Misalnya, Anda sedang menggunakan set data yang menyertakan informasi pasien dari sistem layanan kesehatan. Set data ini kompleks dan mencakup fitur kategoris dan numerik. Anda ingin menemukan pola dan kesamaan dalam set data. Bagaimana cara Anda menangani tugas ini?
Pengelompokan adalah teknik machine learning tanpa pengawasan yang dirancang untuk mengelompokkan contoh tanpa label berdasarkan kesamaannya satu sama lain. (Jika contoh diberi label, jenis pengelompokan ini disebut klasifikasi.) Pertimbangkan studi pasien hipotetis yang dirancang untuk mengevaluasi protokol pengobatan baru. Selama studi, pasien melaporkan frekuensi per minggu mereka mengalami gejala dan tingkat keparahan gejala. Peneliti dapat menggunakan analisis pengelompokan untuk mengelompokkan pasien dengan respons pengobatan yang serupa ke dalam cluster. Gambar 1 menunjukkan salah satu kemungkinan pengelompokan data simulasi menjadi tiga cluster.
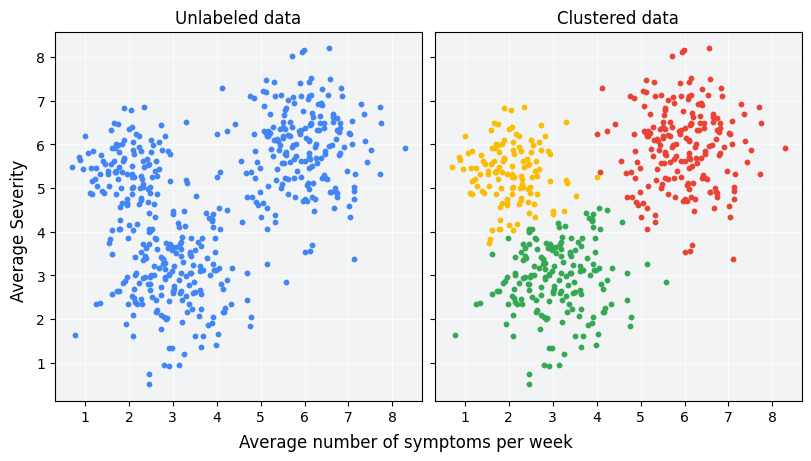
Melihat data tanpa label di sebelah kiri Gambar 1, Anda dapat menebak bahwa data membentuk tiga cluster, bahkan tanpa definisi formal kesamaan antara titik data. Namun, dalam aplikasi dunia nyata, Anda perlu menentukan ukuran kesamaan, atau metrik yang digunakan untuk membandingkan sampel, secara eksplisit, dalam hal fitur set data. Jika contoh hanya memiliki beberapa fitur, visualisasi dan pengukuran kesamaan akan mudah. Namun, seiring meningkatnya jumlah fitur, menggabungkan dan membandingkan fitur menjadi kurang intuitif dan lebih kompleks. Berbagai ukuran kesamaan mungkin lebih atau kurang sesuai untuk berbagai skenario pengelompokan, dan kursus ini akan membahas cara memilih ukuran kesamaan yang sesuai di bagian selanjutnya: Ukuran kesamaan manual dan Ukuran kesamaan dari penyematan.
Setelah pengelompokan, setiap grup diberi label unik yang disebut ID cluster. Pengelompokan sangat efektif karena dapat menyederhanakan set data besar dan kompleks dengan banyak fitur ke satu ID cluster.
Kasus penggunaan pengelompokan
Pengelompokan berguna di berbagai industri. Beberapa aplikasi umum untuk pengelompokan:
- Segmentasi pasar
- Analisis jaringan sosial
- Pengelompokan hasil penelusuran
- Pencitraan medis
- Segmentasi gambar
- Deteksi anomali
Beberapa contoh pengelompokan yang spesifik:
- Diagram Hertzsprung-Russell menampilkan cluster bintang saat diplot berdasarkan luminositas dan suhu.
- Urutan gen yang menunjukkan kesamaan dan perbedaan genetik yang sebelumnya tidak diketahui antara spesies telah menyebabkan revisi taksonomi yang sebelumnya didasarkan pada penampilan.
- Model Big 5 dari ciri kepribadian dikembangkan dengan mengelompokkan kata-kata yang menjelaskan kepribadian ke dalam 5 grup. Model HEXACO menggunakan 6 cluster, bukan 5.
Implikasi
Jika beberapa contoh dalam cluster tidak memiliki data fitur, Anda dapat menyimpulkan data yang hilang dari contoh lain dalam cluster. Tindakan ini disebut imputasi. Misalnya, video yang kurang populer dapat dikelompokkan dengan video yang lebih populer untuk meningkatkan kualitas rekomendasi video.
Kompresi data
Seperti yang telah dibahas, ID cluster yang relevan dapat menggantikan fitur lain untuk semua contoh dalam cluster tersebut. Penggantian ini mengurangi jumlah fitur, sehingga juga mengurangi resource yang diperlukan untuk menyimpan, memproses, dan melatih model pada data tersebut. Untuk set data yang sangat besar, penghematan ini menjadi signifikan.
Sebagai contoh, satu video YouTube dapat memiliki data fitur yang mencakup:
- lokasi, waktu, dan demografi penonton
- stempel waktu, teks, dan User-ID komentar
- tag video
Mengelompokkan video YouTube akan mengganti kumpulan fitur ini dengan satu ID cluster, sehingga data akan dikompresi.
Pemeliharaan privasi
Anda dapat menjaga privasi dengan mengelompokkan pengguna dan mengaitkan data pengguna dengan ID cluster, bukan ID pengguna. Untuk memberikan salah satu contoh, misalnya Anda ingin melatih model pada histori tontonan pengguna YouTube. Daripada meneruskan ID pengguna ke model, Anda dapat mengelompokkan pengguna dan hanya meneruskan ID cluster. Hal ini mencegah histori tontonan individu agar tidak dikaitkan dengan pengguna individu. Perhatikan bahwa cluster harus berisi pengguna dalam jumlah yang cukup besar untuk mempertahankan privasi.