比特征数据少。机器学习速成课程的嵌入模块介绍了嵌入,神经网络模块介绍了神经网络。类似示例(例如由同一用户观看的关于类似主题的 YouTube 视频)的嵌入向量最终会在嵌入空间中彼此接近。监督式相似度衡量使用这种“接近度”来量化一对示例的相似度。
请注意,我们讨论监督学习只是为了创建相似度衡量标准。然后,算法会使用相似度衡量方法(无论是手动还是监督方法)执行无监督聚类。
手动和监督措施的比较
下表介绍了何时应根据您的要求使用手动或监督式相似度衡量方法。
| 要求 | 手动 | 受监管 |
|---|---|---|
| 消除相关特征中的冗余信息? | 不可以,您需要调查特征之间的任何相关性。 | 是,DNN 会消除冗余信息。 |
| 深入了解计算出的相似度 | 是 | 不可以,无法解密嵌入。 |
| 适合特征较少的小型数据集? | 是。 | 不可以,小型数据集无法为 DNN 提供足够的训练数据。 |
| 适用于包含许多特征的大型数据集吗? | 不可以,手动从多个地图项中消除冗余信息,然后将其合并起来非常困难。 | 是的,DNN 会自动消除冗余信息并组合特征。 |
创建监督式相似度衡量方法
以下是创建监督式相似度衡量标准的过程概览:

本页介绍了 DNN,而以下页面介绍了其余步骤。
根据训练标签选择 DNN
通过训练一个将相同的特征数据用作输入和标签的 DNN,将特征数据降维为低维嵌入。例如,在房屋数据的情况下,DNN 会使用价格、面积和邮政编码等特征来预测这些特征本身。
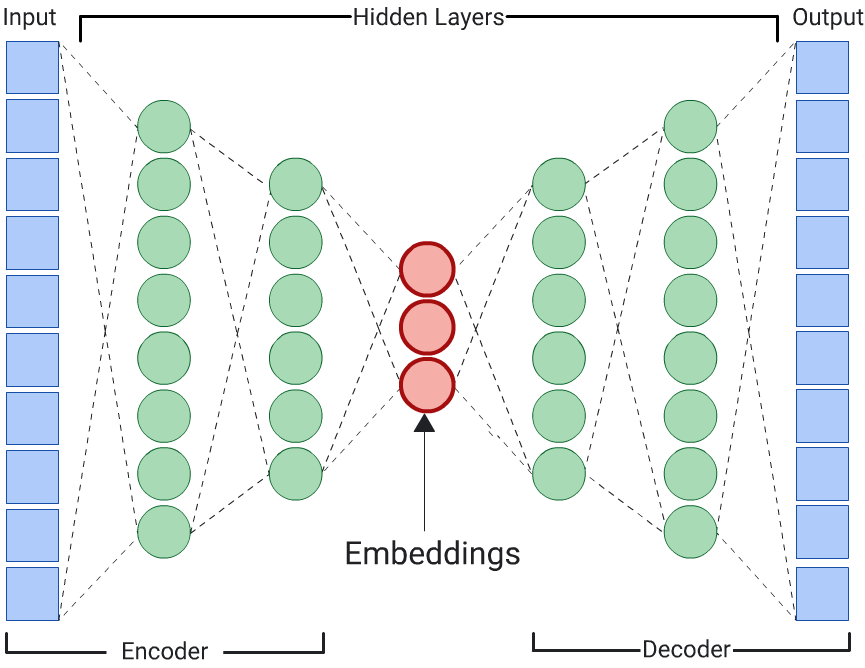
自动编码器
通过预测输入数据本身来学习输入数据的嵌入的 DNN 称为自动编码器。由于自动编码器的隐藏层小于输入层和输出层,因此自动编码器被迫学习输入特征数据的压缩表示法。训练完 DNN 后,从最小的隐藏层中提取嵌入来计算相似性。
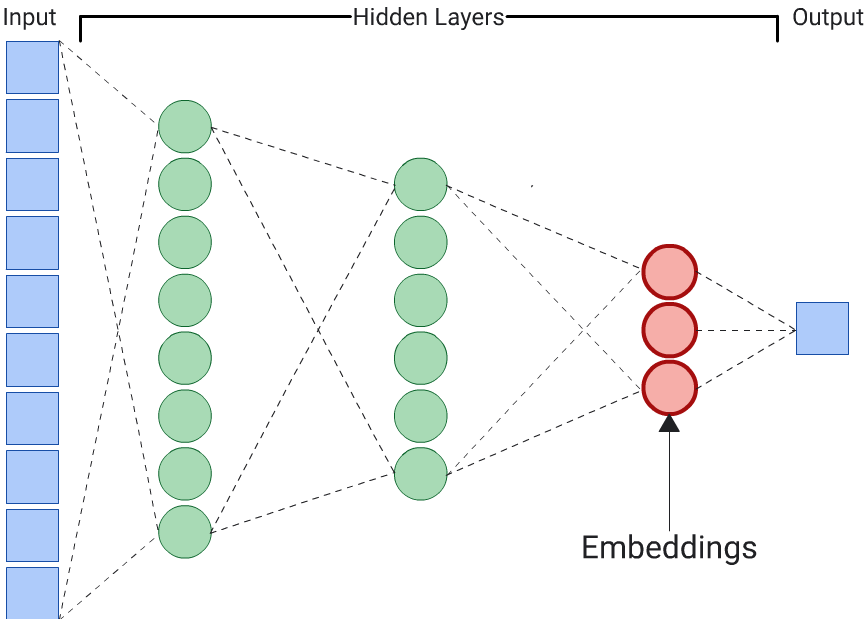
预测器
自动编码器是生成嵌入的一种简单方法。不过,如果某些特征在确定相似性方面比其他特征更重要,则自动编码器不是最佳选择。例如,在房屋数据中,假设价格比邮政编码更重要。在这种情况下,请仅将重要特征用作 DNN 的训练标签。由于此 DNN 预测的是特定输入特征,而不是预测所有输入特征,因此被称为预测器 DNN。通常应从最后一个嵌入层中提取嵌入。
选择要用作标签的功能时,请注意以下事项:
优先使用数值特征,而不是分类特征,因为对于数值特征,损失更容易计算和解读。
从 DNN 的输入中移除您用作标签的特征,否则 DNN 将使用该特征来完美预测输出。(这是标签泄露的极端示例。)
生成的 DNN 是自编码器还是预测器,取决于您选择的标签。