Supongamos que estás trabajando con un conjunto de datos que incluye información de pacientes de un sistema de atención médica. El conjunto de datos es complejo y contiene atributos categóricos y numéricos. Quieres encontrar patrones y similitudes en el conjunto de datos. ¿Cómo abordarías esta tarea?
El agrupamiento en clústeres es una técnica de aprendizaje automático no supervisado diseñada para agrupar ejemplos sin etiquetar en función de su similitud entre sí. (Si los ejemplos están etiquetados, este tipo de agrupación se denomina clasificación). Considera un estudio hipotético de pacientes diseñado para evaluar un nuevo protocolo de tratamiento. Durante el estudio, los pacientes informan cuántas veces a la semana experimentan síntomas y su gravedad. Los investigadores pueden usar el análisis de clústeres para agrupar a los pacientes con respuestas de tratamiento similares en clústeres. En la Figura 1, se muestra una posible agrupación de datos simulados en tres clústeres.
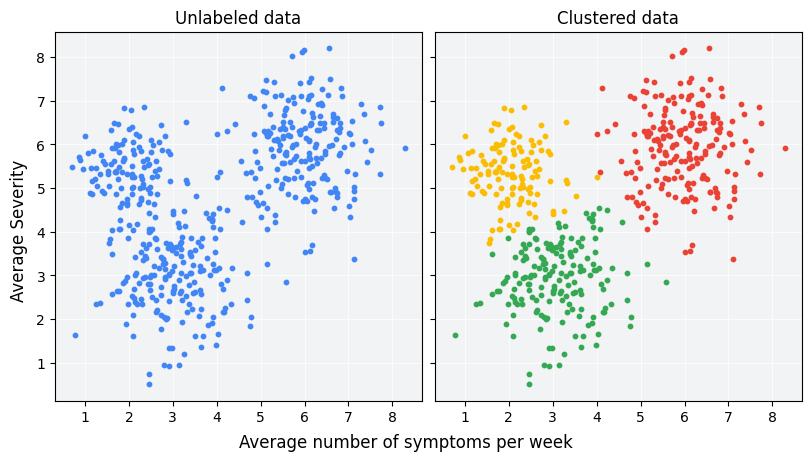
Si observas los datos sin etiquetar a la izquierda de la Figura 1, podrías adivinar que los datos forman tres clústeres, incluso sin una definición formal de similitud entre los datos. Sin embargo, en las aplicaciones del mundo real, debes definir de forma explícita una medida de similitud, o la métrica que se usa para comparar muestras, en términos de las características del conjunto de datos. Cuando los ejemplos tienen solo un par de características, visualizar y medir la similitud es sencillo. Sin embargo, a medida que aumenta la cantidad de atributos, combinar y comparar atributos se vuelve menos intuitivo y más complejo. Las diferentes medidas de similitud pueden ser más o menos apropiadas para diferentes situaciones de agrupamiento, y en este curso se abordará la elección de una medida de similitud adecuada en secciones posteriores: Medidas de similitud manuales y Medida de similitud a partir de incorporaciones.
Después de la agrupación, a cada grupo se le asigna una etiqueta única llamada ID de clúster. El agrupamiento es potente porque puede simplificar conjuntos de datos grandes y complejos con muchos atributos en un solo ID de clúster.
Casos de uso de agrupamiento
El agrupamiento es útil en una variedad de industrias. Estas son algunas aplicaciones comunes para el agrupamiento:
- Segmentación del mercado
- Análisis de redes sociales
- Agrupación de resultados de la búsqueda
- Imágenes médicas
- Segmentación de imágenes
- Detección de anomalías
Estos son algunos ejemplos específicos de agrupamiento:
- El diagrama de Hertzsprung-Russell muestra grupos de estrellas cuando se grafican por luminosidad y temperatura.
- La secuenciación de genes que muestra similitudes y disimilitudes genéticas previamente desconocidas entre las especies llevó a la revisión de las taxonomías que antes se basaban en las apariencias.
- El modelo de rasgos de personalidad de los Big 5 se desarrolló agrupando palabras que describen la personalidad en 5 grupos. El modelo HEXACO usa 6 clústeres en lugar de 5.
Asignación
Cuando faltan datos de atributos en algunos ejemplos de un clúster, puedes inferir los datos faltantes a partir de otros ejemplos del clúster. Esto se denomina imputación. Por ejemplo, los videos menos populares se pueden agrupar con los más populares para mejorar las recomendaciones.
Compresión de datos
Como se mencionó, el ID de clúster relevante puede reemplazar otras funciones para todos los ejemplos de ese clúster. Esta sustitución reduce la cantidad de atributos y, por lo tanto, también reduce los recursos necesarios para almacenar, procesar y entrenar modelos con esos datos. En el caso de los conjuntos de datos muy grandes, estos ahorros se vuelven significativos.
Por ejemplo, un solo video de YouTube puede tener datos de atributos, como los siguientes:
- ubicación, hora y datos demográficos del usuario
- marcas de tiempo, texto y IDs de usuario de los comentarios
- etiquetas de video
El agrupamiento de videos de YouTube reemplaza este conjunto de atributos por un ID de clúster único, lo que comprime los datos.
Preservación de la privacidad
Puedes preservar la privacidad en cierta medida agrupando a los usuarios y asociando sus datos con los IDs de clúster en lugar de los IDs de usuario. A modo de ejemplo, supongamos que quieres entrenar un modelo en el historial de reproducciones de los usuarios de YouTube. En lugar de pasar los IDs de usuario al modelo, puedes agrupar a los usuarios y pasar solo el ID del clúster. De esta manera, se evita que los historiales de reproducción individuales se vinculen a usuarios individuales. Ten en cuenta que el clúster debe contener una cantidad de usuarios lo suficientemente grande para preservar la privacidad.