Anstatt manuell kombinierte Feature-Daten zu vergleichen, können Sie die Feature-Daten auf Darstellungen reduzieren, die als Embeddings bezeichnet werden, und dann die Embeddings vergleichen. Embeddings werden generiert, indem ein überwachtes neuronales Deep-Learning-Netzwerk (DNN) mit den Feature-Daten selbst trainiert wird. Die Einbettungen ordnen die Feature-Daten einem Vektor in einem Einbettungsraum zu, der in der Regel weniger Dimensionen als die Feature-Daten hat. Einbettungen werden im Modul Embeddings des Crashkurses zu maschinellem Lernen behandelt, während neuronale Netze im Modul Neuronale Netze besprochen werden. Einbettungsvektoren für ähnliche Beispiele, z. B. YouTube-Videos zu ähnlichen Themen, die von denselben Nutzern angesehen wurden, liegen im Einbettungsraum nahe beieinander. Bei einem überwachten Ähnlichkeitsmaß wird diese „Nähe“ verwendet, um die Ähnlichkeit für Beispielpaare zu quantifizieren.
Denken Sie daran, dass wir Supervised Learning nur zum Erstellen unseres Ähnlichkeitsmaßes besprechen. Das Ähnlichkeitsmaß, ob manuell oder beaufsichtigt, wird dann von einem Algorithmus für die unbeaufsichtigte Clusterung verwendet.
Vergleich von manuellen und überwachten Maßnahmen
In dieser Tabelle wird beschrieben, wann Sie je nach Ihren Anforderungen eine manuelle oder eine überwachte Ähnlichkeitsmessung verwenden sollten.
| Anforderung | Manuell | Überwacht |
|---|---|---|
| Werden redundante Informationen in korrelierten Funktionen eliminiert? | Nein, Sie müssen alle Korrelationen zwischen den Merkmalen untersuchen. | Ja, DNN eliminiert redundante Informationen. |
| Gibt Aufschluss über berechnete Ähnlichkeiten? | Ja | Nein, Einbettungen können nicht entschlüsselt werden. |
| Geeignet für kleine Datensätze mit wenigen Funktionen? | Ja. | Nein. Kleine Datensätze bieten nicht genügend Trainingsdaten für ein DNN. |
| Geeignet für große Datensätze mit vielen Funktionen? | Nein. Es ist sehr schwierig, redundante Informationen aus mehreren Funktionen manuell zu entfernen und dann zu kombinieren. | Ja, die DNN eliminiert automatisch redundante Informationen und kombiniert Funktionen. |
Ähnlichkeitsmaß mit beaufsichtigtem Lernen erstellen
Hier finden Sie eine Übersicht über die Schritte zum Erstellen eines überwachten Ähnlichkeitsmaßes:

Auf dieser Seite werden DNNs behandelt, auf den folgenden Seiten die verbleibenden Schritte.
DNN basierend auf Trainingslabels auswählen
Reduzieren Sie Ihre Feature-Daten auf niedrigere Dimensions-Ebenen, indem Sie ein DNN trainieren, das dieselben Feature-Daten sowohl als Eingabe als auch als Labels verwendet. Bei Immobiliendaten würde das DNN beispielsweise die Merkmale wie Preis, Größe und Postleitzahl verwenden, um diese Merkmale selbst vorherzusagen.
Autoencoder
Ein DNN, das Einbettungen von Eingabedaten lernt, indem es die Eingabedaten selbst vorhersagt, wird als Autoencoder bezeichnet. Da die verborgenen Schichten eines Autoencoders kleiner sind als die Eingabe- und Ausgabeschichten, muss der Autoencoder eine komprimierte Darstellung der Eingabe-Feature-Daten lernen. Sobald das DNN trainiert ist, werden die Einbettungen aus der kleinsten verborgenen Schicht extrahiert, um die Ähnlichkeit zu berechnen.
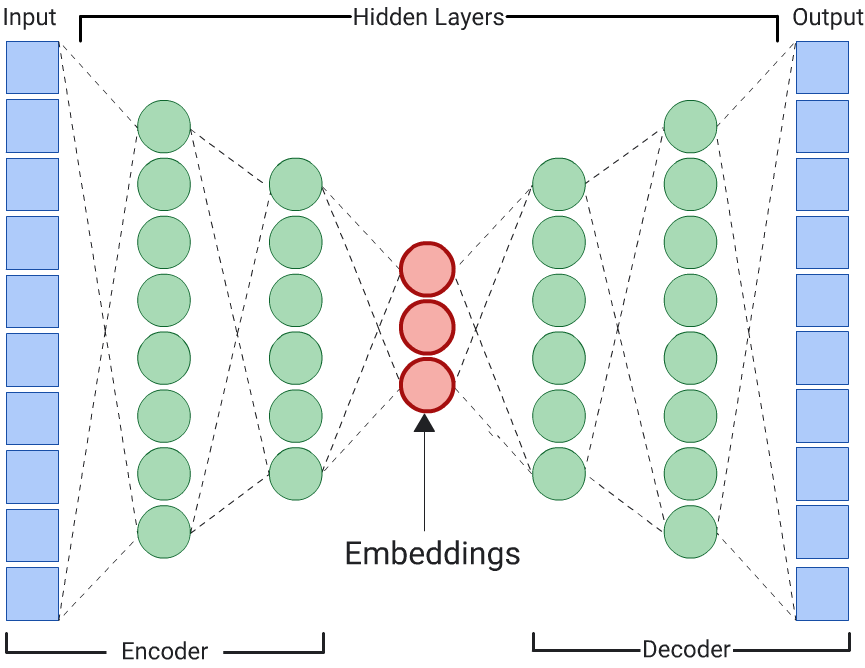
Prädiktor
Ein Autoencoder ist die einfachste Möglichkeit, Einbettungen zu generieren. Ein Autoencoder ist jedoch nicht die optimale Wahl, wenn bestimmte Merkmale bei der Bestimmung der Ähnlichkeit wichtiger sein könnten als andere. Angenommen, bei Immobiliendaten ist der Preis wichtiger als die Postleitzahl. Verwenden Sie in solchen Fällen nur das wichtige Merkmal als Trainingslabel für die DNN. Da diese DNN ein bestimmtes Eingabemerkmal vorhersagt, anstatt alle Eingabemerkmale vorherzusagen, wird sie als Vorhersage-DNN bezeichnet. Einbettungen sollten in der Regel aus der letzten Einbettungsschicht extrahiert werden.
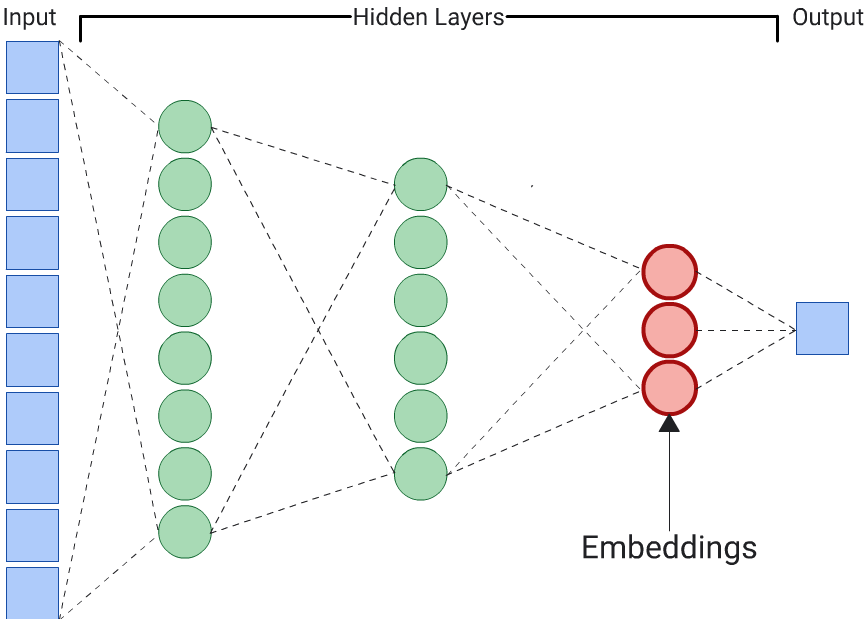
Beachten Sie Folgendes, wenn Sie eine Funktion als Label auswählen:
Verwenden Sie vorzugsweise numerische statt kategorische Features, da sich der Verlust bei numerischen Features leichter berechnen und interpretieren lässt.
Entfernen Sie das Merkmal, das Sie als Label verwenden, aus der Eingabe für die DNN. Andernfalls verwendet die DNN dieses Merkmal, um die Ausgabe perfekt vorherzusagen. (Dies ist ein extremes Beispiel für Labellecks.)
Je nach Auswahl der Labels ist die resultierende DNN entweder ein Autoencoder oder ein Prädiktor.