Karena pengelompokan tidak diawasi, tidak ada kebenaran dasar yang tersedia untuk memverifikasi hasil. Ketidakadaan kebenaran mempersulit penilaian kualitas. Selain itu, set data dunia nyata biasanya tidak menawarkan cluster contoh yang jelas seperti pada contoh yang ditampilkan dalam Gambar 1.
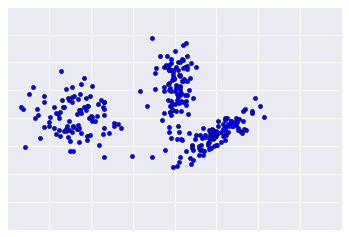
Sebaliknya, data dunia nyata sering kali terlihat lebih seperti Gambar 2, sehingga sulit untuk menilai kualitas pengelompokan secara visual.
Namun, ada heuristik dan praktik terbaik yang dapat Anda terapkan secara iteratif untuk meningkatkan kualitas pengelompokan. Diagram alir berikut memberikan ringkasan tentang cara mengevaluasi hasil pengelompokan Anda. Kita akan membahas setiap langkah.

Langkah 1: Menilai kualitas pengelompokan
Pertama, pastikan cluster terlihat seperti yang Anda harapkan, dan contoh yang Anda anggap mirip satu sama lain muncul dalam cluster yang sama.
Kemudian, periksa metrik yang umum digunakan ini (bukan daftar lengkap):
- Kardinalitas cluster
- Magnitudo cluster
- Performa downstream
Kardinalitas cluster
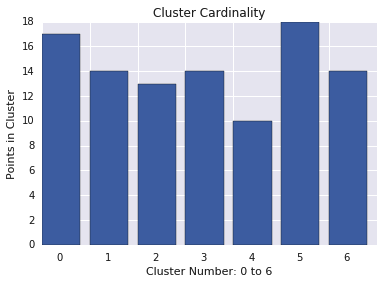
Kardinalitas cluster adalah jumlah contoh per cluster. Buat plot kardinalitas cluster untuk semua cluster dan selidiki cluster yang merupakan outlier utama. Dalam Gambar 2, ini adalah cluster 5.
Magnitudo cluster
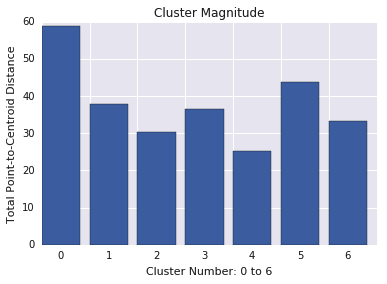
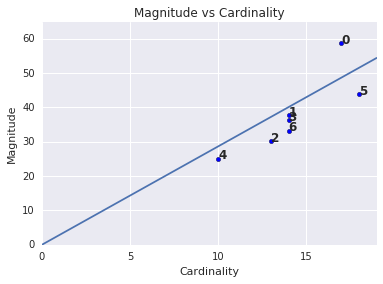
Magnit cluster adalah jumlah jarak dari semua contoh dalam cluster ke centroid cluster. Buat plot magnitudo cluster untuk semua cluster dan selidiki outlier. Pada Gambar 3, cluster 0 adalah outlier.
Pertimbangkan juga untuk melihat jarak maksimum atau rata-rata contoh dari centroid, menurut cluster, untuk menemukan outlier.
Magnitudo versus kardinalitas
Anda mungkin telah memperhatikan bahwa kardinalitas cluster yang lebih tinggi sesuai dengan magnitudo cluster yang lebih tinggi, yang masuk akal secara intuitif, karena semakin banyak titik dalam cluster (kardinalitas), semakin besar kemungkinan jumlah jarak titik tersebut dari centroid (magnitudo). Anda juga dapat mengidentifikasi cluster anomali dengan mencari cluster yang hubungan antara kardinalitas dan magnitudonya sangat berbeda dengan cluster lainnya. Pada Gambar 4, penyesuaian garis ke plot kardinalitas dan magnitudo menunjukkan bahwa cluster 0 bersifat anomali. (Cluster 5 juga jauh dari garis, tetapi jika cluster 0 dihilangkan, garis baru yang dipasang akan jauh lebih dekat dengan cluster 5.)
Performa downstream
Karena output pengelompokan sering digunakan dalam sistem ML downstream, lihat apakah performa model downstream meningkat saat proses pengelompokan Anda berubah. Hal ini menawarkan evaluasi dunia nyata tentang kualitas hasil pengelompokan Anda, meskipun pengujian semacam ini dapat menjadi rumit dan mahal.
Langkah 2: Evaluasi ulang ukuran kesamaan Anda
Algoritma pengelompokan Anda hanya sebagus pengukuran kemiripan Anda. Pastikan pengukuran kemiripan Anda menampilkan hasil yang masuk akal. Pemeriksaan cepatnya adalah mengidentifikasi pasangan contoh yang diketahui kurang lebih serupa. Hitung ukuran kesamaan untuk setiap pasangan contoh, dan bandingkan hasilnya dengan pengetahuan Anda: pasangan contoh yang serupa harus memiliki ukuran kesamaan yang lebih tinggi daripada pasangan contoh yang tidak serupa.
Contoh yang Anda gunakan untuk memeriksa sekilas pengukuran kemiripan harus mewakili set data, sehingga Anda dapat yakin bahwa pengukuran kemiripan berlaku untuk semua contoh. Performa pengukuran kesamaan, baik manual maupun terpantau, harus konsisten di seluruh set data Anda. Jika pengukuran kemiripan Anda tidak konsisten untuk beberapa contoh, contoh tersebut tidak akan dikelompokkan dengan contoh yang serupa.
Jika Anda menemukan contoh dengan skor kemiripan yang tidak akurat, pengukuran kemiripan Anda mungkin tidak sepenuhnya menangkap data fitur yang membedakan contoh tersebut. Lakukan eksperimen dengan ukuran kemiripan Anda hingga menampilkan hasil yang lebih akurat dan konsisten.
Langkah 3: Temukan jumlah cluster yang optimal
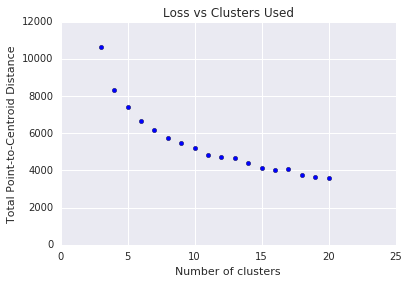
k-means mengharuskan Anda menentukan jumlah cluster \(k\) terlebih dahulu. Bagaimana cara menentukan \(k\)yang optimal? Coba jalankan algoritma dengan meningkatkan nilai \(k\) dan catat jumlah semua magnitudo cluster. Seiring \(k\) meningkat, cluster menjadi lebih kecil, dan total jarak titik dari centroid menurun. Kita dapat memperlakukan jarak total ini sebagai kerugian. Buat plot jarak ini terhadap jumlah cluster.
Seperti yang ditunjukkan pada Gambar 5, di atas \(k\)tertentu, pengurangan kerugian menjadi marginal dengan meningkatnya \(k\). Pertimbangkan untuk menggunakan \(k\) saat kemiringan pertama kali mengalami perubahan drastis, yang disebut metode siku. Untuk plot yang ditampilkan, \(k\) optimalnya adalah sekitar 11. Jika lebih memilih cluster yang lebih terperinci, Anda dapat memilih \(k\)yang lebih tinggi, dengan melihat plot ini.
Pertanyaan pemecahan masalah
Jika Anda menemukan masalah selama evaluasi, tinjau kembali langkah-langkah persiapan data dan pengukuran kemiripan yang dipilih. Tanyakan:
- Apakah data Anda diskalakan dengan tepat?
- Apakah ukuran kesamaan Anda sudah benar?
- Apakah algoritma Anda melakukan operasi yang bermakna secara semantik pada data?
- Apakah asumsi algoritma Anda cocok dengan data?