医療システムの患者情報が含まれているデータセットを扱っているとします。このデータセットは複雑で、カテゴリ特徴と数値特徴の両方が含まれています。データセット内のパターンと類似点を探す。この課題にどう取り組むか
クラスタリングは、ラベルなしの例を相互の類似性に基づいてグループ化するように設計された教師なし ML 手法です。(例にラベルが付けられている場合、この種のグループ化は分類と呼ばれます)。新しい治療プロトコルを評価するために設計された仮想の患者調査について考えてみましょう。研究中、患者は症状が現れる頻度と症状の重症度を報告します。研究者はクラスタ分析を使用して、治療に対する反応が類似している患者をクラスタにグループ化できます。図 1 は、シミュレートされたデータを 3 つのクラスタにグループ化する 1 つの例を示しています。
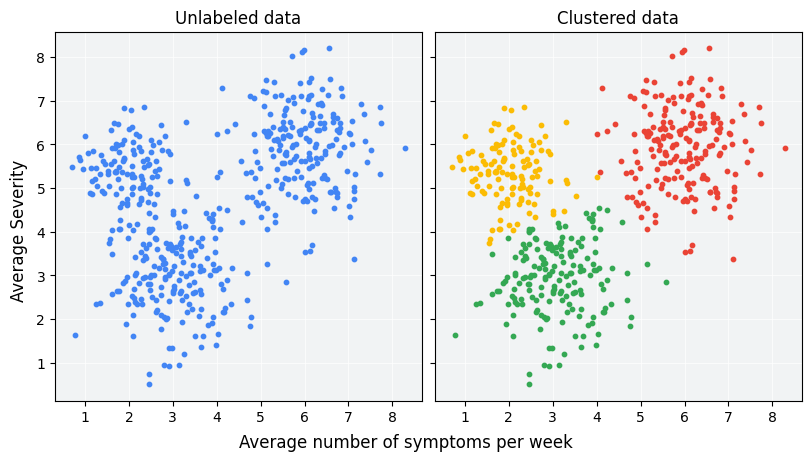
図 1 の左側のラベルなしデータを見て、データポイント間の類似性の正式な定義がなくても、データが 3 つのクラスタを形成していることを推測できます。ただし、実際のアプリケーションでは、データセットの特徴に基づいて類似性測定(サンプルの比較に使用される指標)を明示的に定義する必要があります。サンプルに含まれる特徴が 2 つしかない場合は、類似性を可視化して測定するのは簡単です。ただし、特徴の数が増えると、特徴の組み合わせと比較が直感的ではなくなり、複雑になります。クラスタリング シナリオによって、適切な類似性測定が異なります。このコースでは、後のセクションの手動の類似性測定とエンベディングからの類似性測定で、適切な類似性測定を選択する方法について説明します。
クラスタリング後、各グループにはクラスタ ID という一意のラベルが割り当てられます。クラスタリングは、多くの特徴を持つ大規模で複雑なデータセットを単一のクラスタ ID に簡素化できるため、強力です。
クラスタリングのユースケース
クラスタリングはさまざまな業界で役立ちます。クラスタリングに一般的なアプリケーション:
- 市場セグメンテーション
- ソーシャル ネットワーク分析
- 検索結果のグループ化
- 医用画像
- 画像セグメンテーション
- 異常検出
クラスタリングの一例を次に示します。
- ハーツシュプルング ラッセル図は、明るさと温度でプロットされた星のクラスタを示します。
- 種間のこれまで知られていなかった遺伝的類似性と相違性を示す遺伝子配列により、これまで外観に基づいていた分類が改訂されました。
- 性格特性の Big 5 モデルは、性格を記述する単語を 5 つのグループにクラスタリングすることで開発されました。HEXACO モデルでは、5 つではなく 6 つのクラスタが使用されます。
補完
クラスタ内の一部のサンプルに特徴データが欠落している場合は、クラスタ内の他のサンプルから欠落データを推測できます。これは「推定」と呼ばれます。たとえば、人気度の低い動画を人気の高い動画とクラスタ化して、動画のおすすめを改善できます。
データ圧縮
前述のように、関連するクラスタ ID は、そのクラスタ内のすべての例の他の特徴量に置き換えることができます。この置換により特徴の数が少なくなるため、そのデータに基づいてモデルを保存、処理、トレーニングするために必要なリソースも削減されます。非常に大規模なデータセットの場合、この節約は大幅になります。
たとえば、1 本の YouTube 動画には次のような特徴データが含まれる場合があります。
- 視聴者の位置情報、時間、ユーザー属性
- コメントのタイムスタンプ、テキスト、ユーザー ID
- 動画タグ
YouTube 動画をクラスタリングすると、この特徴セットが単一のクラスタ ID に置き換えられ、データが圧縮されます。
プライバシーの保護
ユーザーをクラスタ化し、ユーザー ID ではなくクラスタ ID にユーザーデータを関連付けることで、プライバシーをある程度保護できます。たとえば、YouTube ユーザーの視聴履歴に基づいてモデルをトレーニングするとします。ユーザー ID をモデルに渡す代わりに、ユーザーをクラスタ化してクラスタ ID のみを渡すことができます。これにより、個々の視聴履歴が個々のユーザーに関連付けられることがなくなります。プライバシーを保護するには、クラスタに十分な数のユーザーを含める必要があります。