मैन्युअल तरीके से जोड़े गए फ़ीचर डेटा की तुलना करने के बजाय, फ़ीचर डेटा को एम्बेड नाम के रिप्रज़ेंटेशन में बदला जा सकता है. इसके बाद, एम्बेड की तुलना की जा सकती है. एम्बेडिंग, फ़ीचर डेटा पर निगरानी में रखे गए डीप नेटल नेटवर्क (DNN) को ट्रेनिंग देकर जनरेट किए जाते हैं. एम्बेडिंग, एम्बेडिंग स्पेस में फ़ीचर डेटा को वेक्टर पर मैप करते हैं. आम तौर पर, एम्बेडिंग स्पेस में फ़ीचर डेटा के मुकाबले कम डाइमेंशन होते हैं. एम्बेडिंग के बारे में, मशीन लर्निंग क्रैश कोर्स के एम्बेडिंग मॉड्यूल में बताया गया है. वहीं, न्यूरल नेटवर्क के बारे में न्यूरल नेटवर्क मॉड्यूल में बताया गया है. मिलते-जुलते उदाहरणों के लिए वेक्टर एम्बेड करने पर, वे एम्बेड करने की जगह के आस-पास दिखते हैं. जैसे, एक जैसे विषयों पर बने YouTube वीडियो, जिन्हें एक ही उपयोगकर्ताओं ने देखा है. सुपरवाइज़्ड सिमिलैरिटी मेज़र, उदाहरणों के जोड़े के लिए, मिलती-जुलती चीज़ों की संख्या का हिसाब लगाने के लिए, इस "नज़दीकी" का इस्तेमाल करता है.
याद रखें, हम सिमिलैरिटी मेज़र करने के लिए, सिर्फ़ सुपरवाइज़्ड लर्निंग के बारे में बात कर रहे हैं. इसके बाद, एल्गोरिदम, मैन्युअल या सुपरवाइज़्ड, दोनों तरह की मिलती-जुलती चीज़ों को मेज़र करता है. इससे, बिना निगरानी वाले क्लस्टर बनाने में मदद मिलती है.
मैन्युअल और निगरानी वाले मेज़र की तुलना
इस टेबल में बताया गया है कि आपकी ज़रूरतों के हिसाब से, मैन्युअल या निगरानी में रखी गई मिलती-जुलती कॉन्टेंट की जांच करने के तरीके का इस्तेमाल कब करना चाहिए.
| आवश्यकता | मैन्युअल | निगरानी में है |
|---|---|---|
| क्या यह मिलती-जुलती सुविधाओं में मौजूद ग़ैर-ज़रूरी जानकारी को हटाता है? | नहीं, आपको सुविधाओं के बीच के किसी भी संबंध की जांच करनी होगी. | हां, डीएनएन से ग़ैर-ज़रूरी जानकारी हट जाती है. |
| क्या यह कैलकुलेट की गई समानताओं के बारे में अहम जानकारी देता है? | हां | नहीं, एम्बेड किए गए डेटा को समझा नहीं जा सकता. |
| क्या यह कुछ सुविधाओं वाले छोटे डेटासेट के लिए सही है? | हां. | नहीं, छोटे डेटासेट से डीएनएन के लिए ज़रूरत के मुताबिक ट्रेनिंग डेटा नहीं मिलता. |
| क्या यह कई सुविधाओं वाले बड़े डेटासेट के लिए सही है? | नहीं, एक से ज़्यादा सुविधाओं से ग़ैर-ज़रूरी जानकारी को मैन्युअल तरीके से हटाना और फिर उन्हें आपस में जोड़ना बहुत मुश्किल है. | हां, डीडीएन, ग़ैर-ज़रूरी जानकारी को अपने-आप हटा देता है और सुविधाओं को आपस में जोड़ देता है. |
निगरानी में रखी गई मिलती-जुलती चीज़ों का आकलन करने वाला मॉडल बनाना
यहां, निगरानी में रखी गई मिलती-जुलती चीज़ों को मेज़र करने की प्रोसेस के बारे में खास जानकारी दी गई है:

इस पेज पर डीडीएन के बारे में बताया गया है, जबकि अगले पेजों पर बाकी चरण के बारे में बताया गया है.
ट्रेनिंग लेबल के आधार पर डीएनएन चुनना
अपने फ़ीचर डेटा को कम डाइमेंशन वाले एम्बेड में बदलें. इसके लिए, एक डीएनएन को ट्रेनिंग दें, जो इनपुट और लेबल, दोनों के तौर पर एक ही फ़ीचर डेटा का इस्तेमाल करता है. उदाहरण के लिए, घर के डेटा के मामले में, डीएनएन की मदद से कीमत, साइज़, और पिन कोड जैसी सुविधाओं का इस्तेमाल करके, उन सुविधाओं का अनुमान लगाया जा सकता है.
ऑटोएन्कोडर
किसी डीडीएन को ऑटोएन्कोडर कहा जाता है. यह इनपुट डेटा का अनुमान लगाकर, इनपुट डेटा के एम्बेडिंग को सीखता है. ऑटोएन्कोडर की हिडन लेयर, इनपुट और आउटपुट लेयर से छोटी होती हैं. इसलिए, ऑटोएन्कोडर को इनपुट फ़ीचर डेटा का संकुचित वर्शन सीखना पड़ता है. डीडीएन को ट्रेनिंग देने के बाद, सबसे छोटी हिडन लेयर से एम्बेडिंग निकालें, ताकि मिलती-जुलती चीज़ों का हिसाब लगाया जा सके.
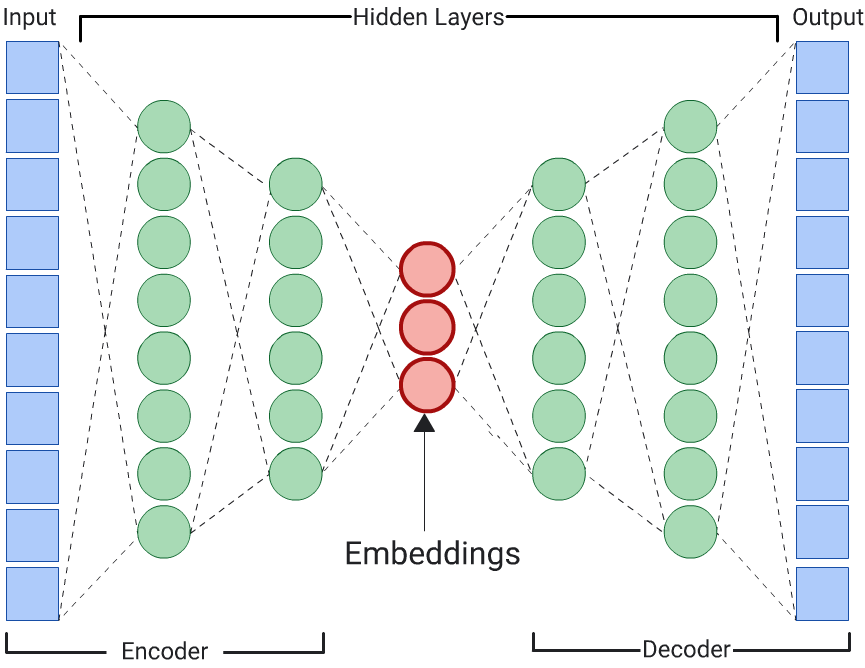
अनुमान लगाने वाला
एम्बेड जनरेट करने के लिए, ऑटोएन्कोडर सबसे आसान विकल्प है. हालांकि, ऑटोएन्कोडर तब सबसे सही विकल्प नहीं होता, जब मिलती-जुलती चीज़ों का पता लगाने के लिए कुछ खास सुविधाएं, दूसरी सुविधाओं से ज़्यादा अहम हो सकती हैं. उदाहरण के लिए, होम डेटा में, मान लें कि कीमत, पिन कोड से ज़्यादा अहम है. ऐसे मामलों में, डीडीएन के लिए ट्रेनिंग लेबल के तौर पर सिर्फ़ ज़रूरी सुविधा का इस्तेमाल करें. यह डीडीएन, सभी इनपुट फ़ीचर का अनुमान लगाने के बजाय, किसी खास इनपुट फ़ीचर का अनुमान लगाता है. इसलिए, इसे प्रेडिकटर डीडीएन कहा जाता है. आम तौर पर, एम्बेडिंग को आखिरी एम्बेडिंग लेयर से निकाला जाना चाहिए.
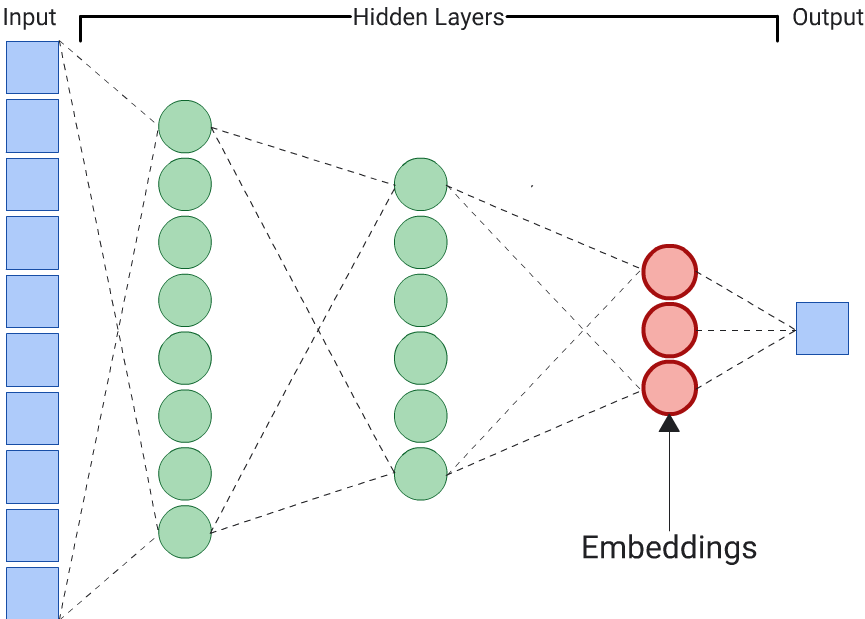
लेबल के तौर पर कोई सुविधा चुनते समय:
कैटगरी वाली सुविधाओं के बजाय, संख्या वाली सुविधाओं को प्राथमिकता दें. ऐसा इसलिए, क्योंकि संख्या वाली सुविधाओं के लिए, लॉस का हिसाब लगाना और उसका विश्लेषण करना आसान होता है.
डीडीएन के इनपुट से, उस सुविधा को हटाएं जिसका इस्तेमाल लेबल के तौर पर किया जाता है. ऐसा न करने पर, डीडीएन उस सुविधा का इस्तेमाल करके, आउटपुट का सटीक अनुमान लगाएगा. (यह लेबल लीक का एक चरम उदाहरण है.)
आपके चुने गए लेबल के आधार पर, डीएनएन या तो ऑटोएन्कोडर होता है या अनुमान लगाने वाला मॉडल.