クラスタリングは教師なしであるため、結果を検証するためのグラウンド トゥルースは使用できません。真実が存在しないため、品質の評価は複雑になります。さらに、通常、現実世界のデータセットには、図 1 の例のような明らかなサンプルクラスタはありません。
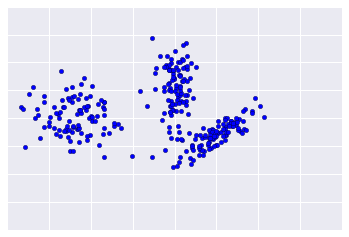
一方、実際のデータは図 2 のように見えることが多く、クラスタリング品質を視覚的に評価するのは困難です。
ただし、ヒューリスティックとベスト プラクティスを反復的に適用して、クラスタリング品質を改善できます。次のフローチャートは、クラスタリング結果を評価する方法の概要を示しています。各ステップについて詳しく説明します。

ステップ 1: クラスタリング品質を評価する
まず、クラスタが想定どおりに表示されていること、類似していると判断した例が同じクラスタに表示されていることを確認します。
次に、よく使用される指標を確認します(ただし、このリストは網羅的なものではありません)。
- クラスタのカーディナリティ
- クラスタの規模
- ダウンストリームのパフォーマンス
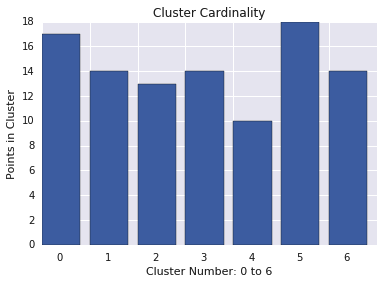
クラスタのカーディナリティ
クラスタの基数は、クラスタあたりの例の数です。すべてのクラスタのクラスタ カーディナリティをプロットし、主要な外れ値であるクラスタを調査します。図 2 では、これがクラスタ 5 です。
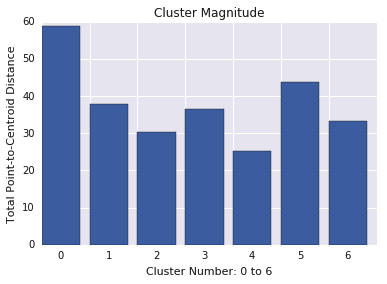
クラスタの規模
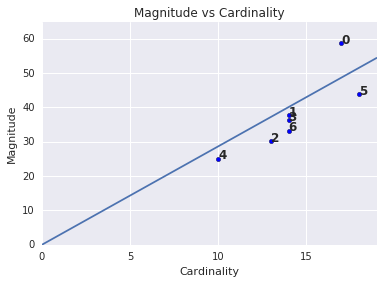
クラスタの振幅は、クラスタ内のすべての例からクラスタの重心までの距離の合計です。すべてのクラスタのクラスタの振幅をプロットし、外れ値を調査します。図 3 では、クラスタ 0 が外れ値です。
また、クラスタごとにセントロイドからのサンプルの最大距離または平均距離を確認して、外れ値を見つけることも検討してください。
マグニチュードとカーディナリティ
クラスタのカーディナリティが高いほどクラスタの振幅が大きくなることに気付いたかもしれません。これは直感的に理解できます。クラスタ内の点数(基数)が多いほど、その点から重心までの距離の合計(振幅)が大きくなるためです。基数と大きさの関係が他のクラスタと大きく異なるクラスタを見つけることで、異常なクラスタを特定することもできます。図 4 では、カーディナリティとマグニチュードのグラフに線を当てはめると、クラスタ 0 が異常であることが示唆されます。(クラスタ 5 も線から離れていますが、クラスタ 0 を除外すると、新しいフィッティング線はクラスタ 5 にかなり近づきます)。
ダウンストリームのパフォーマンス
クラスタリング出力はダウンストリームの ML システムでよく使用されるため、クラスタリング プロセスを変更したときにダウンストリーム モデルのパフォーマンスが向上するかどうかを確認します。これにより、クラスタリング結果の品質を実際の環境で評価できますが、この種のテストは複雑で費用もかかります。
ステップ 2: 類似性測定を再評価する
クラスタリング アルゴリズムの性能は、類似性測定によって決まります。類似性測定が妥当な結果を返すことを確認します。簡単なチェック方法として、ある程度類似していることが知られている例のペアを特定します。各サンプルペアの類似度を計算し、結果を知識と比較します。類似したサンプルペアは、類似していないサンプルペアよりも類似度が高いはずです。
類似性測定値のスポットチェックに使用するサンプルは、データセットを代表するものである必要があります。これにより、類似性測定値がすべてのサンプルに適用されることを確認できます。類似性測定のパフォーマンスは、手動または教師ありかにかかわらず、データセット全体で一貫している必要があります。類似性測定が一部のサンプルで不一致の場合、それらのサンプルは類似サンプルとクラスタ化されません。
類似性スコアが不正確な例が見つかった場合は、類似性測定がそれらの例を区別する特徴データを十分にキャプチャしていない可能性があります。より正確で一貫した結果が返されるまで、類似性測定値をテストします。
ステップ 3: 最適なクラスタ数を確認する
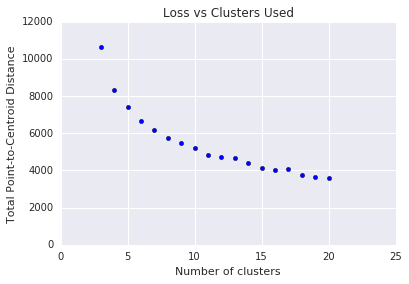
K 平均法では、クラスタの数を \(k\) 事前に決定する必要があります。最適な \(k\)をどのように決定しますか? \(k\) の値を増やしながらアルゴリズムを実行し、すべてのクラスタの振幅の合計をメモします。\(k\) が増加すると、クラスタは小さくなり、重心からのポイントの合計距離は短くなります。この合計距離は損失として扱うことができます。この距離をクラスタ数に対してプロットします。
図 5 に示すように、特定の \(k\)を超えると、 \(k\)の増加に伴う損失の減少はわずかになります。傾斜が最初に急激に変化する場所で \(k\)を使用することを検討してください。これはエルボー法と呼ばれます。表示されているプロットの場合、最適な \(k\) は約 11 です。より細かいクラスタが必要な場合は、このプロットを確認して、より大きな \(k\)を選択できます。
トラブルシューティングに関する質問
評価中に問題が見つかった場合は、データ準備の手順と選択した類似性測定を再評価します。質問:
- データは適切にスケーリングされていますか?
- 類似性測定は正しいですか?
- アルゴリズムは、データに対して意味的に意味のあるオペレーションを実行していますか?
- アルゴリズムの前提条件はデータと一致していますか?