Poiché il clustering è non supervisionato, non è disponibile alcun valore di riferimento per verificare i risultati. L'assenza di verità complica le valutazioni della qualità. Inoltre, i set di dati reali in genere non offrono cluster di esempi evidenti come nell'esempio mostrato nella Figura 1.
I dati reali, invece, spesso assomigliano più alla Figura 2, il che rende difficile valutare visivamente la qualità del clustering.
Tuttavia, esistono procedure di euristica e best practice che puoi applicare in modo iterativo per migliorare la qualità del clustering. Il seguente diagramma di flusso fornisce una panoramica di come valutare i risultati del clustering. Analizzeremo ogni passaggio.

Passaggio 1: valuta la qualità del clustering
Innanzitutto, verifica che i cluster abbiano l'aspetto previsto e che gli esempi che consideri simili tra loro compaiano nello stesso cluster.
Controlla poi queste metriche di uso comune (non è un elenco esaustivo):
- Cardinalità del cluster
- Magnitudine del cluster
- Rendimento downstream
Cardinalità del cluster
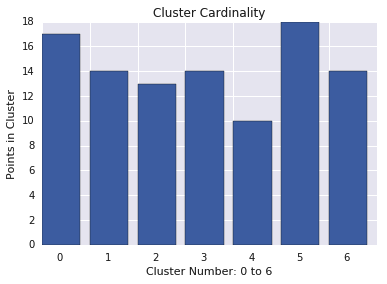
La cardinalità del cluster è il numero di esempi per cluster. Grafica la cardinalità del cluster per tutti i cluster ed esamina i cluster che sono outlier principali. Nella Figura 2, si tratta del cluster 5.
Magnitudine del cluster
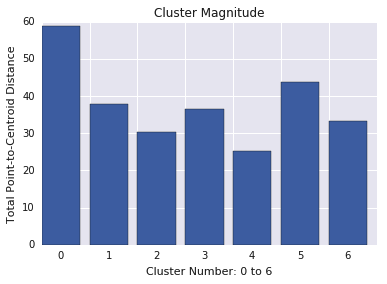
La magnitudine del cluster è la somma delle distanze di tutti gli esempi in un cluster al centroide del cluster. Grafica la magnitudine del cluster per tutti i cluster e esamina gli outlier. Nella Figura 3, il cluster 0 è un outlier.
Per trovare gli outlier, ti consigliamo anche di esaminare la distanza massima o media degli esempi dai centroidi, per cluster.
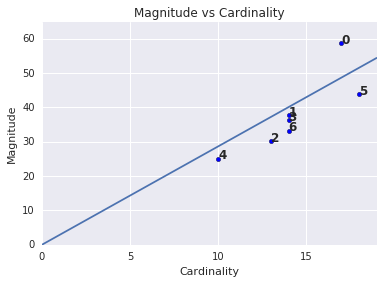
Grandezza e cardinalità
Potresti aver notato che una maggiore cardinalità del cluster corrisponde a una maggiore magnitudine del cluster, il che è intuitivo, poiché più punti in un cluster (cardinalità), maggiore è la probabile somma delle distanze di questi punti dal centroide (magnitudine). Puoi anche identificare cluster anomali cercando quelli in cui questo rapporto tra cardinalità e grandezza è molto diverso rispetto ad altri cluster. Nella Figura 4, l'adattamento di una linea al grafico di cardinalità e grandezza suggerisce che il cluster 0 è anomalo. Anche il cluster 5 è lontano dalla retta, ma se il cluster 0 fosse omesso, la nuova retta calibrata sarebbe molto più vicina al cluster 5.
Rendimento downstream
Poiché i risultati del clustering vengono spesso utilizzati nei sistemi di ML a valle, controlla se il rendimento del modello a valle migliora quando il processo di clustering cambia. In questo modo puoi valutare in modo pratico la qualità dei risultati del clustering, anche se eseguire questo tipo di test può essere complesso e costoso.
Passaggio 2: rivaluta la misura della somiglianza
L'efficacia dell'algoritmo di clustering dipende dalla misura della somiglianza. Assicurati che la misura della somiglianza restituisca risultati ragionevoli. Un controllo rapido consiste nell' identificare coppie di esempi noti per essere più o meno simili. Calcola la misura della somiglianza per ogni coppia di esempi e confronta i risultati con le tue conoscenze: le coppie di esempi simili dovrebbero avere una misura della somiglianza più elevata rispetto alle coppie di esempi non simili.
Gli esempi che utilizzi per verificare la misura della somiglianza devono essere rappresentativi del set di dati, in modo da avere la certezza che la misura della somiglianza valga per tutti gli esempi. Il rendimento della misura della somiglianza, manuale o supervisionata, deve essere coerente nel set di dati. Se la misura della somiglianza non è coerente per alcuni esempi, questi esempi non verranno raggruppati con esempi simili.
Se trovi esempi con punteggi di somiglianza inaccurati, la misura della somiglianza probabilmente non acquisisce completamente i dati delle funzionalità che distinguono questi esempi. Sperimenta con la misura della somiglianza finché non restituisce risultati più accurati e coerenti.
Passaggio 3: trova il numero ottimale di cluster
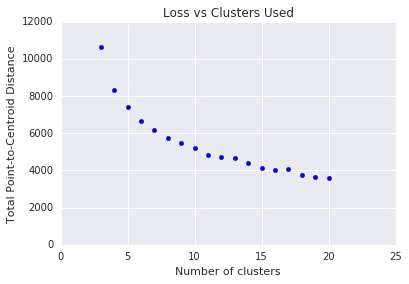
k-means richiede di decidere il numero di cluster \(k\) in anticipo. Come si determina un'offerta ottimale \(k\)? Prova a eseguire l'algoritmo con valori crescenti di \(k\) e prendi nota della somma di tutte le magnitudini dei cluster. Man mano che\(k\) aumenta, i cluster diventano più piccoli e la distanza totale dei punti dai centroidi diminuisce. Possiamo considerare questa distanza totale come una perdita. Grafica questa distanza in base al numero di cluster.
Come mostrato nella Figura 5, al di sopra di un certo \(k\), la riduzione della perdita diventa marginale con l'aumento di \(k\). Valuta la possibilità di utilizzare il valore \(k\) in cui la pendenza presenta per la prima volta una variazione drastica, chiamato metodo del gomito. Per il \(k\) plot mostrato, il valore ottimale è circa 11. Se preferisci cluster più granulari, puoi scegliere un valore più alto \(k\), consultando questo grafico.
Domande sulla risoluzione dei problemi
Se durante la valutazione riscontri problemi, rivaluta i passaggi di preparazione dei dati e la misura di somiglianza scelta. Chiedi:
- I dati sono scalati in modo appropriato?
- La misura della somiglianza è corretta?
- L'algoritmo esegue operazioni semanticamente significative sui dati?
- I presupposti dell'algoritmo corrispondono ai dati?