Поскольку кластеризация не контролируется, нет достоверных данных для проверки результатов. Отсутствие истины усложняет оценку качества. Более того, реальные наборы данных обычно не содержат очевидных кластеров примеров, как в примере, показанном на рисунке 1.
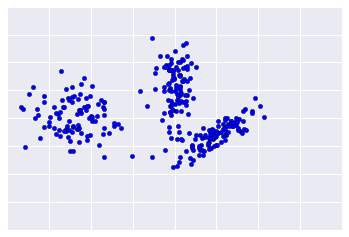
Вместо этого реальные данные часто больше похожи на рисунок 2, что затрудняет визуальную оценку качества кластеризации.
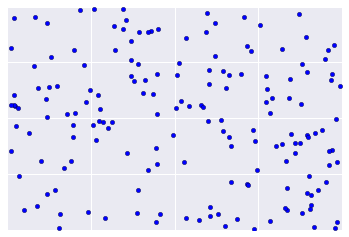
Однако существуют эвристики и лучшие практики, которые можно итеративно применять для улучшения качества кластеризации. На следующей блок-схеме представлен обзор того, как оценить результаты кластеризации. Мы остановимся на каждом шаге.

Шаг 1. Оцените качество кластеризации
Сначала убедитесь, что кластеры выглядят так, как вы ожидаете, и что примеры, которые вы считаете похожими друг на друга, находятся в одном кластере.
Затем проверьте эти часто используемые показатели (не исчерпывающий список):
- Мощность кластера
- Величина кластера
- Производительность после переработки
Мощность кластера
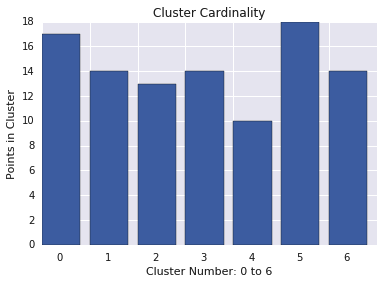
Мощность кластера — это количество примеров в кластере. Постройте мощность кластера для всех кластеров и исследуйте кластеры, которые являются основными выбросами. На рисунке 2 это будет кластер 5.
Величина кластера
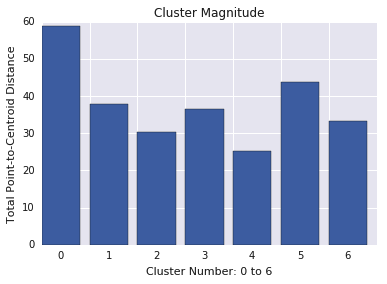
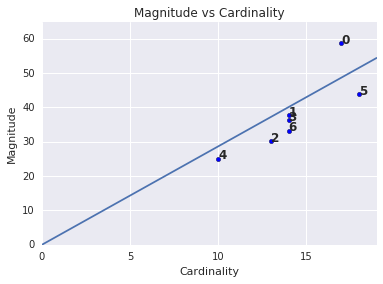
Величина кластера — это сумма расстояний от всех примеров в кластере до центроида кластера. Постройте величину кластера для всех кластеров и исследуйте выбросы. На рисунке 3 кластер 0 является выбросом.
Также рассмотрите возможность просмотра максимального или среднего расстояния примеров от центроидов по кластерам, чтобы найти выбросы.
Величина против мощности
Возможно, вы заметили, что более высокая мощность кластера соответствует более высокой величине кластера, что имеет интуитивно понятный смысл, поскольку чем больше точек в кластере (мощность), тем больше вероятная сумма расстояний этих точек от центроида (амплитуда). Вы также можете идентифицировать аномальные кластеры, ища те, в которых соотношение между мощностью и величиной сильно отличается от других кластеров. На рисунке 4 соответствие линии графику мощности и величины предполагает, что кластер 0 является аномальным. (Кластер 5 также находится далеко от линии, но если бы кластер 0 был опущен, новая подобранная линия была бы намного ближе к кластеру 5.)
Производительность после переработки
Поскольку результаты кластеризации часто используются в последующих системах машинного обучения, посмотрите, улучшится ли производительность последующих моделей при изменении процесса кластеризации. Это дает реальную оценку качества результатов кластеризации, хотя проведение такого рода тестов может оказаться сложным и дорогостоящим.
Шаг 2. Переоцените свою меру сходства
Ваш алгоритм кластеризации настолько хорош, насколько хороша ваша мера сходства. Убедитесь, что ваша мера сходства дает разумные результаты. Быстрая проверка заключается в выявлении пар примеров, которые, как известно, более или менее похожи. Рассчитайте меру сходства для каждой пары примеров и сравните полученные результаты со своими знаниями: пары похожих примеров должны иметь более высокую меру сходства, чем пары несходных примеров.
Примеры, которые вы используете для выборочной проверки меры сходства, должны быть репрезентативными для набора данных, чтобы вы могли быть уверены, что ваша мера сходства справедлива для всех ваших примеров. Производительность вашей меры сходства, будь то ручная или контролируемая, должна быть одинаковой во всем вашем наборе данных. Если ваша мера сходства несовместима для некоторых примеров, эти примеры не будут кластеризованы с похожими примерами.
Если вы обнаружите примеры с неточными показателями сходства, то ваша мера сходства, вероятно, не полностью отражает данные о признаках, которые отличают эти примеры. Поэкспериментируйте с мерой сходства, пока она не даст более точные и последовательные результаты.
Шаг 3. Найдите оптимальное количество кластеров
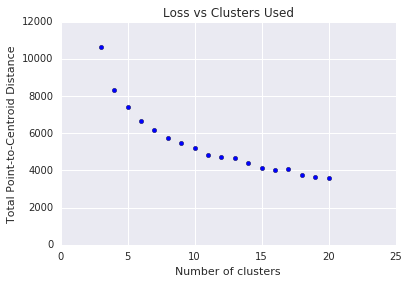
k-means требует от вас определить количество кластеров \(k\) заранее. Как определить оптимальный \(k\)? Попробуйте запустить алгоритм с увеличением значений \(k\) и обратите внимание на сумму всех величин кластера. Как\(k\) увеличивается, кластеры становятся меньше, а общее расстояние точек от центроидов уменьшается. Мы можем рассматривать это общее расстояние как потерю. Постройте график этого расстояния в зависимости от количества кластеров.
Как показано на рисунке 5, выше определенного \(k\), снижение потерь становится незначительным с увеличением \(k\). Рассмотрите возможность использования \(k\)где наклон сначала резко меняется, что называется методом локтя . Для представленного графика оптимальным является \(k\) составляет примерно 11. Если вы предпочитаете более детальные кластеры, вы можете выбрать более высокое значение. \(k\), сверяясь с этим сюжетом.
Вопросы по устранению неполадок
Если вы обнаружите проблемы в ходе оценки, переоцените этапы подготовки данных и выбранную меру сходства. Просить:
- Правильно ли масштабированы ваши данные?
- Верна ли ваша мера сходства?
- Выполняет ли ваш алгоритм семантически значимые операции с данными?
- Соответствуют ли предположения вашего алгоритма данным?