Debido a que el agrupamiento no está supervisado, no hay verdad fundamental disponible para verificar los resultados. La ausencia de verdad complica las evaluaciones de calidad. Además, los conjuntos de datos del mundo real suelen no ofrecer grupos obvios de ejemplos, como en el ejemplo que se muestra en la Figura 1.
En cambio, los datos del mundo real suelen parecerse más a la Figura 2, lo que dificulta la evaluación visual de la calidad del agrupamiento.
Sin embargo, existen heurísticas y prácticas recomendadas que puedes aplicar de forma iterativa para mejorar la calidad de tu agrupamiento. En el siguiente diagrama de flujo, se proporciona una descripción general de cómo evaluar los resultados del agrupamiento. Analizaremos cada paso.

Paso 1: Evalúa la calidad del agrupamiento
Primero, verifica que los clústeres se vean como esperas y que los ejemplos que consideres similares aparezcan en el mismo clúster.
Luego, consulta estas métricas de uso general (no es una lista exhaustiva):
- Cardinalidad del clúster
- Magnitud del clúster
- Rendimiento descendente
Cardinalidad del clúster
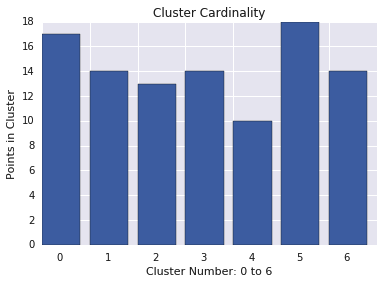
La cardinalidad del clúster es la cantidad de ejemplos por clúster. Grafica la cardinalidad del clúster para todos los clústeres y, luego, investiga los clústeres que sean valores atípicos importantes. En la Figura 2, este sería el clúster 5.
Magnitud del clúster
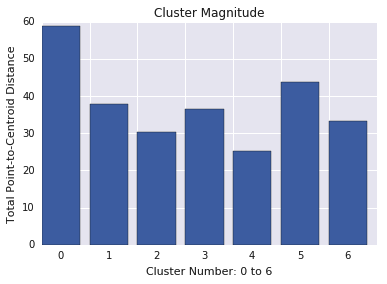
La magnitud del clúster es la suma de las distancias de todos los ejemplos de un clúster al centroide del clúster. Grafica la magnitud del clúster para todos los clústeres y, luego, investiga los valores atípicos. En la Figura 3, el clúster 0 es un valor atípico.
También considera observar la distancia máxima o promedio de los ejemplos de los centroides, por clúster, para encontrar valores atípicos.
Magnitud en comparación con la cardinalidad
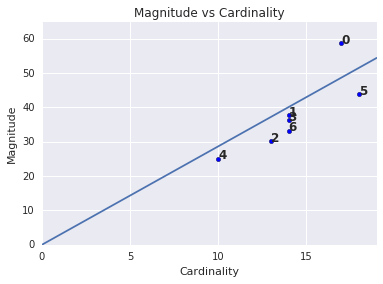
Es posible que hayas notado que una mayor cardinalidad del clúster corresponde a una magnitud del clúster más alta, lo que tiene sentido intuitivo, ya que cuantos más puntos haya en un clúster (cardinalidad), mayor será la suma probable de las distancias de esos puntos desde el centroide (magnitud). También puedes identificar clústeres anómalos si buscas aquellos en los que esta relación entre cardinalidad y magnitud es muy diferente a la de otros clústeres. En la Figura 4, ajustar una línea al diagrama de cardinalidad y magnitud sugiere que el clúster 0 es anómalo. (El clúster 5 también está lejos de la línea, pero si se omite el clúster 0, la nueva línea ajustada estaría mucho más cerca del clúster 5).
Rendimiento descendente
Dado que los resultados del agrupamiento a menudo se usan en sistemas de AA descendentes, comprueba si el rendimiento del modelo descendente mejora cuando cambia el proceso de agrupamiento. Esto ofrece una evaluación real de la calidad de los resultados de tu agrupamiento, aunque puede ser complejo y costoso realizar este tipo de prueba.
Paso 2: Vuelve a evaluar tu medida de similitud
La calidad de tu algoritmo de agrupamiento depende de la medida de similitud. Asegúrate de que tu medida de similitud devuelva resultados razonables. Una verificación rápida es identificar pares de ejemplos que se sabe que son más o menos similares. Calcula la medida de similitud para cada par de ejemplos y compara los resultados con tu conocimiento: los pares de ejemplos similares deben tener una medida de similitud más alta que los pares de ejemplos disímiles.
Los ejemplos que uses para verificar tu medida de similitud deben ser representativos del conjunto de datos, de modo que puedas confiar en que tu medida de similitud se mantiene para todos tus ejemplos. El rendimiento de tu medida de similitud, ya sea manual o supervisada, debe ser coherente en todo el conjunto de datos. Si tu medida de similitud no es coherente para algunos ejemplos, esos ejemplos no se agruparán con ejemplos similares.
Si encuentras ejemplos con puntuaciones de similitud imprecisas, es probable que tu medida de similitud no capture por completo los datos de atributos que distinguen esos ejemplos. Experimenta con tu medida de similitud hasta que devuelva resultados más precisos y coherentes.
Paso 3: Encuentra la cantidad óptima de clústeres
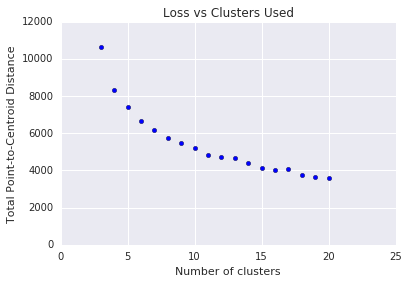
El algoritmo k-means requiere que decidas la cantidad de clústeres \(k\) de antemano. ¿Cómo determinas un \(k\)óptimo? Intenta ejecutar el algoritmo con valores crecientes de \(k\) y anota la suma de todas las magnitudes del clúster. A medida que\(k\) aumenta, los clústeres se vuelven más pequeños y la distancia total de los puntos de los centroides disminuye. Podemos tratar esta distancia total como una pérdida. Grafica esta distancia en función de la cantidad de clústeres.
Como se muestra en la Figura 5, por encima de un cierto \(k\), la reducción de la pérdida se vuelve marginal a medida que aumenta \(k\). Considera usar el \(k\) en el que la pendiente tiene un cambio drástico por primera vez, lo que se denomina método del codo. Para el diagrama que se muestra, el valor óptimo de \(k\) es de aproximadamente 11. Si prefieres clústeres más detallados, puedes elegir un \(k\)más alto consultando este gráfico.
Preguntas para solucionar problemas
Si descubres problemas durante la evaluación, vuelve a evaluar los pasos de preparación de datos y la medida de similitud que elegiste. Pregunta:
- ¿Tus datos se escalaron de forma adecuada?
- ¿Tu medida de similitud es correcta?
- ¿Tu algoritmo realiza operaciones semánticamente significativas en los datos?
- ¿Las suposiciones de tu algoritmo coinciden con los datos?