Giả sử bạn đang làm việc với một tập dữ liệu chứa thông tin về bệnh nhân từ một hệ thống chăm sóc sức khoẻ. Tập dữ liệu này phức tạp và bao gồm cả các tính năng dạng số và dạng danh mục. Bạn muốn tìm các mẫu và điểm tương đồng trong tập dữ liệu. Bạn có thể giải quyết nhiệm vụ này như thế nào?
Nhóm là một kỹ thuật học máy không giám sát được thiết kế để nhóm các ví dụ chưa được gắn nhãn dựa trên mức độ tương đồng của các ví dụ đó với nhau. (Nếu các ví dụ được gắn nhãn, thì loại nhóm này được gọi là phân loại.) Hãy xem xét một nghiên cứu bệnh nhân giả định được thiết kế để đánh giá một phác đồ điều trị mới. Trong quá trình nghiên cứu, bệnh nhân báo cáo số lần họ gặp phải các triệu chứng mỗi tuần và mức độ nghiêm trọng của các triệu chứng đó. Các nhà nghiên cứu có thể sử dụng phương pháp phân tích cụm để nhóm những bệnh nhân có phản ứng điều trị tương tự nhau thành các cụm. Hình 1 minh hoạ một cách nhóm dữ liệu mô phỏng thành 3 cụm.
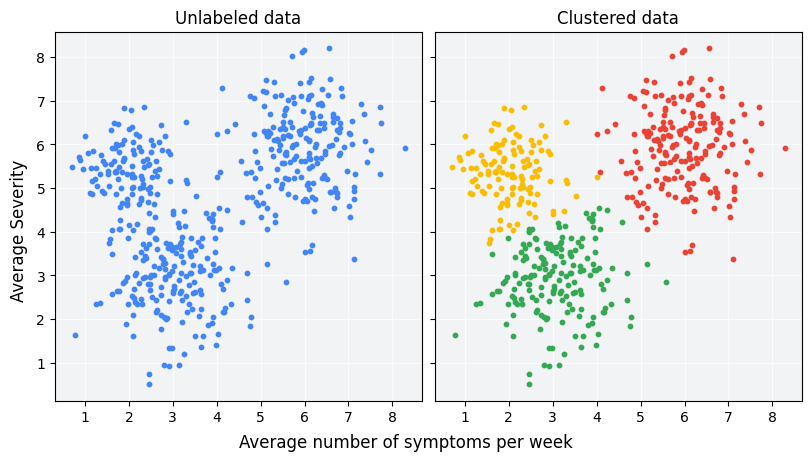
Khi xem dữ liệu chưa được gắn nhãn ở bên trái của Hình 1, bạn có thể đoán rằng dữ liệu này tạo thành 3 cụm, ngay cả khi không có định nghĩa chính thức về mức độ tương đồng giữa các điểm dữ liệu. Tuy nhiên, trong các ứng dụng thực tế, bạn cần xác định rõ ràng chỉ số tương đồng hoặc chỉ số dùng để so sánh các mẫu, xét về các đặc điểm của tập dữ liệu. Khi các ví dụ chỉ có một vài đặc điểm, việc trực quan hoá và đo lường mức độ tương đồng sẽ rất đơn giản. Tuy nhiên, khi số lượng tính năng tăng lên, việc kết hợp và so sánh các tính năng sẽ trở nên kém trực quan và phức tạp hơn. Các phương pháp đo lường mức độ tương đồng có thể phù hợp hơn hoặc kém phù hợp hơn với các tình huống cụm khác nhau. Khóa học này sẽ đề cập đến việc chọn một phương pháp đo lường mức độ tương đồng phù hợp trong các phần sau: Phương pháp đo lường mức độ tương đồng thủ công và Phương pháp đo lường mức độ tương đồng từ các phần nhúng.
Sau khi tạo cụm, mỗi nhóm sẽ được chỉ định một nhãn duy nhất gọi là mã cụm. Tính năng phân cụm rất mạnh mẽ vì có thể đơn giản hoá các tập dữ liệu lớn, phức tạp với nhiều đặc điểm thành một mã nhận dạng cụm duy nhất.
Các trường hợp sử dụng tính năng cụm
Tính năng cụm từ tìm kiếm hữu ích trong nhiều ngành. Một số ứng dụng phổ biến cho việc tạo cụm:
- Phân đoạn thị trường
- Phân tích mạng xã hội
- Nhóm kết quả tìm kiếm
- Hình ảnh y khoa
- Phân đoạn hình ảnh
- Phát hiện hoạt động bất thường
Một số ví dụ cụ thể về việc tạo cụm:
- Biểu đồ Hertzsprung-Russell cho thấy các cụm sao khi được lập biểu đồ theo độ sáng và nhiệt độ.
- Việc giải trình tự gen cho thấy những điểm tương đồng và khác biệt về mặt di truyền chưa từng được biết đến giữa các loài đã dẫn đến việc sửa đổi các hệ thống phân loại trước đây dựa trên hình thức.
- Mô hình Big 5 (5 yếu tố lớn) về các đặc điểm tính cách được phát triển bằng cách nhóm các từ mô tả tính cách thành 5 nhóm. Mô hình HEXACO sử dụng 6 cụm thay vì 5.
Giá trị nội suy
Khi một số ví dụ trong một cụm bị thiếu dữ liệu đặc điểm, bạn có thể suy luận dữ liệu bị thiếu từ các ví dụ khác trong cụm. Quá trình này được gọi là đưa giá trị giả định. Ví dụ: các video ít phổ biến có thể được nhóm với các video phổ biến hơn để cải thiện nội dung đề xuất video.
Nén dữ liệu
Như đã thảo luận, mã nhận dạng cụm liên quan có thể thay thế các đặc điểm khác cho tất cả các ví dụ trong cụm đó. Việc thay thế này làm giảm số lượng tính năng và do đó cũng làm giảm tài nguyên cần thiết để lưu trữ, xử lý và huấn luyện mô hình trên dữ liệu đó. Đối với các tập dữ liệu rất lớn, mức tiết kiệm này trở nên đáng kể.
Ví dụ: một video trên YouTube có thể có dữ liệu về tính năng bao gồm:
- vị trí, thời gian và thông tin nhân khẩu học của người xem
- dấu thời gian, văn bản và mã nhận dạng người dùng của bình luận
- thẻ video
Tính năng nhóm các video trên YouTube sẽ thay thế tập hợp các tính năng này bằng một mã nhận dạng cụm duy nhất, nhờ đó nén dữ liệu.
Bảo vệ quyền riêng tư
Bạn có thể bảo vệ quyền riêng tư ở một mức độ nào đó bằng cách nhóm người dùng và liên kết dữ liệu người dùng với mã nhận dạng cụm thay vì mã nhận dạng người dùng. Ví dụ: giả sử bạn muốn huấn luyện một mô hình dựa trên nhật ký xem của người dùng YouTube. Thay vì truyền mã nhận dạng người dùng vào mô hình, bạn có thể nhóm người dùng và chỉ truyền mã nhận dạng cụm. Điều này giúp ngăn việc liên kết nhật ký xem của từng người dùng với nhau. Xin lưu ý rằng cụm phải chứa đủ số lượng người dùng để bảo vệ quyền riêng tư.