您可以將特徵資料縮減為稱為嵌入資料的表示法,然後比較嵌入資料,而非比較手動合併的特徵資料。嵌入資料是透過在特徵資料上訓練監督式深層類神經網路 (DNN) 產生的。嵌入會將特徵資料對應至嵌入空間中的向量,而向量通常比特徵資料的維度少。在「機器學習速成課程」的嵌入單元中,我們會討論嵌入,而「類神經網路」單元則會討論類神經網路。相似範例的嵌入向量 (例如同一位使用者觀看的類似主題 YouTube 影片) 最終會在嵌入空間中靠近。監督相似度評估會使用這個「相似度」來量化兩個範例的相似度。
請注意,我們討論監督式學習的目的,只是為了建立相似度評估指標。演算法會使用相似度評估值 (無論是手動或監督),執行無監督的叢集分析。
手動和監督評估方式的比較
下表說明根據需求使用手動或監督相似度評估方式的時機。
| 規定 | 手動 | 監督式 |
|---|---|---|
| 是否可消除相關特徵中的多餘資訊? | 否,您需要調查特徵之間的任何相關性。 | 是,DNN 會移除重複的資訊。 |
| 是否提供計算相似度的洞察資料? | 是 | 不行,無法解讀嵌入資料。 |
| 是否適合用於只有少數特徵的小型資料集? | 是。 | 否,小型資料集無法提供足夠的訓練資料來訓練 DNN。 |
| 是否適合用於包含大量特徵的大型資料集? | 否,手動從多個地圖項目中移除重複資訊,然後再將這些項目合併,是非常困難的作業。 | 是的,DNN 會自動移除多餘的資訊,並結合功能。 |
建立受監督的相似度評估
以下簡要說明建立受控相似度評估的程序:

本頁會說明 DNN,而後續頁面則會介紹其他步驟。
根據訓練標籤選擇 DNN
訓練 DNN 時,請使用相同的特徵資料做為輸入和標籤,將特徵資料縮減為低維度嵌入資料。舉例來說,在房屋資料的情況下,DNN 會使用價格、大小和郵遞區號等特徵,預測這些特徵本身。
自動編碼器
透過預測輸入資料本身,學習輸入資料嵌入資料的 DNN,稱為自編碼器。由於自編碼器的隱藏層比輸入和輸出層小,因此自編碼器會被迫學習輸入特徵資料的壓縮表示法。訓練 DNN 後,請從最小的隱藏層中擷取嵌入資料,以便計算相似度。

預測器
自動編碼器是產生嵌入資料最簡單的選擇。不過,如果在判斷相似度時,某些特徵比其他特徵更重要,那麼自動編碼器就不是最佳選擇。舉例來說,假設在房屋資料中,價格比郵遞區號更重要。在這種情況下,請只使用重要特徵做為 DNN 的訓練標籤。由於這個 DNN 會預測特定輸入特徵,而非所有輸入特徵,因此稱為「預測器」 DNN。通常應從最後一個嵌入層中擷取嵌入內容。
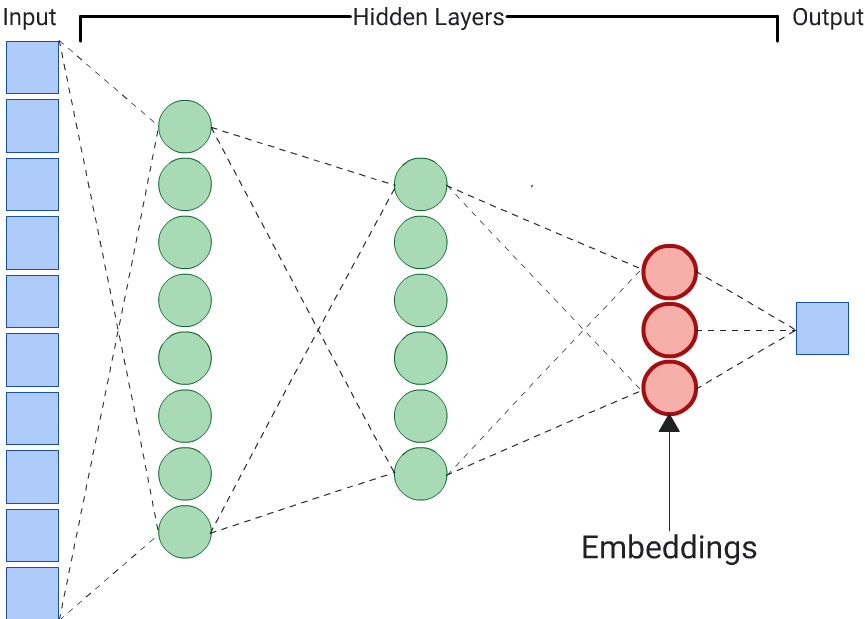
選擇標籤時,請注意下列事項:
請優先使用數值特徵,而非類別特徵,因為數值特徵的損失更容易計算及解讀。
請從 DNN 輸入中移除用來做為標籤的特徵,否則 DNN 會使用該特徵來完美預測輸出內容。(這是標籤外洩的極端例子)。
根據您選擇的標籤,產生的 DNN 可能是自編碼器或預測器。