Zbiór danych jest nienadzorowany, więc nie ma danych rzeczywistych, które można wykorzystać do weryfikacji wyników. Brak prawdziwych informacji utrudnia ocenę jakości. Ponadto zbiory danych z rzeczywistego świata zwykle nie zawierają wyraźnych klastrów przykładów, jak w przypadku pokazanym na rysunku 1.
Dane z prawdziwego świata często wyglądają jednak tak jak na rysunku 2, co utrudnia wizualną ocenę jakości grupowania.
Istnieją jednak heurystyki i sprawdzone metody, które możesz stosować wielokrotnie, aby poprawić jakość klastrów. Na schemacie poniżej znajdziesz omówienie sposobu oceny wyników pogrupowania. Poniżej omówimy każdy z tych kroków.

Krok 1. Oceń jakość zgrupowania
Najpierw sprawdź, czy klastry wyglądają tak, jak powinny, i czy przykłady, które uważasz za podobne, znajdują się w tym samym klastrze.
Następnie sprawdź te najczęściej używane dane (lista nie jest wyczerpująca):
- Liczba elementów klastra
- Wielkość klastra
- Skuteczność w dół łańcucha
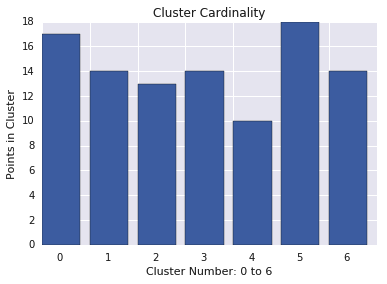
Liczba elementów klastra
Moc zbioru klastra to liczba przykładów na klaster. Wykresl moc zbioru klastra dla wszystkich klastrów i sprawdź, które z nich są największymi odchyleniami. Na rysunku 2 jest to klaster 5.
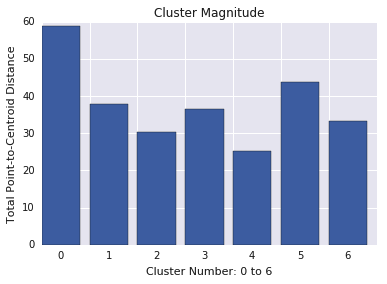
Wielkość klastra
Wielkość klastra to suma odległości wszystkich przykładów w klastrze od jego centroida. Wykreśl wielkość klastra dla wszystkich klastrów i zbadaj wartości odstające. Na rysunku 3 klaster 0 jest wartością odstającą.
Aby znaleźć wartości odstające, możesz też sprawdzić maksymalną lub średnią odległość przykładów od centroidów w poszczególnych klastrach.
Siła a moc zbioru
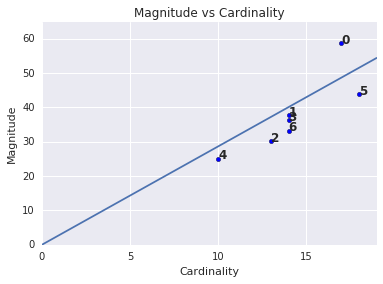
Zauważysz pewnie, że większa moc zbioru klastra odpowiada większej wielkości klastra, co jest intuicyjne, ponieważ im więcej punktów w klastrze (moc zbioru), tym większa prawdopodobna suma odległości tych punktów od centroida (wielkość). Możesz też zidentyfikować nietypowe klastry, szukając takich, w których związek między liczebnością a wielkością jest bardzo różny od tego w przypadku innych klastrów. Na rysunku 4. linia dopasowana do wykresu mocy zbioru i wielkości sugeruje, że klaster 0 jest nieprawidłowy. (Klaster 5 jest też daleko od linii, ale gdyby pominąć klaster 0, nowa dopasowana linia byłaby znacznie bliższa klastrowi 5).
Skuteczność w dół łańcucha
Wyniki podziału na klastry są często używane w systemach uczenia maszynowego, dlatego sprawdź, czy wydajność modelu na dalszych etapach poprawia się po zmianie procesu podziału na klastry. Dzięki temu możesz ocenić jakość wyników pogrupowania w rzeczywistych warunkach, ale przeprowadzenie tego rodzaju testu może być skomplikowane i drogie.
Krok 2. Ponownie oceń podobieństwo
Algorytm grupowania jest tak dobry, jak dobry jest sposób pomiaru podobieństwa. Upewnij się, że pomiar podobieństwa zwraca sensowne wyniki. Szybka kontrola polega na identyfikowaniu par przykładów, które są mniej lub bardziej podobne. Oblicz miarę podobieństwa dla każdej pary przykładów i porównaj wyniki z Twoją wiedzą: pary podobnych przykładów powinny mieć wyższą miarę podobieństwa niż pary niepodobnych przykładów.
Przykłady, których używasz do sprawdzenia miary podobieństwa, powinny być reprezentatywne dla zbioru danych, aby mieć pewność, że miara podobieństwa jest prawidłowa w przypadku wszystkich przykładów. Wyniki pomiaru podobieństwa, czy to ręcznego, czy nadzorowanego, muszą być spójne w przypadku całego zbioru danych. Jeśli w przypadku niektórych przykładów miarą podobieństwa jest niespójna, przykłady te nie zostaną zgrupowane z podobnymi przykładami.
Jeśli znajdziesz przykłady z nieprawidłowymi wynikami podobieństwa, prawdopodobnie Twój pomiar podobieństwa nie uwzględnia w pełni danych o cechach, które odróżniają te przykłady. Eksperymentuj z miarą podobieństwa, aż zacznie zwracać dokładniejsze i spójniejsze wyniki.
Krok 3. Znajdź optymalną liczbę klastrów
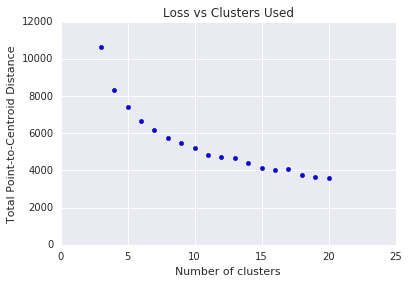
Grupowanie k-średnich wymaga określenia liczby klasterów \(k\) z wyprzedzeniem. Jak określasz optymalną wartość \(k\)? Spróbuj uruchomić algorytm z rosnącymi wartościami \(k\) i zapisz sumę wszystkich wielkości klastra. W miarę zwiększania wartości parametru\(k\) klastry stają się mniejsze, a łączna odległość punktów od centroidów maleje. Możemy traktować ten całkowity dystans jako stratę. Odległość tę można przedstawić na wykresie w zależności od liczby klastrów.
Jak widać na rysunku 5, powyżej pewnej wartości \(k\)spadek strat staje się nieznaczny przy rosnącej wartości \(k\). Rozważ użycie \(k\), gdzie nachylenie ma gwałtowną zmianę, co nazywamy metodą łokciową. W przypadku przedstawionego wykresu optymalna wartość \(k\) wynosi około 11. Jeśli wolisz bardziej szczegółowe klastry, możesz wybrać wyższą wartość \(k\), korzystając z tego wykresu.
Pytania dotyczące rozwiązywania problemów
Jeśli w trakcie oceny zauważysz problemy, ponownie przeanalizuj czynności związane z przygotowaniem danych i wybraną miarę podobieństwa. Zadaj sobie pytanie:
- Czy dane są odpowiednio przeskalowane?
- Czy wskaźnik podobieństwa jest prawidłowy?
- Czy algorytm wykonuje na danych operacje o znaczeniu semantycznym?
- Czy założenia algorytmu są zgodne z danymi?