Thay vì so sánh dữ liệu tính năng được kết hợp theo cách thủ công, bạn có thể giảm dữ liệu tính năng xuống các bản trình bày được gọi là nội dung nhúng, sau đó so sánh các nội dung nhúng đó. Các phần nhúng được tạo bằng cách huấn luyện một mạng nơron sâu (DNN) có giám sát trên chính dữ liệu đặc điểm. Các phần nhúng liên kết dữ liệu đặc điểm với một vectơ trong không gian nhúng thường có ít phương diện hơn dữ liệu đặc điểm. Nội dung về nội dung nhúng được thảo luận trong mô-đun Nội dung nhúng của Khoá học học máy ứng dụng, còn mạng nơron được thảo luận trong mô-đun Mạng nơron. Các vectơ nhúng cho các ví dụ tương tự (chẳng hạn như các video trên YouTube về chủ đề tương tự mà cùng một người dùng xem) sẽ nằm gần nhau trong không gian nhúng. Chỉ số tương đồng có giám sát sử dụng "mức độ gần gũi" này để định lượng mức độ tương đồng cho các cặp ví dụ.
Hãy nhớ rằng chúng ta chỉ thảo luận về phương pháp học có giám sát để tạo ra biện pháp đo lường độ tương đồng. Sau đó, thuật toán sẽ sử dụng phương pháp đo lường mức độ tương đồng, dù là thủ công hay có giám sát, để thực hiện quy trình phân cụm không giám sát.
So sánh biện pháp thủ công và biện pháp có giám sát
Bảng này mô tả thời điểm sử dụng biện pháp đo lường độ tương đồng thủ công hoặc có giám sát tuỳ thuộc vào yêu cầu của bạn.
| Yêu cầu | Thủ công | Chịu sự giám sát |
|---|---|---|
| Loại bỏ thông tin dư thừa trong các tính năng có liên quan? | Không, bạn cần điều tra mọi mối tương quan giữa các tính năng. | Có, DNN loại bỏ thông tin thừa. |
| Cung cấp thông tin chi tiết về mức độ tương đồng được tính toán? | Có | Không, không thể giải mã nội dung nhúng. |
| Phù hợp với các tập dữ liệu nhỏ có ít tính năng? | Có. | Không, các tập dữ liệu nhỏ không cung cấp đủ dữ liệu huấn luyện cho DNN. |
| Thích hợp cho các tập dữ liệu lớn có nhiều tính năng? | Không, việc loại bỏ thông tin thừa khỏi nhiều tính năng theo cách thủ công rồi kết hợp các tính năng đó là rất khó. | Có, DNN tự động loại bỏ thông tin thừa và kết hợp các tính năng. |
Tạo chỉ số tương đồng có giám sát
Dưới đây là thông tin tổng quan về quy trình tạo chỉ số đo lường mức độ tương đồng có giám sát:

Trang này thảo luận về DNN, còn các trang sau đây sẽ trình bày các bước còn lại.
Chọn DNN dựa trên nhãn huấn luyện
Giảm dữ liệu đặc điểm xuống các bản nhúng có kích thước thấp hơn bằng cách huấn luyện một DNN sử dụng cùng một dữ liệu đặc điểm làm dữ liệu đầu vào và nhãn. Ví dụ: trong trường hợp dữ liệu về nhà, DNN sẽ sử dụng các đặc điểm (chẳng hạn như giá, kích thước và mã bưu chính) để tự dự đoán các đặc điểm đó.
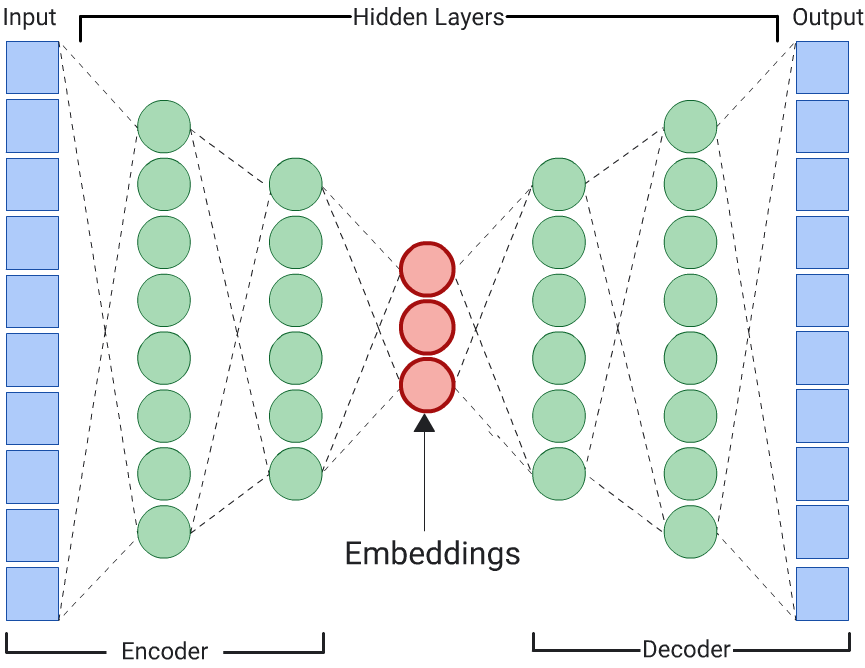
Tự động mã hoá
Một DNN học các bản nhúng của dữ liệu đầu vào bằng cách dự đoán chính dữ liệu đầu vào đó được gọi là tự động mã hoá. Vì các lớp ẩn của bộ tự mã hoá nhỏ hơn các lớp đầu vào và đầu ra, nên bộ tự mã hoá buộc phải học một bản trình bày nén của dữ liệu đặc điểm đầu vào. Sau khi DNN được huấn luyện, hãy trích xuất các giá trị nhúng từ lớp ẩn nhỏ nhất để tính toán mức độ tương đồng.
Phương pháp dự đoán
Tự động mã hoá là lựa chọn đơn giản nhất để tạo các giá trị nhúng. Tuy nhiên, trình tự mã hoá tự động không phải là lựa chọn tối ưu khi một số đặc điểm nhất định có thể quan trọng hơn các đặc điểm khác trong việc xác định mức độ tương đồng. Ví dụ: trong dữ liệu nội bộ, giả sử giá quan trọng hơn mã bưu chính. Trong những trường hợp như vậy, chỉ sử dụng tính năng quan trọng làm nhãn huấn luyện cho DNN. Vì DNN này dự đoán một đặc điểm đầu vào cụ thể thay vì dự đoán tất cả các đặc điểm đầu vào, nên nó được gọi là DNN dự đoán. Các phần nhúng thường được trích xuất từ lớp nhúng cuối cùng.
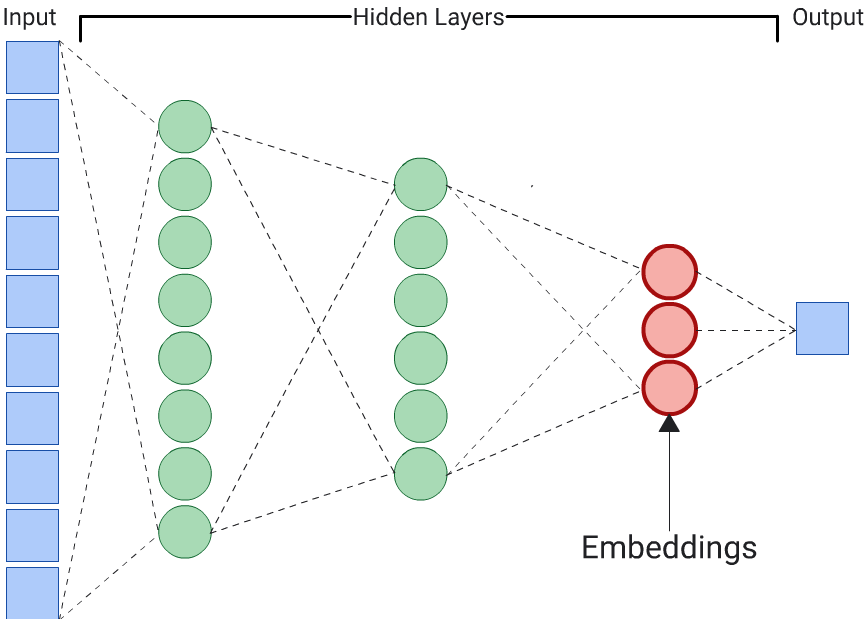
Khi chọn một tính năng làm nhãn:
Ưu tiên các tính năng dạng số hơn là tính năng dạng danh mục vì tổn thất dễ tính toán và diễn giải hơn đối với các tính năng dạng số.
Xoá tính năng mà bạn sử dụng làm nhãn khỏi dữ liệu đầu vào cho DNN, nếu không, DNN sẽ sử dụng tính năng đó để dự đoán chính xác kết quả. (Đây là một ví dụ cực đoan về rò rỉ nhãn.)
Tuỳ thuộc vào lựa chọn nhãn của bạn, DNN thu được sẽ là một trình tự động mã hoá hoặc trình dự đoán.