Daripada membandingkan data fitur yang digabungkan secara manual, Anda dapat mengurangi data fitur menjadi representasi yang disebut penyematan, lalu membandingkan penyematan. Penyematan dihasilkan dengan melatih deep neural network (DNN) yang diawasi pada data fitur itu sendiri. Embedding memetakan data fitur ke vektor dalam ruang penyematan yang biasanya memiliki dimensi lebih sedikit daripada data fitur. Penyematan dibahas dalam modul Penyematan dari Kursus Singkat Machine Learning, sedangkan jaringan neural dibahas dalam modul Jaringan neural. Vektor penyematan untuk contoh serupa, seperti video YouTube tentang topik serupa yang ditonton oleh pengguna yang sama, akan berdekatan di ruang penyematan. Pengukuran kesamaan terpandu menggunakan "kedekatan" ini untuk mengukur kesamaan untuk pasangan contoh.
Ingat, kita membahas pembelajaran dengan pengawasan hanya untuk membuat pengukuran kemiripan. Pengukuran kesamaan, baik manual maupun diawasi, kemudian digunakan oleh algoritma untuk melakukan pengelompokan tanpa pengawasan.
Perbandingan Pengukuran Manual dan Supervisi
Tabel ini menjelaskan kapan harus menggunakan pengukuran kemiripan manual atau yang diawasi, bergantung pada persyaratan Anda.
| Persyaratan | Manual | Diawasi |
|---|---|---|
| Menghapus informasi yang tidak perlu dalam fitur yang berkorelasi? | Tidak, Anda perlu menyelidiki korelasi apa pun antara fitur. | Ya, DNN menghilangkan informasi yang berlebihan. |
| Memberikan insight tentang kesamaan yang dihitung? | Ya | Tidak, penyematan tidak dapat diuraikan. |
| Cocok untuk set data kecil dengan sedikit fitur? | Ya. | Tidak, set data kecil tidak memberikan data pelatihan yang cukup untuk DNN. |
| Cocok untuk set data besar dengan banyak fitur? | Tidak, menghapus informasi yang berlebihan dari beberapa fitur secara manual, lalu menggabungkannya sangat sulit. | Ya, DNN secara otomatis menghilangkan informasi yang berlebihan dan menggabungkan fitur. |
Membuat ukuran kesamaan yang diawasi
Berikut adalah ringkasan proses untuk membuat pengukuran kesamaan yang diawasi:

Halaman ini membahas DNN, sedangkan halaman berikut membahas langkah-langkah lainnya.
Memilih DNN berdasarkan label pelatihan
Kurangi data fitur Anda menjadi penyematan berdimensi lebih rendah dengan melatih DNN yang menggunakan data fitur yang sama sebagai input dan sebagai label. Misalnya, dalam kasus data rumah, DNN akan menggunakan fitur—seperti harga, ukuran, dan kode pos—untuk memprediksi fitur tersebut sendiri.
Autoencoder
DNN yang mempelajari penyematan data input dengan memprediksi data input itu sendiri disebut autoencoder. Karena lapisan tersembunyi autoencoder lebih kecil daripada lapisan input dan output, autoencoder dipaksa untuk mempelajari representasi data fitur input yang dikompresi. Setelah DNN dilatih, ekstrak penyematan dari lapisan tersembunyi terkecil untuk menghitung kesamaan.
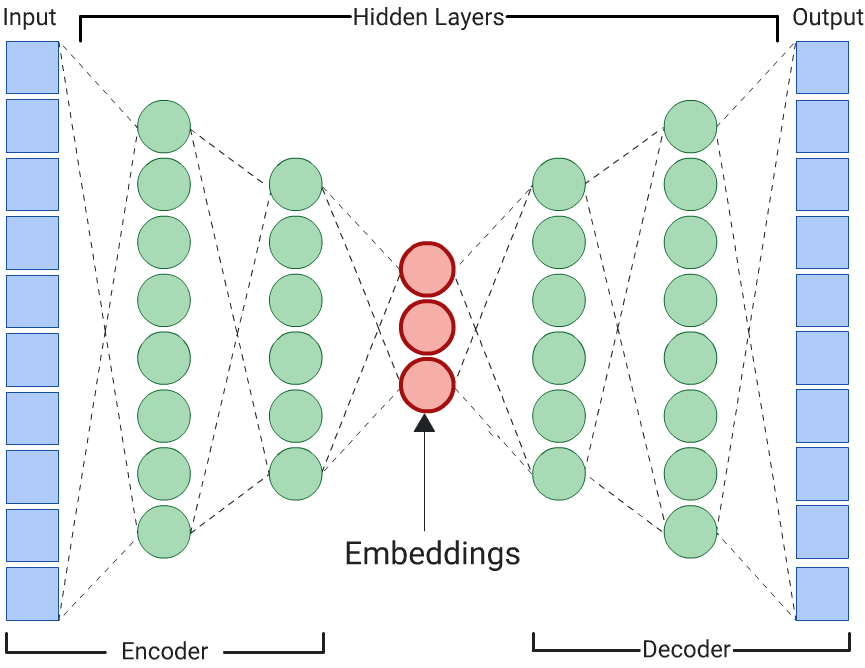
Prediktor
Autoencoder adalah pilihan paling sederhana untuk membuat penyematan. Namun, autoencoder bukanlah pilihan optimal jika fitur tertentu mungkin lebih penting daripada yang lain dalam menentukan kesamaan. Misalnya, dalam data rumah, anggap harga lebih penting daripada kode pos. Dalam kasus tersebut, gunakan hanya fitur penting sebagai label pelatihan untuk DNN. Karena DNN ini memprediksi fitur input tertentu, bukan memprediksi semua fitur input, DNN ini disebut DNN prediktor. Penyematan biasanya harus diekstrak dari lapisan penyematan terakhir.
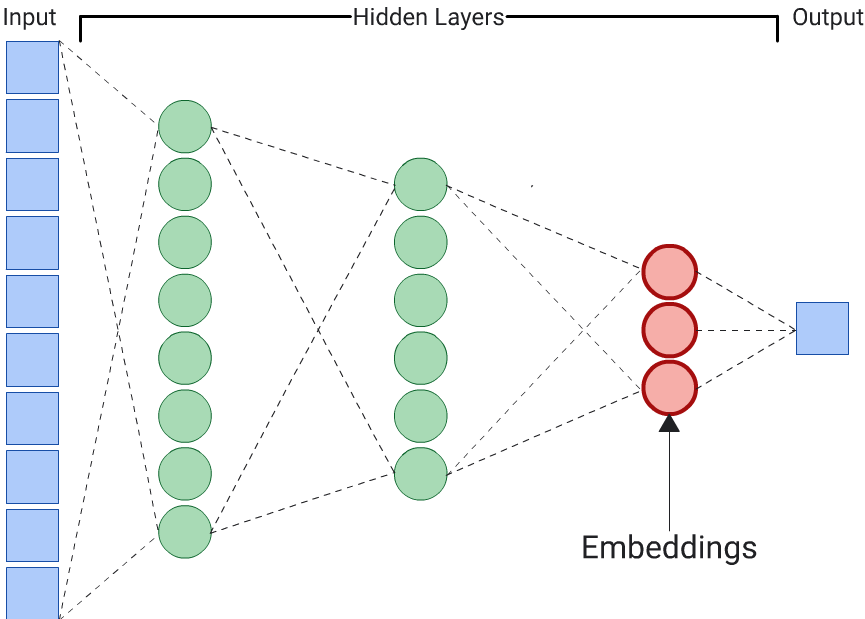
Saat memilih fitur untuk menjadi label:
Pilih fitur numerik daripada kategoris karena loss lebih mudah dihitung dan ditafsirkan untuk fitur numerik.
Hapus fitur yang Anda gunakan sebagai label dari input ke DNN, atau DNN akan menggunakan fitur tersebut untuk memprediksi output dengan sempurna. (Ini adalah contoh ekstrem dari kebocoran label.)
Bergantung pada pilihan label Anda, DNN yang dihasilkan adalah autoencoder atau prediktor.