สมมติว่าคุณกําลังทํางานกับชุดข้อมูลที่มีข้อมูลผู้ป่วยจากระบบการดูแลสุขภาพ ชุดข้อมูลมีความซับซ้อนและมีทั้งฟีเจอร์เชิงหมวดหมู่และเชิงตัวเลข คุณต้องการค้นหารูปแบบและความคล้ายคลึงกันในชุดข้อมูล คุณอาจแก้ปัญหานี้อย่างไร
การจัดกลุ่มเป็นเทคนิคแมชชีนเลิร์นนิงที่ไม่มีการควบคุมดูแลซึ่งออกแบบมาเพื่อจัดกลุ่มตัวอย่างที่ไม่มีป้ายกำกับโดยอิงตามลักษณะที่คล้ายคลึงกัน (หากมีป้ายกำกับตัวอย่าง การแบ่งกลุ่มประเภทนี้เรียกว่าการจัดประเภท) ลองพิจารณาการศึกษาผู้ป่วยสมมติที่ออกแบบมาเพื่อประเมินโปรโตคอลการรักษาใหม่ ในระหว่างการศึกษา ผู้ป่วยจะรายงานจำนวนครั้งที่มีอาการต่อสัปดาห์และความรุนแรงของอาการ นักวิจัยสามารถใช้การวิเคราะห์การคลัสเตอร์เพื่อจัดกลุ่มผู้ป่วยที่มีการตอบสนองต่อการรักษาคล้ายกันออกเป็นคลัสเตอร์ รูปที่ 1 แสดงการจัดกลุ่มข้อมูลจําลองที่เป็นไปได้กลุ่มหนึ่งออกเป็น 3 กลุ่ม
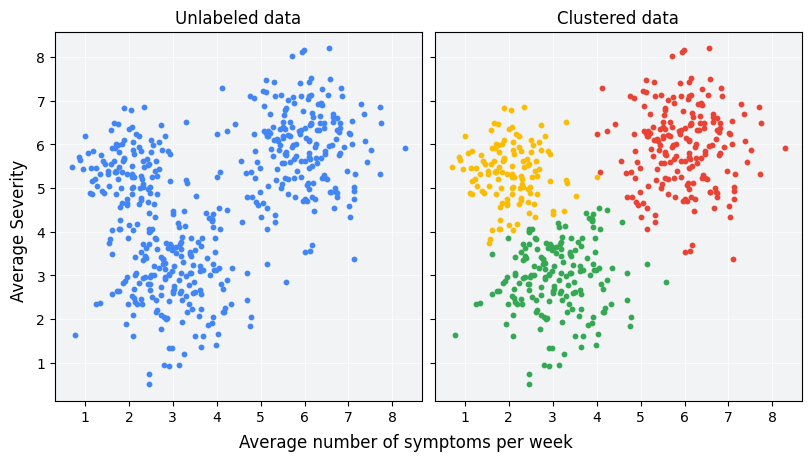
เมื่อดูข้อมูลที่ไม่มีการติดป้ายกำกับทางด้านซ้ายของรูปที่ 1 คุณจะเดาได้ว่าข้อมูลดังกล่าวประกอบด้วยคลัสเตอร์ 3 กลุ่ม แม้ว่าจะไม่มีคำจำกัดความอย่างเป็นทางการเกี่ยวกับความคล้ายคลึงกันระหว่างจุดข้อมูล อย่างไรก็ตาม ในแอปพลิเคชันในชีวิตจริง คุณต้องกําหนดการวัดความคล้ายคลึงหรือเมตริกที่ใช้เปรียบเทียบตัวอย่างอย่างชัดเจนในแง่ของฟีเจอร์ชุดข้อมูล เมื่อตัวอย่างมีเพียง 2-3 ฟีเจอร์ การจําลองและวัดความคล้ายคลึงกันนั้นทําได้ง่ายๆ แต่เมื่อจำนวนฟีเจอร์เพิ่มขึ้น การรวมและเปรียบเทียบฟีเจอร์ต่างๆ จะใช้งานยากขึ้นและซับซ้อนมากขึ้น วิธีการวัดความคล้ายคลึงที่แตกต่างกันอาจเหมาะสมกับสถานการณ์การคลัสเตอร์ที่แตกต่างกันไป และหลักสูตรนี้จะกล่าวถึงการเลือกวิธีการวัดความคล้ายคลึงที่เหมาะสมในส่วนต่อๆ ไป ซึ่งได้แก่ วิธีการวัดความคล้ายคลึงด้วยตนเอง และวิธีการวัดความคล้ายคลึงจากการฝัง
หลังจากจัดกลุ่มแล้ว แต่ละกลุ่มจะได้รับป้ายกำกับที่ไม่ซ้ำกันที่เรียกว่ารหัสคลัสเตอร์ การคลัสเตอร์มีประสิทธิภาพเนื่องจากสามารถลดความซับซ้อนของชุดข้อมูลขนาดใหญ่ที่มีความซับซ้อนซึ่งมีฟีเจอร์หลายรายการให้เป็นรหัสคลัสเตอร์เดียว
กรณีการใช้งานการคลัสเตอร์
การคลัสเตอร์มีประโยชน์ในอุตสาหกรรมต่างๆ แอปพลิเคชันทั่วไปสําหรับการจัดกลุ่มมีดังนี้
- การแบ่งกลุ่มตลาด
- การวิเคราะห์เครือข่ายสังคม
- การจัดกลุ่มผลการค้นหา
- การถ่ายภาพทางการแพทย์
- การแบ่งกลุ่มรูปภาพ
- การตรวจจับความผิดปกติ
ตัวอย่างการคลัสเตอร์ที่เฉพาะเจาะจง
- แผนภูมิ Hertzsprung-Russell แสดงกลุ่มดาวเมื่อพล็อตตามความสว่างและอุณหภูมิ
- การจัดลำดับยีนที่แสดงให้เห็นความคล้ายคลึงและความแตกต่างทางพันธุกรรมที่ไม่รู้จักก่อนหน้านี้ระหว่างสปีชีส์ต่างๆ ทำให้ต้องมีการแก้ไขการจัดหมวดหมู่ซึ่งก่อนหน้านี้อิงตามลักษณะที่ปรากฏ
- รูปแบบลักษณะบุคลิกภาพ Big 5 พัฒนาขึ้นโดยการรวมกลุ่มคำที่อธิบายบุคลิกภาพออกเป็น 5 กลุ่ม รูปแบบ HEXACO ใช้คลัสเตอร์ 6 รายการแทน 5 รายการ
การประมาณ
เมื่อตัวอย่างบางรายการในคลัสเตอร์ไม่มีข้อมูลฟีเจอร์ คุณสามารถอนุมานข้อมูลที่ขาดหายไปจากตัวอย่างอื่นๆ ในคลัสเตอร์ ซึ่งเรียกว่าการประมาณ เช่น วิดีโอที่ได้รับความนิยมน้อยกว่าอาจจัดกลุ่มไว้กับวิดีโอที่ได้รับความนิยมมากกว่าเพื่อปรับปรุงการแนะนำวิดีโอ
การบีบอัดข้อมูล
ดังที่ได้กล่าวไปแล้ว รหัสคลัสเตอร์ที่เกี่ยวข้องสามารถใช้แทนฟีเจอร์อื่นๆ สําหรับตัวอย่างทั้งหมดในคลัสเตอร์นั้น การแทนที่นี้จะช่วยลดจํานวนองค์ประกอบ และด้วยเหตุนี้จึงช่วยลดทรัพยากรที่จําเป็นในการจัดเก็บ ประมวลผล และฝึกโมเดลจากข้อมูลดังกล่าวด้วย สําหรับชุดข้อมูลขนาดใหญ่มาก การประหยัดเหล่านี้จะทวีความสำคัญ
ตัวอย่างเช่น วิดีโอ YouTube รายการเดียวอาจมีข้อมูลฟีเจอร์ต่อไปนี้
- สถานที่ตั้ง เวลา และข้อมูลประชากรของผู้ชม
- การประทับเวลา ข้อความ และรหัสผู้ใช้ของความคิดเห็น
- แท็กวิดีโอ
การจัดกลุ่มวิดีโอ YouTube จะแทนที่ชุดฟีเจอร์นี้ด้วยรหัสคลัสเตอร์เดียว จึงเป็นการบีบอัดข้อมูล
การรักษาความเป็นส่วนตัว
คุณสามารถรักษาความเป็นส่วนตัวได้ในระดับหนึ่งโดยการจัดกลุ่มผู้ใช้และเชื่อมโยงข้อมูลผู้ใช้กับรหัสคลัสเตอร์แทนรหัสผู้ใช้ ตัวอย่างหนึ่งคือ สมมติว่าคุณต้องการฝึกโมเดลเกี่ยวกับประวัติการดูของผู้ใช้ YouTube คุณสามารถจัดกลุ่มผู้ใช้และส่งเฉพาะรหัสคลัสเตอร์แทนการส่งรหัสผู้ใช้ให้กับโมเดล วิธีนี้จะช่วยป้องกันไม่ให้ระบบเชื่อมโยงประวัติการดูแต่ละรายการกับผู้ใช้แต่ละราย โปรดทราบว่าคลัสเตอร์ต้องมีผู้ใช้จํานวนมากพอเพื่อรักษาความเป็นส่วนตัว