क्लस्टरिंग की प्रोसेस में, डेटा को मैन्युअल तरीके से नहीं बांटा जाता. इसलिए, नतीजों की पुष्टि करने के लिए कोई ज़मीनी हकीकत उपलब्ध नहीं होती. सच्चाई न होने पर, क्वालिटी का आकलन करना मुश्किल हो जाता है. इसके अलावा, असल दुनिया के डेटासेट में आम तौर पर, उदाहरणों के क्लस्टर नहीं होते. जैसे, पहली इमेज में दिखाया गया उदाहरण.
इसके बजाय, असल डेटा अक्सर दूसरे चित्र की तरह दिखता है. इससे क्लस्टरिंग की क्वालिटी का आकलन करना मुश्किल हो जाता है.
हालांकि, क्लस्टर करने की क्वालिटी को बेहतर बनाने के लिए, कुछ हेयुरिस्टिक्स और सबसे सही तरीके हैं. इन्हें बार-बार लागू किया जा सकता है. यहां दिए गए फ़्लोचार्ट में, क्लस्टर करने के नतीजों का आकलन करने के तरीके के बारे में खास जानकारी दी गई है. हम हर चरण के बारे में विस्तार से बताएंगे.

पहला चरण: क्लस्टर करने की क्वालिटी का आकलन करना
सबसे पहले, देखें कि क्लस्टर आपकी उम्मीद के मुताबिक हैं या नहीं. साथ ही, यह भी देखें कि आपके हिसाब से एक जैसे उदाहरण एक ही क्लस्टर में दिख रहे हैं या नहीं.
इसके बाद, आम तौर पर इस्तेमाल होने वाली इन मेट्रिक को देखें. हालांकि, इनके अलावा और भी मेट्रिक हो सकती हैं:
- क्लस्टर में एलिमेंट की संख्या
- क्लस्टर का मैग्नीट्यूड
- डाउनस्ट्रीम परफ़ॉर्मेंस
क्लस्टर में एलिमेंट की संख्या
क्लस्टर एलिमेंट की संख्या, हर क्लस्टर में मौजूद उदाहरणों की संख्या होती है. सभी क्लस्टर के लिए क्लस्टर एलिमेंट की संख्या प्लॉट करें और उन क्लस्टर की जांच करें जो मुख्य आउटलायर हैं. दूसरे चित्र में, यह क्लस्टर 5 होगा.
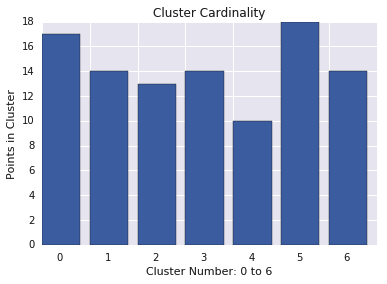
क्लस्टर का मैग्नीट्यूड
क्लस्टर का मैग्नीट्यूड, क्लस्टर के सभी उदाहरणों से क्लस्टर के सेंट्रोइड तक की दूरियों का योग होता है. सभी क्लस्टर के लिए क्लस्टर मैग्नीट्यूड प्लॉट करें और आउटलायर की जांच करें. तीसरे चित्र में, क्लस्टर 0 एक आउटलायर है.
आउटलायर ढूंढने के लिए, क्लस्टर के हिसाब से सेंट्रोइड से उदाहरणों की सबसे ज़्यादा या औसत दूरी देखें.
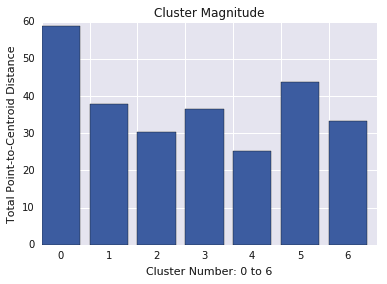
एलिमेंट की संख्या बनाम तीव्रता
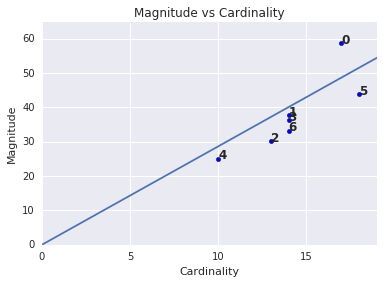
आपने देखा होगा कि क्लस्टर में एलिमेंट की संख्या जितनी ज़्यादा होगी, क्लस्टर का मैग्नीट्यूड भी उतना ही ज़्यादा होगा. यह बात आसानी से समझ आती है, क्योंकि क्लस्टर में एलिमेंट (एलिमेंट की संख्या) जितने ज़्यादा होंगे, सेंट्राइड (मैग्नीट्यूड) से उन एलिमेंट की दूरियों का संभावित योग भी उतना ही ज़्यादा होगा. ऐसे क्लस्टर की पहचान भी की जा सकती है जिनमें एलिमेंट की संख्या और मैग्नीट्यूड के बीच का संबंध, अन्य क्लस्टर के मुकाबले काफ़ी अलग है. चौथे चित्र में, एलिमेंट की संख्या और मैग्नीट्यूड के प्लॉट में लाइन फ़िट करने से पता चलता है कि क्लस्टर 0 में गड़बड़ी है. (क्लस्टर 5 भी लाइन से दूर है, लेकिन अगर क्लस्टर 0 को हटा दिया जाता है, तो नई लाइन क्लस्टर 5 के बहुत करीब होगी.)
डाउनस्ट्रीम परफ़ॉर्मेंस
क्लस्टरिंग के आउटपुट का इस्तेमाल, अक्सर डाउनस्ट्रीम एमएल सिस्टम में किया जाता है. इसलिए, देखें कि क्लस्टरिंग की प्रोसेस में बदलाव होने पर, डाउनस्ट्रीम मॉडल की परफ़ॉर्मेंस बेहतर होती है या नहीं. इससे क्लस्टर करने के नतीजों की क्वालिटी का असल आकलन किया जा सकता है. हालांकि, इस तरह की जांच करना मुश्किल और महंगा हो सकता है.
दूसरा चरण: मिलते-जुलते कॉन्टेंट का आकलन फिर से करना
क्लस्टरिंग एल्गोरिदम उतना ही अच्छा होता है जितना कि मिलती-जुलती चीज़ों को मेज़र करने का तरीका. पक्का करें कि मिलते-जुलते कॉन्टेंट का आकलन करने वाला टूल, सही नतीजे दिखाता हो. एक तुरंत जांच यह है कि कम या ज़्यादा मिलते-जुलते उदाहरणों के जोड़े की पहचान की जाए. उदाहरणों के हर जोड़े के लिए, मिलती-जुलती चीज़ों के मेज़र का हिसाब लगाएं और अपने नतीजों की तुलना अपनी जानकारी से करें: मिलते-जुलते उदाहरणों के जोड़े के लिए, मिलती-जुलती चीज़ों के मेज़र की वैल्यू, अलग-अलग उदाहरणों के जोड़े के लिए, मिलती-जुलती चीज़ों के मेज़र की वैल्यू से ज़्यादा होनी चाहिए.
मिलते-जुलते कॉन्टेंट की जांच करने के लिए इस्तेमाल किए जाने वाले उदाहरण, डेटासेट के प्रतिनिधि होने चाहिए. इससे आपको यह भरोसा रहेगा कि मिलते-जुलते कॉन्टेंट की जांच करने का तरीका, आपके सभी उदाहरणों के लिए सही है. मैन्युअल या सुपरवाइज़्ड, दोनों तरह के मिलते-जुलते डेटा को मेज़र करने की परफ़ॉर्मेंस, आपके डेटासेट में एक जैसी होनी चाहिए. अगर कुछ उदाहरणों के लिए, मिलते-जुलते कॉन्टेंट का आकलन करने का तरीका अलग-अलग है, तो उन उदाहरणों को मिलते-जुलते उदाहरणों के साथ क्लस्टर नहीं किया जाएगा.
अगर आपको मिलते-जुलते प्रॉडक्ट के लिए गलत स्कोर मिलते हैं, तो हो सकता है कि मिलते-जुलते प्रॉडक्ट का आकलन करने वाला आपका तरीका, उन प्रॉडक्ट की उन सुविधाओं का डेटा पूरी तरह से कैप्चर न कर पा रहा हो जिनसे वे एक-दूसरे से अलग हैं. मिलते-जुलते कॉन्टेंट का पता लगाने के लिए, अलग-अलग तरीके आज़माएं. ऐसा तब तक करें, जब तक आपको सटीक और एक जैसे नतीजे न मिल जाएं.
तीसरा चरण: क्लस्टर की सही संख्या ढूंढना
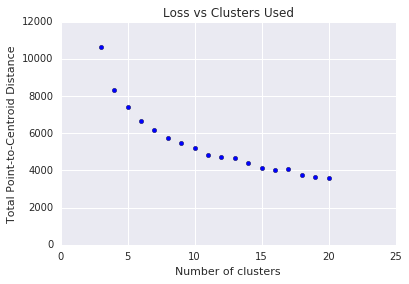
k-means के लिए, आपको क्लस्टर की संख्या \(k\) पहले से तय करनी होगी. सबसे सही बिड कैसे तय की जाती है \(k\)? \(k\) की बढ़ती वैल्यू के साथ एल्गोरिदम को चलाकर, सभी क्लस्टर मैग्नीट्यूड का योग नोट करें.\(k\) बढ़ने पर, क्लस्टर छोटे हो जाते हैं और सेंट्राइड से पॉइंट की कुल दूरी कम हो जाती है. हम इस कुल दूरी को नुकसान के तौर पर ले सकते हैं. इस दूरी को क्लस्टर की संख्या के हिसाब से प्लॉट करें.
जैसा कि फ़िगर 5 में दिखाया गया है, किसी तय \(k\)के बाद, \(k\)में बढ़ोतरी होने पर, नुकसान में कमी मामूली हो जाती है. \(k\) वह जगह चुनें जहां ढलान में पहली बार काफ़ी बदलाव होता है. इसे एलबो मेथड कहा जाता है. दिखाए गए प्लॉट के लिए, \(k\) का सबसे सही वैल्यू लगभग 11 है. अगर आपको ज़्यादा जानकारी वाले क्लस्टर चाहिए, तो इस प्लॉट की मदद से, ज़्यादा \(k\)चुनें.
समस्या हल करने के लिए सवाल
अगर आपको अपने आकलन के दौरान समस्याएं मिलती हैं, तो डेटा तैयार करने के तरीके और मिलती-जुलती चीज़ों को मेज़र करने के लिए चुने गए तरीके की फिर से समीक्षा करें. सवाल:
- क्या आपके डेटा को सही तरीके से स्केल किया गया है?
- क्या मिलते-जुलते कॉन्टेंट का आकलन सही है?
- क्या आपका एल्गोरिदम, डेटा पर काम के काम कर रहा है?
- क्या आपके एल्गोरिदम के अनुमान, डेटा से मेल खाते हैं?