En lugar de comparar datos de atributos combinados de forma manual, puedes reducir los datos de atributos a representaciones llamadas incorporaciones y, luego, compararlas. Para generar incorporaciones, se entrena una red neuronal profunda (DNN) supervisada en los datos de atributos. Las incorporaciones asignan los datos de atributos a un vector en un espacio de incorporación que, por lo general, tiene menos dimensiones que los datos de atributos. Las incorporaciones se analizan en el módulo Incorporaciones del Curso intensivo de aprendizaje automático, mientras que las redes neuronales se analizan en el módulo Redes neuronales. Los vectores de incorporación para ejemplos similares, como videos de YouTube sobre temas similares que miraron los mismos usuarios, terminan cerca unos de otros en el espacio de incorporación. Una medida de similitud supervisada usa esta "proximidad" para cuantificar la similitud de los pares de ejemplos.
Recuerda que estamos hablando del aprendizaje supervisado solo para crear nuestra medida de similitud. Luego, un algoritmo usa la medida de similitud, ya sea manual o supervisada, para realizar el agrupamiento no supervisado.
Comparación de las medidas manuales y supervisadas
En esta tabla, se describe cuándo usar una medida de similitud manual o supervisada según tus requisitos.
| Requisito | Manual | Supervisado |
|---|---|---|
| ¿Elimina la información redundante en los atributos correlacionados? | No, debes investigar las correlaciones entre las funciones. | Sí, el DNN elimina la información redundante. |
| ¿Proporciona estadísticas sobre las similitudes calculadas? | Sí | No, las incorporaciones no se pueden descifrar. |
| ¿Es adecuado para conjuntos de datos pequeños con pocas funciones? | Sí. | No, los conjuntos de datos pequeños no proporcionan suficientes datos de entrenamiento para una DNN. |
| ¿Es adecuada para conjuntos de datos grandes con muchas funciones? | No, eliminar manualmente la información redundante de varias funciones y, luego, combinarlas es muy difícil. | Sí, el DNN elimina automáticamente la información redundante y combina las funciones. |
Cómo crear una medida de similitud supervisada
Esta es una descripción general del proceso para crear una medida de similitud supervisada:

En esta página, se analizan los DNN, mientras que en las siguientes páginas se abordan los pasos restantes.
Elige un DNN según las etiquetas de entrenamiento
Entrena una DNN que use los mismos datos de atributos como entrada y como etiquetas para reducir tus datos de atributos a incorporaciones de menor dimensión. Por ejemplo, en el caso de los datos de casas, la DNN usaría los atributos, como el precio, el tamaño y el código postal, para predecir esos atributos.
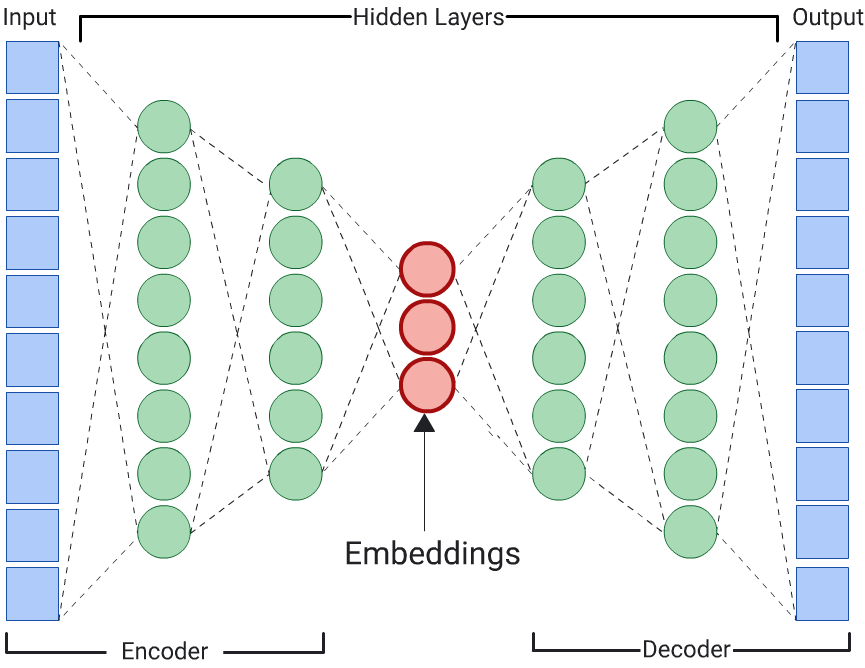
Codificador automático
Una DNN que aprende incorporaciones de datos de entrada a través de la predicción de los datos de entrada en sí se denomina autocodificador. Debido a que las capas ocultas de un autocodificador son más pequeñas que las capas de entrada y salida, el autocodificador se ve obligado a aprender una representación comprimida de los datos de atributos de entrada. Una vez que se entrene la DNN, extrae las incorporaciones de la capa oculta más pequeña para calcular la similitud.
Predictor
Un autocodificador es la opción más sencilla para generar incorporaciones. Sin embargo, un autocodificador no es la opción óptima cuando ciertas características podrían ser más importantes que otras para determinar la similitud. Por ejemplo, en los datos de casas, asume que el precio es más importante que el código postal. En esos casos, usa solo el atributo importante como la etiqueta de entrenamiento para la DNN. Dado que esta DNN predice una característica de entrada específica en lugar de predecir todas las características de entrada, se la denomina DNN de predicción. Por lo general, las incorporaciones se deben extraer de la última capa de incorporación.
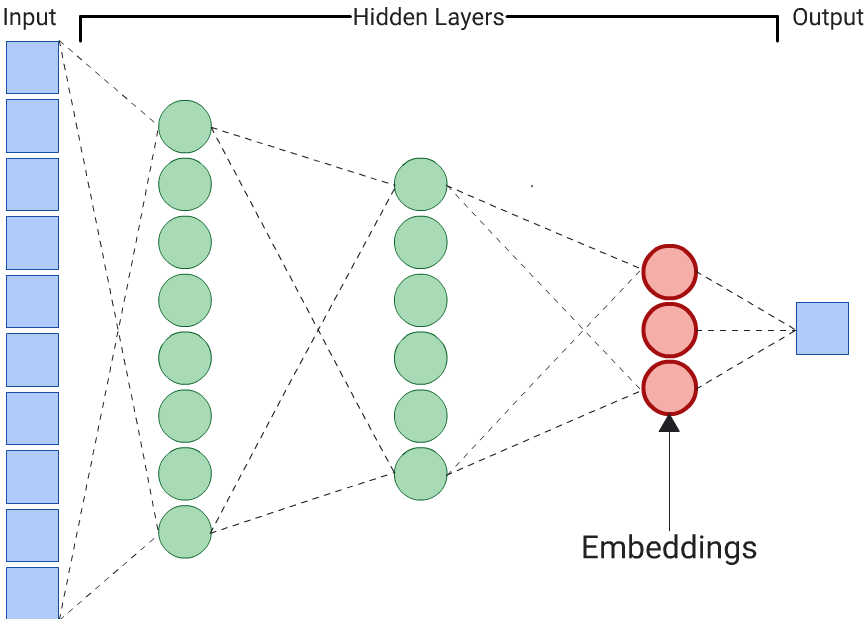
Cuando elijas una función para que sea la etiqueta, ten en cuenta lo siguiente:
Prefiere los atributos numéricos a los categóricos, ya que la pérdida es más fácil de calcular e interpretar para los atributos numéricos.
Quita la función que usas como etiqueta de la entrada a la DNN, de lo contrario, esta usará esa función para predecir perfectamente el resultado. (Este es un ejemplo extremo de filtración de etiquetas).
Según la elección de las etiquetas, la DNN resultante es un autocodificador o un predictor.