手動で結合した特徴データを比較する代わりに、特徴データをエンベディングと呼ばれる表現に減らしてから、エンベディングを比較できます。エンベディングは、特徴データ自体で教師ありのディープ ニューラル ネットワーク(DNN)をトレーニングすることで生成されます。エンベディングは、特徴データをエンベディング空間内のベクトルにマッピングします。通常、この空間の次元は特徴データよりも少なくなります。エンベディングについては、機械学習の短期集中コースのエンベディング モジュールで説明しています。ニューラル ネットワークについては、ニューラル ネットワーク モジュールで説明しています。同じユーザーが視聴した類似トピックの YouTube 動画など、類似した例のエンベディング ベクトルは、エンベディング空間内で近接します。教師ありの類似度測定では、この「近さ」を使用して、サンプルペアの類似度を定量化します。
ここでは、類似性測定値を作成するために教師あり学習についてのみ説明します。次に、手動または教師ありの類似性測定値がアルゴリズムによって使用され、教師なしクラスタリングが実行されます。
手動測定と教師あり測定の比較
次の表に、要件に応じて手動または教師ありの類似性測定を使用するタイミングを示します。
| 要件 | 手動 | 管理対象 |
|---|---|---|
| 相関する特徴の重複する情報を排除する | いいえ。特徴間の相関を調査する必要があります。 | はい。DNN は冗長な情報を排除します。 |
| 計算された類似性に関する分析情報を提供します。 | はい | いいえ。エンベディングを解読することはできません。 |
| 特徴の少ない小規模なデータセットに適している | はい。 | いいえ。小規模なデータセットでは、DNN に十分なトレーニング データを提供できません。 |
| 多くの特徴を持つ大規模なデータセットに適していますか? | いいえ。複数の特徴から重複する情報を手動で除去して組み合わせることは非常に困難です。 | はい。DNN は冗長な情報を自動的に排除し、特徴を組み合わせます。 |
教師ありの類似性測度の作成
教師ありの類似性測定値を作成するプロセスの概要は次のとおりです。

このページでは DNN について説明します。残りの手順については、次のページをご覧ください。
トレーニング ラベルに基づいて DNN を選択する
入力とラベルの両方で同じ特徴データを使用している DNN をトレーニングして、特徴データを低次元のエンベディングに減らします。たとえば、住宅データの場合、DNN は価格、面積、郵便番号などの特徴を使用して、それらの特徴自体を予測します。
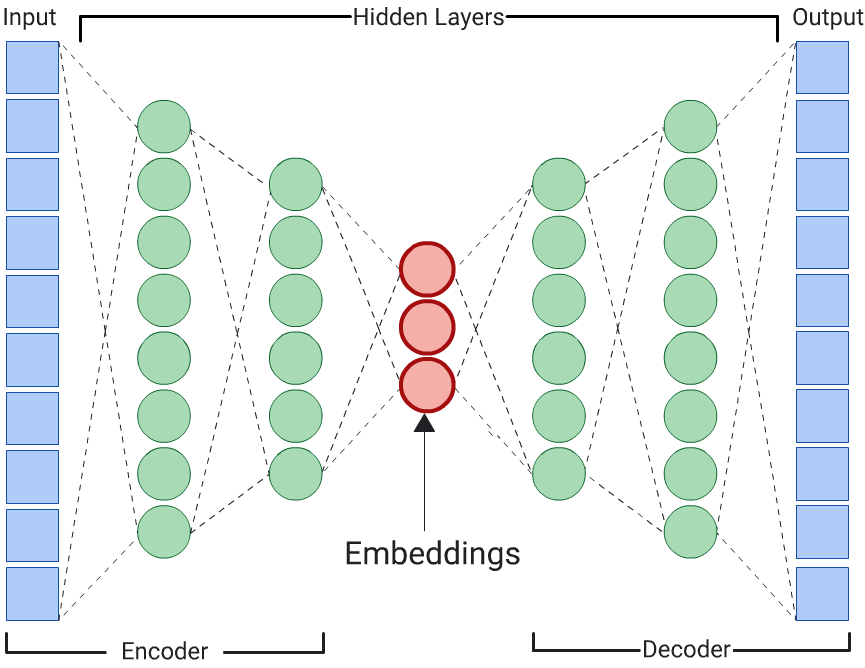
オートエンコーダ
入力データ自体を予測することで入力データのエンベディングを学習する DNN は、オートエンコーダと呼ばれます。オートエンコーダの隠れ層は入力層と出力層よりも小さいため、オートエンコーダは入力特徴データの圧縮表現を学習する必要があります。DNN をトレーニングしたら、最小の隠れ層からエンベディングを抽出して類似性を計算します。
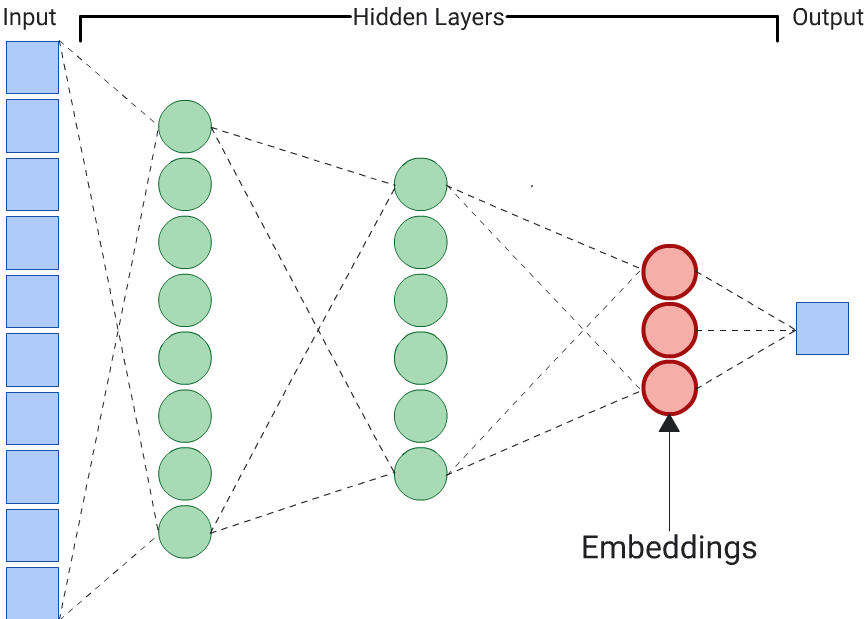
予測子
エンベディングを生成する最も簡単な方法は、オートエンコーダを使用することです。ただし、類似性の判断において特定の特徴が他の特徴よりも重要である場合は、オートエンコーダは最適な選択肢ではありません。たとえば、住宅データでは、郵便番号よりも価格のほうが重要であると想定します。このような場合は、重要な特徴量のみを DNN のトレーニング ラベルとして使用します。この DNN は、すべての入力特徴量を予測するのではなく、特定の入力特徴量を予測するため、予測子 DNN と呼ばれます。通常、エンベディングは最後のエンベディング レイヤから抽出する必要があります。
ラベルにする特徴を選択する際は、次の点に注意してください。
数値特徴の方が損失の計算と解釈が容易であるため、カテゴリ特徴よりも数値特徴を優先します。
ラベルとして使用する特徴量を DNN への入力から削除します。削除しないと、DNN はその特徴量を使用して出力を完全に予測します。(これはラベル漏洩の極端な例です)。
ラベルの選択に応じて、生成される DNN はオートエンコーダまたは予測子になります。