Supposons que vous travailliez avec un ensemble de données qui inclut des informations sur les patients d'un système de santé. L'ensemble de données est complexe et inclut à la fois des caractéristiques catégorielles et numériques. Vous souhaitez identifier des tendances et des similitudes dans l'ensemble de données. Comment procéder ?
Le clustering est une technique de machine learning non supervisée conçue pour regrouper des exemples non étiquetés en fonction de leur similarité. (Si les exemples sont libellés, ce type de regroupement est appelé classification.) Prenons l'exemple d'une étude sur des patients hypothétiques conçue pour évaluer un nouveau protocole de traitement. Au cours de l'étude, les patients indiquent le nombre de fois par semaine où ils ressentent des symptômes et la gravité de ces symptômes. Les chercheurs peuvent utiliser l'analyse par cluster pour regrouper les patients dont les réponses au traitement sont similaires. La figure 1 illustre un regroupement possible de données simulées en trois clusters.
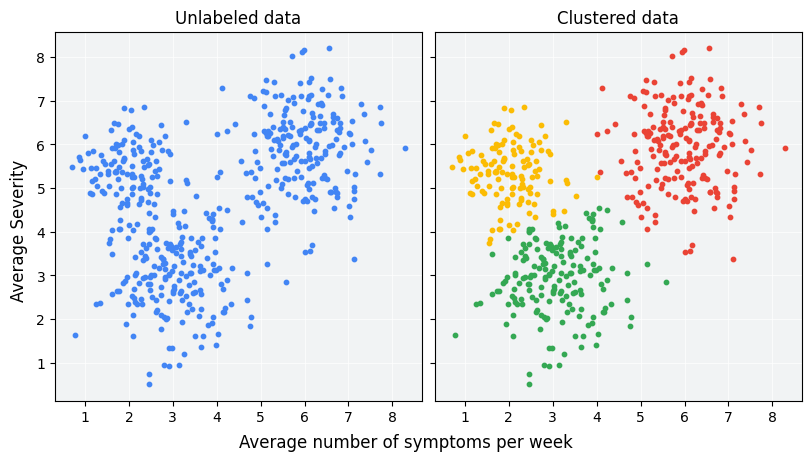
En examinant les données non libellées à gauche de la figure 1, vous pouvez deviner qu'elles forment trois clusters, même sans définition formelle de la similarité entre les points de données. Toutefois, dans les applications réelles, vous devez définir explicitement une mesure de similarité, ou la métrique utilisée pour comparer les échantillons, en termes de caractéristiques de l'ensemble de données. Lorsque les exemples ne comportent que quelques caractéristiques, la visualisation et la mesure de la similarité sont simples. Toutefois, à mesure que le nombre de fonctionnalités augmente, la combinaison et la comparaison des fonctionnalités deviennent moins intuitives et plus complexes. Différentes mesures de similarité peuvent être plus ou moins appropriées pour différents scénarios de clustering. Ce cours aborde le choix d'une mesure de similarité appropriée dans les sections suivantes : Mesures de similarité manuelles et Mesure de similarité à partir d'embeddings.
Après le regroupement, chaque groupe reçoit un libellé unique appelé ID de cluster. Le clustering est puissant, car il peut simplifier les ensembles de données volumineux et complexes comportant de nombreuses caractéristiques en un seul ID de cluster.
Cas d'utilisation du clustering
Le clustering est utile dans divers secteurs. Voici quelques applications courantes du clustering:
- Segmentation du marché
- Analyse des réseaux sociaux
- Regroupement des résultats de recherche
- Imagerie médicale
- Segmentation d'image
- Détection d'anomalies
Voici quelques exemples spécifiques de clustering:
- Le diagramme de Hertzsprung-Russell représente des groupes d'étoiles en fonction de leur luminosité et de leur température.
- Le séquençage des gènes, qui révèle des similitudes et des différences génétiques auparavant inconnues entre les espèces, a conduit à la révision des taxinomies auparavant basées sur l'apparence.
- Le modèle des Big 5 des traits de personnalité a été développé en regroupant les mots qui décrivent la personnalité en cinq groupes. Le modèle HEXACO utilise six clusters au lieu de cinq.
Imputation
Lorsque certaines données de fonctionnalités sont manquantes dans certains exemples d'un cluster, vous pouvez les inférer à partir d'autres exemples du cluster. C'est ce qu'on appelle l'imputation. Par exemple, les vidéos moins populaires peuvent être regroupées avec des vidéos plus populaires pour améliorer les recommandations.
Compression des données
Comme indiqué, l'ID de cluster approprié peut remplacer d'autres fonctionnalités pour tous les exemples de ce cluster. Cette substitution réduit le nombre de fonctionnalités et, par conséquent, les ressources nécessaires pour stocker, traiter et entraîner des modèles sur ces données. Pour les très grands ensembles de données, ces économies deviennent importantes.
Par exemple, une vidéo YouTube peut contenir des données de fonctionnalités, y compris les suivantes:
- l'emplacement, l'heure et les données démographiques du spectateur ;
- codes temporels, texte et ID utilisateur des commentaires
- tags vidéo
Le clustering des vidéos YouTube remplace cet ensemble de fonctionnalités par un seul ID de cluster, ce qui permet de compresser les données.
Protection de la confidentialité
Vous pouvez préserver la confidentialité en regroupant les utilisateurs et en associant les données utilisateur à des ID de cluster plutôt qu'à des ID utilisateur. Imaginons que vous souhaitiez entraîner un modèle sur l'historique des vidéos regardées par les utilisateurs de YouTube. Au lieu de transmettre des ID utilisateur au modèle, vous pouvez regrouper les utilisateurs et ne transmettre que l'ID du cluster. Cela évite que les historiques de visionnage individuels ne soient associés à des utilisateurs individuels. Notez que le cluster doit contenir un nombre suffisamment élevé d'utilisateurs pour préserver la confidentialité.