لنفترض أنّك تعمل مع مجموعة بيانات تتضمّن معلومات المرضى من نظام الرعاية الصحية. مجموعة البيانات معقدة وتتضمّن كلًّا من السمات الفئوية والرقمية. إذا كنت تريد العثور على أنماط وأوجه تشابه في مجموعة البيانات كيف يمكنك التعامل مع هذه المَهمّة؟
التجميع هو أسلوب تعلُّم آلي غير موجّه مصمّم لتجميع عيّنات غير مصنّفة استنادًا إلى تشابهها مع بعضها. (إذا تم تصنيف الأمثلة، يُطلق على هذا النوع من التجميع اسم التصنيف). لنفترض أنّه تم إجراء دراسة افتراضية بشأن المريض بهدف تقييم بروتوكول علاجي جديد. خلال الدراسة، يُبلِغ المرضى عن عدد المرات التي يشعرون فيها بالأعراض في الأسبوع ومدى شدة الأعراض. يمكن للباحثين استخدام تحليل التجميع لتجميع المرضى الذين لديهم ردود مماثلة على العلاج في مجموعات. يوضّح الشكل 1 طريقة واحدة ممكنة لتجميع البيانات المحاكية في ثلاث مجموعات.
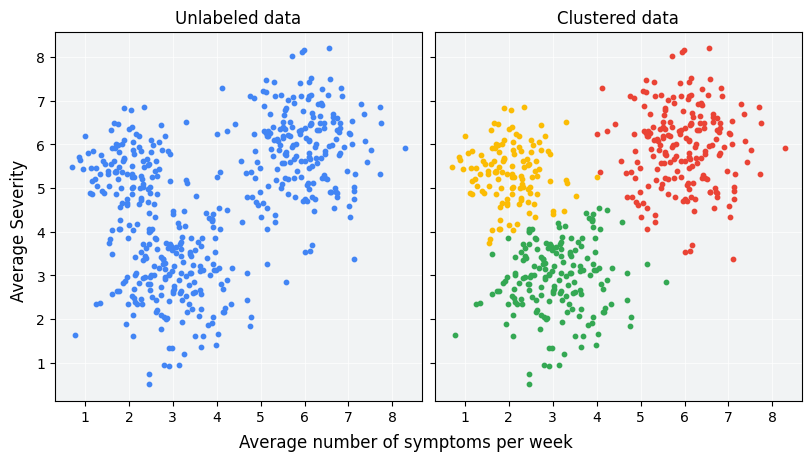
عند الاطّلاع على البيانات غير المصنّفة على يمين الشكل 1، يمكنك تخمين أنّه تشكل البيانات ثلاث مجموعات، حتى بدون تعريف رسمي للتشابه بين نقاط البيانات. في التطبيقات الواقعية، ومع ذلك، عليك تحديد مقياس التشابه أو المقياس المستخدَم لمقارنة العيّنات بشكل صريح، وذلك بالاستناد إلى ميزات مجموعة البيانات. عندما تحتوي الأمثلة على ميزتَين فقط، يكون من السهل تصور التشابه وقياسه. ولكن مع زيادة عدد العلامات ، يصبح دمج العلامات ومقارنتها أقل سهولة وأكثر تعقيدًا. قد تكون مقاييس التشابه المختلفة مناسبة بشكلٍ أكبر أو أقل لسيناريوهات التجميع المختلفة، وستتناول هذه الدورة التدريبية اختيار مقياس تشابه مناسب في الأقسام اللاحقة: مقاييس التشابه اليدوية و مقياس التشابه من عمليات التضمين.
بعد تجميع البيانات، يتمّ منح كلّ مجموعة تصنيفًا فريدًا يُعرَف باسم معرّف المجموعة. إنّ التجميع العنقودي هو إجراء فعّال لأنّه يمكنه تبسيط مجموعات البيانات الكبيرة والمعقدة التي تحتوي على العديد من السمات إلى معرّف مجموعة عنقودية واحد.
حالات استخدام التجميع
يُعدّ التجميع مفيدًا في مجموعة متنوعة من المجالات. في ما يلي بعض التطبيقات الشائعة للتجميع:
- تقسيم السوق
- تحليل الشبكات الاجتماعية
- تجميع نتائج البحث
- التصوير الطبي
- تقسيم الصور
- رصد القيم الشاذة
في ما يلي بعض الأمثلة المحدّدة على التجميع:
- يعرض مخطّط هرتزسبرنغ-روسل مجموعات من النجوم عند تمثيلها حسب اللمعان ودرجة الحرارة.
- أدّت تسلسلات الجينات التي تُظهر أوجه التشابه الجيني وعدم التشابه بين الأنواع والتي لم تكن معروفة من قبل إلى مراجعة التصنيفات التي كانت تستند في السابق إلى المظاهر.
- تم تطوير نموذج السمات الخمس الكبرى للشخصية من خلال تجميع الكلمات التي تصف الشخصية في 5 مجموعات. يستخدم نموذج HEXACO 6 مجموعات بدلاً من 5.
إسناد
عندما تكون بيانات العناصر غير متوفّرة لبعض النماذج في إحدى المجموعات، يمكنك استنتاج البيانات غير المتوفّرة من النماذج الأخرى في المجموعة. ويُعرف هذا باسم السمة المُحالة. على سبيل المثال، يمكن تجميع الفيديوهات الأقل رواجًا مع الفيديوهات الأكثر رواجًا لتحسين اقتراحات الفيديوهات.
ضغط البيانات
كما ناقشنا، يمكن أن يستبدل رقم تعريف المجموعة ذي الصلة الميزات الأخرى لجميع الأمثلة في تلك المجموعة. ويؤدي هذا الاستبدال إلى تقليل عدد السمات، وبالتالي إلى تقليل الموارد اللازمة لتخزين النماذج ومعالجتها وتدريبها استنادًا إلى هذه البيانات. بالنسبة إلى مجموعات البيانات الكبيرة جدًا، تصبح هذه التوفيرات كبيرة.
على سبيل المثال، يمكن أن يتضمّن فيديو واحد على YouTube بيانات ميزات تشمل ما يلي:
- الموقع الجغرافي للمشاهد والوقت والخصائص الديمغرافية
- الطوابع الزمنية للتعليقات ونصوصها وأرقام تعريف المستخدمين
- علامات الفيديو
عند تجميع فيديوهات YouTube، يتم استبدال هذه المجموعة من الميزات بأحد معرّفات المجموعات، ما يؤدي إلى ضغط البيانات.
الحفاظ على الخصوصية
يمكنك الحفاظ على الخصوصية إلى حدّ ما من خلال تجميع المستخدِمين وربط بيانات المستخدِمين بمعرّفات المجموعات بدلاً من معرّفات المستخدِمين. على سبيل المثال، لنفترض أنّك تريد تدريب نموذج على سجلّ مشاهدة مستخدمي YouTube. بدلاً من تمرير أرقام تعريف المستخدمين إلى النموذج، يمكنك تجميع المستخدمين وتمرير معرّف المجموعة فقط. ويؤدي ذلك إلى منع ربط سجلات المشاهدة الفردية بمستخدمين فرديين. يُرجى العلم أنّ المجموعة يجب أن تحتوي على عدد كبير بما يكفي من المستخدمين للحفاظ على الخصوصية.