Como a clusterização é não supervisionada, nenhuma informação empírica está disponível para verificar os resultados. A ausência de verdade complica as avaliações de qualidade. Além disso, conjuntos de dados reais geralmente não oferecem clusters óbvios de exemplos, como no exemplo mostrado na Figura 1.
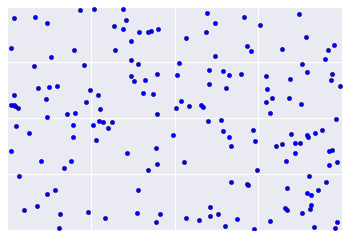
Em vez disso, os dados do mundo real costumam se parecer mais com a Figura 2, o que dificulta a avaliação visual da qualidade do agrupamento.
No entanto, existem heurísticas e práticas recomendadas que você pode aplicar de forma iterativa para melhorar a qualidade do agrupamento. O fluxograma a seguir mostra uma visão geral de como avaliar os resultados de agrupamento. Vamos detalhar cada etapa.

Etapa 1: avaliar a qualidade da agrupação
Primeiro, verifique se os clusters estão como você espera e se os exemplos que você considera semelhantes aparecem no mesmo cluster.
Em seguida, confira estas métricas usadas com frequência (não é uma lista exaustiva):
- Cardinalidade do cluster
- Magnitude do cluster
- Desempenho downstream
Cardinalidade do cluster
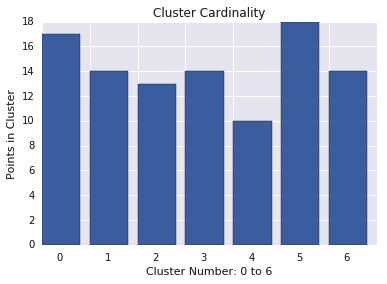
A cardinalidade do cluster é o número de exemplos por cluster. Represente a cardinalidade do cluster para todos os clusters e investigue os clusters que são outliers importantes. Na Figura 2, esse é o cluster 5.
Magnitude do cluster
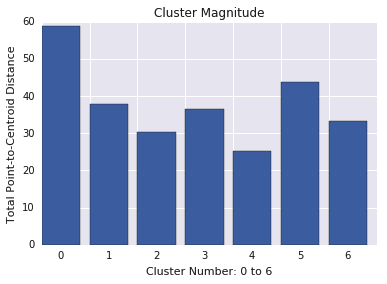
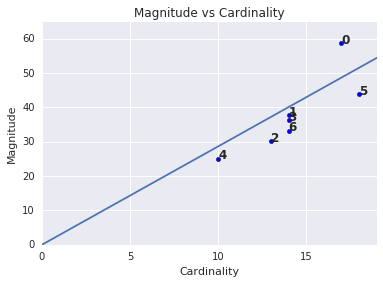
A magnitude do cluster é a soma das distâncias de todos os exemplos em um cluster ao centroide do cluster. Plote a magnitude do cluster para todos os clusters e investigue valores discrepantes. Na Figura 3, o cluster 0 é um outlier.
Considere também a distância máxima ou média dos exemplos dos centroides, por cluster, para encontrar outliers.
Magnitude x cardinalidade
Você pode ter notado que uma cardinalidade de cluster maior corresponde a uma magnitude de cluster maior, o que faz sentido intuitivamente, já que quanto mais pontos em um cluster (cardinalidade), maior é a soma provável das distâncias desses pontos do centroid (magnitude). Também é possível identificar clusters anormais procurando aqueles em que essa relação entre cardinalidade e magnitude é muito diferente dos outros clusters. Na Figura 4, o ajuste de uma linha ao gráfico de cardinalidade e magnitude sugere que o cluster 0 é anormal. O cluster 5 também está longe da linha, mas se o cluster 0 for omitido, a nova linha ajustada estará muito mais próxima do cluster 5.
Desempenho downstream
Como as saídas de agrupamento são usadas com frequência em sistemas de ML downstream, verifique se a performance do modelo downstream melhora quando o processo de agrupamento muda. Isso oferece uma avaliação real da qualidade dos resultados de agrupamento, embora possa ser complexo e caro realizar esse tipo de teste.
Etapa 2: reavaliar a medida de similaridade
O algoritmo de agrupamento é tão bom quanto a medida de similaridade. Verifique se a medida de similaridade retorna resultados razoáveis. Uma verificação rápida é identificar pares de exemplos conhecidos por serem mais ou menos semelhantes. Calcule a medida de similaridade para cada par de exemplos e compare os resultados com seu conhecimento: pares de exemplos semelhantes devem ter uma medida de similaridade maior do que pares de exemplos diferentes.
Os exemplos usados para verificar a medida de similaridade precisam ser representativos do conjunto de dados. Assim, você pode ter certeza de que a medida de similaridade é válida para todos os exemplos. O desempenho da sua medida de similaridade, manual ou supervisionada, precisa ser consistente em todo o conjunto de dados. Se a medida de similaridade for inconsistente para alguns exemplos, eles não serão agrupados com exemplos semelhantes.
Se você encontrar exemplos com pontuações de similaridade imprecisas, sua medida de similaridade provavelmente não captura totalmente os dados de recursos que distinguem esses exemplos. Teste sua medida de similaridade até que ela retorne resultados mais precisos e consistentes.
Etapa 3: encontrar o número ideal de clusters
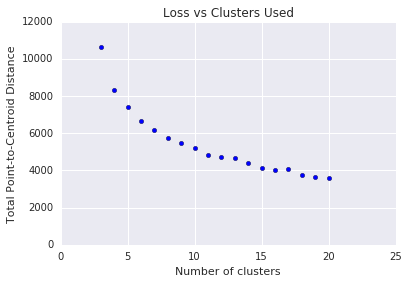
A k-means exige que você decida o número de clusters \(k\) com antecedência. Como determinar um \(k\)ideal? Tente executar o algoritmo com valores crescentes de \(k\) e observe a soma de todas as magnitudes do cluster. À medida que \(k\) aumenta, os clusters ficam menores, e a distância total dos pontos dos centroides diminui. Podemos tratar essa distância total como uma perda. Represente essa distância em relação ao número de clusters.
Como mostrado na Figura 5, acima de um determinado \(k\), a redução na perda se torna marginal com o aumento da \(k\). Considere usar o \(k\) em que a inclinação tem uma mudança drástica, o que é chamado de método do cotovelo. Para o gráfico mostrado, o \(k\) ideal é aproximadamente 11. Se você preferir clusters mais granulares, escolha uma \(k\)mais alta consultando este gráfico.
Perguntas sobre solução de problemas
Se você descobrir problemas durante a avaliação, reavalie as etapas de preparação de dados e a medida de similaridade escolhida. Pergunte:
- Seus dados estão dimensionados de forma adequada?
- Sua medida de similaridade está correta?
- O algoritmo está realizando operações semanticamente significativas nos dados?
- As suposições do algoritmo correspondem aos dados?