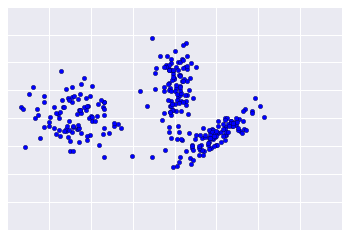
Da das Clustering unüberwacht erfolgt, gibt es keine Ground Truth, um die Ergebnisse zu überprüfen. Die Abwesenheit von Wahrheit erschwert die Bewertung der Qualität. Außerdem bieten reale Datensätze in der Regel keine offensichtlichen Cluster von Beispielen wie im Beispiel in Abbildung 1.
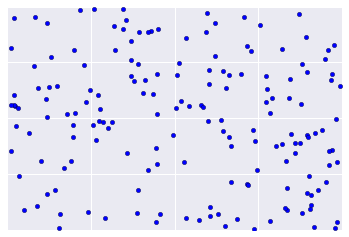
Stattdessen sehen reale Daten oft eher wie in Abbildung 2 aus, was die visuelle Bewertung der Clusterqualität erschwert.
Es gibt jedoch Heuristiken und Best Practices, die Sie iterativ anwenden können, um die Qualität des Clusterings zu verbessern. Das folgende Flussdiagramm gibt einen Überblick darüber, wie Sie die Clusteringergebnisse auswerten. Wir gehen auf jeden Schritt näher ein.

Schritt 1: Qualität der Clusterung bewerten
Prüfen Sie zuerst, ob die Cluster wie erwartet aussehen und ob Beispiele, die Sie für ähnlich halten, im selben Cluster erscheinen.
Sehen Sie sich dann die folgenden häufig verwendeten Messwerte an (nicht vollständig):
- Clusterkardinalität
- Cluster magnitude
- Downstream-Leistung
Clusterkardinalität
Die Clusterkardinalität ist die Anzahl der Beispiele pro Cluster. Stellen Sie die Clusterkardinalität für alle Cluster dar und untersuchen Sie Cluster, die große Ausreißer sind. In Abbildung 2 wäre das Cluster 5.
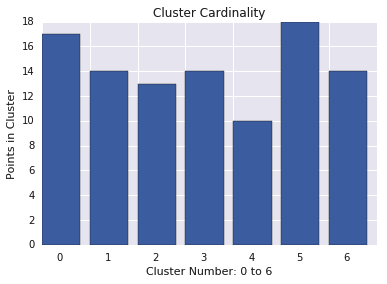
Cluster magnitude
Die Clustergröße ist die Summe der Entfernungen aller Beispiele in einem Cluster zum Clustermittelpunkt. Clustermagnitude für alle Cluster darstellen und Ausreißer untersuchen In Abbildung 3 ist Cluster 0 ein Ausreißer.
Sie können sich auch die maximale oder durchschnittliche Entfernung von Beispielen zu den Clusterschwerpunkten ansehen, um Ausreißer zu finden.
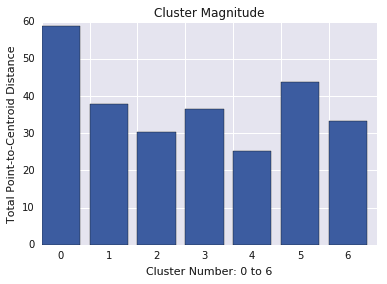
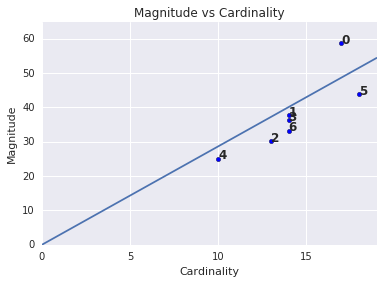
Umfang im Vergleich zur Kardinalität
Sie haben vielleicht bemerkt, dass einer höheren Clusterkardinalität eine höhere Clustermagnitude entspricht. Das ist intuitiv verständlich, da je mehr Punkte in einem Cluster vorhanden sind (Kardinalität), desto wahrscheinlicher ist die Summe der Entfernungen dieser Punkte vom Centroid (Magnitude). Sie können auch anormale Cluster identifizieren, indem Sie nach Clustern suchen, bei denen sich diese Beziehung zwischen Kardinalität und Größe stark von anderen Clustern unterscheidet. In Abbildung 4 wird durch die Anpassung einer Linie an das Diagramm mit Kardinalität und Größe angedeutet, dass Cluster 0 anormal ist. Cluster 5 ist ebenfalls weit von der Linie entfernt, aber wenn Cluster 0 weggelassen würde, wäre die neue angepasste Linie viel näher an Cluster 5.
Downstream-Leistung
Da Clustering-Ausgaben häufig in nachgelagerten ML-Systemen verwendet werden, sollten Sie prüfen, ob sich die Leistung des nachgelagerten Modells verbessert, wenn Sie den Clustering-Prozess ändern. Dies bietet eine realistische Bewertung der Qualität Ihrer Clusterergebnisse. Allerdings kann die Durchführung dieser Art von Test komplex und teuer sein.
Schritt 2: Ähnlichkeitsmessung noch einmal bewerten
Ihr Clustering-Algorithmus ist nur so gut wie Ihr Ähnlichkeitsmaß. Achten Sie darauf, dass Ihr Ähnlichkeitsmaß sinnvolle Ergebnisse liefert. Eine schnelle Prüfung besteht darin, Beispielpaare zu identifizieren, die bekanntermaßen mehr oder weniger ähnlich sind. Berechnen Sie den Ähnlichkeitsmaßstab für jedes Beispielpaar und vergleichen Sie Ihre Ergebnisse mit Ihrem Wissen: Paare ähnlicher Beispiele sollten einen höheren Ähnlichkeitsmaßstab haben als Paare ähnlicher Beispiele.
Die Beispiele, die Sie für die Stichprobenerhebung Ihres Ähnlichkeitsmaßes verwenden, sollten repräsentativ für den Datensatz sein, damit Sie sicher sein können, dass Ihr Ähnlichkeitsmaß für alle Beispiele gilt. Die Leistung Ihres Ähnlichkeitsmaßes, ob manuell oder mit beaufsichtigtem Lernen, muss für den gesamten Datensatz einheitlich sein. Wenn Ihr Ähnlichkeitsmaß für einige Beispiele nicht konsistent ist, werden diese Beispiele nicht mit ähnlichen Beispielen gruppiert.
Wenn Sie Beispiele mit ungenauen Ähnlichkeitswerten finden, erfasst Ihr Ähnlichkeitsmaß wahrscheinlich nicht vollständig die Merkmaldaten, anhand derer sich diese Beispiele unterscheiden. Experimentieren Sie mit dem Ähnlichkeitsmaß, bis genauere und konsistentere Ergebnisse zurückgegeben werden.
Schritt 3: Optimale Anzahl von Clustern ermitteln
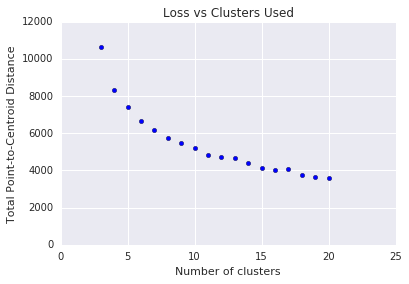
Beim K-Means-Clustering müssen Sie die Anzahl der Cluster \(k\) vorab festlegen. Wie ermitteln Sie die optimale \(k\)? Führen Sie den Algorithmus mit steigenden Werten für \(k\) aus und notieren Sie sich die Summe aller Clustermagnituden. Je höher\(k\) ist, desto kleiner werden die Cluster und die Gesamtdistanz der Punkte zu den Centroiden nimmt ab. Wir können diese Gesamtdistanz als Verlust behandeln. Plotten Sie diese Entfernung in Bezug auf die Anzahl der Cluster.
Wie in Abbildung 5 dargestellt, wird die Verlustminderung bei einem bestimmten Wert von \(k\)mit zunehmender \(k\)nur noch marginal. Sie können auch den \(k\)verwenden, an dem die Steigung zuerst drastisch zunimmt. Diese Methode wird auch als Ellenbogenmethode bezeichnet. Für den dargestellten Plot ist die optimale \(k\) etwa 11. Wenn Sie detailliertere Cluster bevorzugen, können Sie anhand dieses Diagramms eine höhere \(k\)auswählen.
Fragen zur Fehlerbehebung
Wenn Sie im Laufe Ihrer Bewertung Probleme feststellen, überprüfen Sie die Schritte zur Datenvorbereitung und das ausgewählte Ähnlichkeitsmaß noch einmal. Frag Folgendes:
- Sind Ihre Daten richtig skaliert?
- Ist Ihr Ähnlichkeitsmaß korrekt?
- Führt Ihr Algorithmus semantisch sinnvolle Vorgänge auf den Daten aus?
- Stimmen die Annahmen Ihres Algorithmus mit den Daten überein?