เนื่องจากเป็นการจัดกลุ่มแบบไม่ควบคุม จึงไม่มีข้อมูลจริงที่จะใช้ยืนยันผลลัพธ์ การไม่มีความจริงทำให้การประเมินคุณภาพมีความซับซ้อน นอกจากนี้ ชุดข้อมูลในชีวิตจริงมักจะไม่มีกลุ่มตัวอย่างที่ชัดเจนดังตัวอย่างที่แสดงในรูปที่ 1
แต่ข้อมูลในชีวิตจริงมักจะมีลักษณะคล้ายกับรูปที่ 2 มากกว่า ซึ่งทำให้ประเมินคุณภาพการคลัสเตอร์ด้วยภาพได้ยาก
อย่างไรก็ตาม ยังมีวิธีการแก้ปัญหาแบบเฮuristic และแนวทางปฏิบัติแนะนำที่คุณนําไปใช้ซ้ำๆ ได้เพื่อปรับปรุงคุณภาพของการจัดกลุ่ม แผนภาพต่อไปนี้แสดงภาพรวมของวิธีประเมินผลลัพธ์การจัดกลุ่ม เราจะอธิบายแต่ละขั้นตอนเพิ่มเติม

ขั้นตอนที่ 1: ประเมินคุณภาพของการจัดกลุ่ม
ก่อนอื่น ให้ตรวจสอบว่าคลัสเตอร์มีลักษณะตามที่คาดไว้ และตัวอย่างที่คุณคิดว่าคล้ายกันปรากฏในคลัสเตอร์เดียวกัน
จากนั้นตรวจสอบเมตริกที่ใช้กันโดยทั่วไปต่อไปนี้ (ไม่ใช่รายการที่ครอบคลุมทั้งหมด)
- Cardinality ของคลัสเตอร์
- ขนาดของคลัสเตอร์
- ประสิทธิภาพดาวน์สตรีม
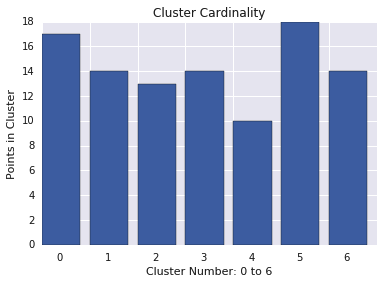
Cardinality ของคลัสเตอร์
Cardinality ของคลัสเตอร์คือจํานวนตัวอย่างต่อคลัสเตอร์ แสดงผังการ์ดัลลิตีของคลัสเตอร์สําหรับคลัสเตอร์ทั้งหมดและตรวจสอบคลัสเตอร์ที่เป็นค่าเบี่ยงเบนหลัก ในรูปที่ 2 จะเป็นคลัสเตอร์ 5
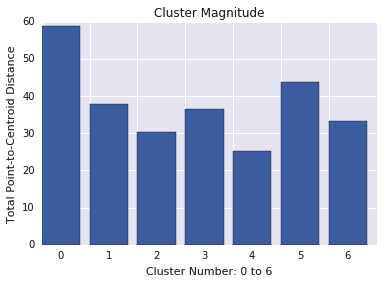
ขนาดของคลัสเตอร์
ขนาดของคลัสเตอร์คือผลรวมของระยะทางจากตัวอย่างทั้งหมดในคลัสเตอร์ไปจนถึงจุดศูนย์กลางของคลัสเตอร์ แสดงภาพความสำคัญของคลัสเตอร์สําหรับคลัสเตอร์ทั้งหมดและตรวจสอบค่าที่ผิดปกติ ในรูปที่ 3 คลัสเตอร์ 0 คือค่าผิดปกติ
นอกจากนี้ ให้พิจารณาดูระยะทางสูงสุดหรือค่าเฉลี่ยของตัวอย่างจากจุดศูนย์กลางตามคลัสเตอร์เพื่อหาค่าผิดปกติ
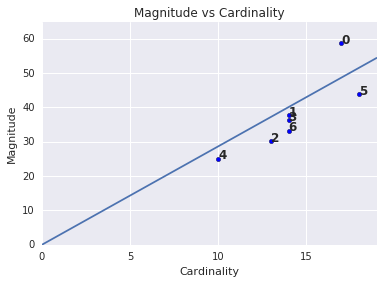
แมกนิจูดเทียบกับ Cardinality
คุณอาจสังเกตเห็นว่า Cardinality ของคลัสเตอร์ที่สูงขึ้นจะสอดคล้องกับขนาดของคลัสเตอร์ที่สูงขึ้น ซึ่งเป็นสิ่งที่เข้าใจได้ง่าย เนื่องจากยิ่งมีจุดในคลัสเตอร์ (Cardinality) มากเท่าใด ผลรวมของระยะทางที่เป็นไปได้ของจุดเหล่านั้นจากจุดศูนย์กลาง (ขนาด) ก็จะยิ่งมากขึ้นเท่านั้น นอกจากนี้ คุณยังระบุคลัสเตอร์ที่ผิดปกติได้ด้วย โดยมองหาคลัสเตอร์ที่ความสัมพันธ์ระหว่าง Cardinality กับ Magnitude แตกต่างอย่างมากกับคลัสเตอร์อื่นๆ ในรูปที่ 4 การปรับเส้นให้พอดีกับผัง Cardinality และ Magnitude ชี้ว่าคลัสเตอร์ 0 ผิดปกติ (คลัสเตอร์ 5 ก็อยู่ห่างจากเส้นเช่นกัน แต่หากไม่รวมคลัสเตอร์ 0 เส้นใหม่ที่ได้จากการประมาณจะใกล้กับคลัสเตอร์ 5 มากขึ้น)
ประสิทธิภาพดาวน์สตรีม
เนื่องจากเอาต์พุตการคลัสเตอร์มักใช้ในระบบ ML ดาวน์สตรีม ให้ดูว่าประสิทธิภาพของโมเดลดาวน์สตรีมดีขึ้นหรือไม่เมื่อกระบวนการจัดกลุ่มมีการเปลี่ยนแปลง ซึ่งจะประเมินคุณภาพของผลลัพธ์การคลัสเตอร์ตามสถานการณ์จริง แม้ว่าการทดสอบประเภทนี้อาจมีความซับซ้อนและค่าใช้จ่ายสูง
ขั้นตอนที่ 2: ประเมินการวัดความคล้ายคลึงอีกครั้ง
อัลกอริทึมการจัดกลุ่มจะทำงานได้ดีเพียงใดนั้นขึ้นอยู่กับการวัดความคล้ายคลึง ตรวจสอบว่าค่าการวัดความคล้ายคลึงให้ผลลัพธ์ที่สมเหตุสมผล วิธีตรวจสอบอย่างรวดเร็วคือระบุคู่ตัวอย่างที่ทราบว่ามีความคล้ายคลึงกันมากหรือน้อย คํานวณการวัดความคล้ายคลึงของคู่ตัวอย่างแต่ละคู่ แล้วเปรียบเทียบผลลัพธ์กับความรู้ของคุณ คู่ตัวอย่างที่คล้ายกันควรมีการวัดความคล้ายคลึงสูงกว่าคู่ตัวอย่างที่ไม่คล้ายกัน
ตัวอย่างที่คุณใช้เพื่อตรวจสอบตัวอย่างการวัดความคล้ายคลึงควรเป็นตัวแทนของชุดข้อมูล เพื่อให้คุณมั่นใจได้ว่าการวัดความคล้ายคลึงของคุณใช้ได้กับตัวอย่างทั้งหมด ประสิทธิภาพของวิธีการวัดความคล้ายคลึง ไม่ว่าจะเป็นแบบควบคุมดูแลหรือแบบดำเนินการด้วยตนเอง จะต้องสอดคล้องกันทั่วทั้งชุดข้อมูล หากการวัดความคล้ายคลึงไม่สอดคล้องกันสำหรับตัวอย่างบางรายการ ตัวอย่างเหล่านั้นจะไม่จัดกลุ่มกับตัวอย่างที่คล้ายกัน
หากพบตัวอย่างที่มีคะแนนความคล้ายคลึงไม่ถูกต้อง แสดงว่าเมตริกความคล้ายคลึงอาจไม่ได้บันทึกข้อมูลฟีเจอร์ที่แยกแยะตัวอย่างเหล่านั้นอย่างครบถ้วน ทดสอบการวัดความคล้ายคลึงจนกว่าจะให้ผลลัพธ์ที่แม่นยำและสอดคล้องกันมากขึ้น
ขั้นตอนที่ 3: ค้นหาจํานวนคลัสเตอร์ที่เหมาะสม
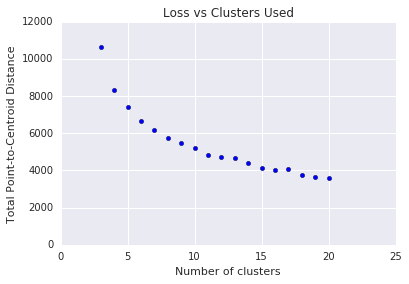
K-means กำหนดให้คุณต้องตัดสินใจเลือกจำนวนคลัสเตอร์ \(k\) ล่วงหน้า คุณกำหนด \(k\)ที่เหมาะสมได้อย่างไร ลองเรียกใช้อัลกอริทึมโดยเพิ่มค่า \(k\) และจดจําผลรวมของขนาดคลัสเตอร์ทั้งหมด เมื่อ\(k\) เพิ่มขึ้น คลัสเตอร์จะเล็กลง และระยะทางรวมของจุดจากจุดศูนย์กลางจะลดลง เราอาจถือว่าระยะทางทั้งหมดนี้เป็น "การสูญเสีย" วางผังระยะทางนี้เทียบกับจํานวนคลัสเตอร์
ดังที่แสดงในรูปที่ 5 \(k\)ที่สูงกว่าระดับหนึ่ง การลดการสูญเสียจะลดลงเมื่อ \(k\)เพิ่มขึ้น ลองใช้ \(k\) จุดที่ความชันมีการเปลี่ยนแปลงอย่างมากเป็นครั้งแรก ซึ่งเรียกว่าวิธีการโค้ง สําหรับผังข้อมูลที่แสดง \(k\) ที่เหมาะสมคือประมาณ 11 หากต้องการคลัสเตอร์ที่ละเอียดยิ่งขึ้น ให้เลือก \(k\)ที่สูงขึ้นโดยดูจากผังนี้
คำถามเกี่ยวกับการแก้ปัญหา
หากพบปัญหาระหว่างการประเมิน ให้ประเมินขั้นตอนการเตรียมข้อมูลและการวัดความคล้ายคลึงที่คุณเลือกอีกครั้ง คำถาม:
- ข้อมูลได้รับการปรับขนาดอย่างเหมาะสมหรือไม่
- การวัดความคล้ายคลึงถูกต้องไหม
- อัลกอริทึมของคุณดำเนินการที่มีความหมายเชิงความหมายกับข้อมูลหรือไม่
- สมมติฐานของอัลกอริทึมตรงกับข้อมูลไหม