נניח שאתם עובדים עם מערך נתונים שכולל פרטי מטופלים ממערכת בריאות. מערך הנתונים מורכב וכולל גם מאפיינים קטגוריאליים וגם מאפיינים מספריים. אתם רוצים למצוא דפוסים ודמיון במערך הנתונים. איך אפשר לגשת למשימה הזו?
קיבוץ הוא טכניקה של למידת מכונה לא מבוקרת, שנועדה לקבץ דוגמאות ללא תוויות על סמך הדמיון ביניהן. (אם הדוגמאות מסומנות בתווית, סוג הקיבוץ הזה נקרא סיווג). נניח שאנחנו עורכים מחקר היפותטי על חולים שנועד להעריך פרוטוקול טיפול חדש. במהלך המחקר, החולים מדווחים כמה פעמים בשבוע הם חווים תסמינים ומה חומרת התסמינים. חוקרים יכולים להשתמש בניתוח אשכולות כדי לקבץ מטופלים עם תגובות דומות לטיפול באשכולות. באיור 1 מוצגת אפשרות אחת לקיבוץ של נתונים מדומים לשלושה אשכולות.
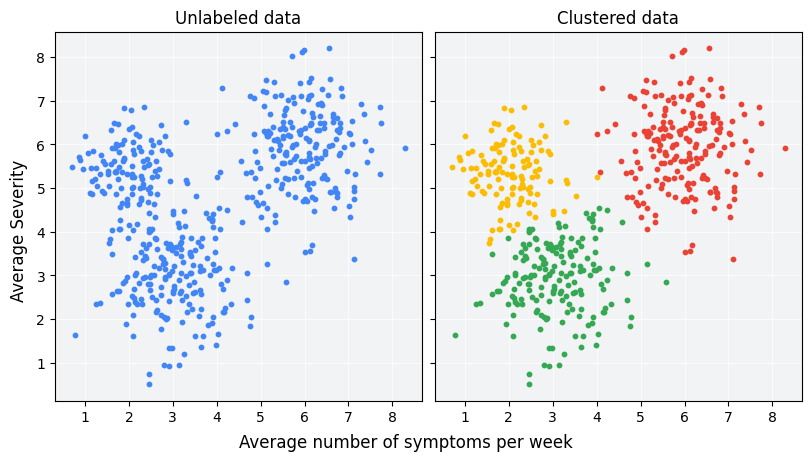
כשבודקים את הנתונים ללא תוויות בצד ימין של איור 1, אפשר לנחש שהנתונים יוצרים שלושה אשכולות, גם בלי הגדרה רשמית של הדמיון בין נקודות הנתונים. עם זאת, באפליקציות בעולם האמיתי צריך להגדיר באופן מפורש מדד דמיון, או את המדד שמשמש להשוואת דגימות, במונחים של מאפייני מערך הנתונים. כשלדוגמאות יש רק כמה תכונות, קל להציג חזותית ולמדוד את הדמיון. עם זאת, ככל שמספר התכונות גדל, השילוב וההשוואה שלהן נעשים מורכבים יותר ולא אינטואיטיביים. מדדי דמיון שונים עשויים להתאים יותר או פחות לתרחישים שונים של קיבוץ. בחלקים הבאים של הקורס נסביר איך לבחור מדד דמיון מתאים: מדדי דמיון ידניים ומדד דמיון מהטמעות (embeddings).
לאחר הקיבוץ, לכל קבוצה מוקצית תווית ייחודית שנקראת מזהה אשכול. קיבוץ הוא כלי יעיל כי הוא מאפשר לפשט מערכי נתונים גדולים ומורכבים עם הרבה מאפיינים למזהה אשכול יחיד.
תרחישים לדוגמה של קיבוץ
אפשר להשתמש בצבירה במגוון תחומים. דוגמאות לאפליקציות נפוצות לצבירה:
- סגמנטציה של שוק
- ניתוח רשתות חברתיות
- קיבוץ של תוצאות חיפוש
- דימות רפואי
- חלוקת תמונות למקטעים
- זיהוי אנומליות
כמה דוגמאות ספציפיות לצבירה:
- בתרשים הרץ-רוסל (Hertzsprung-Russell) מוצגים אשכולות של כוכבים לפי בהירות וטמפרטורה.
- רצפי הגנים, שמראים דמיון וגיוון גנטיים לא ידועים בין מינים, הובילו לשינוי של קטגוריות הטקסונומיה שהתבססו בעבר על המראה.
- מודל Big 5 של מאפייני האישיות פותח על ידי קיבוץ של מילים שמתארות את האישיות ל-5 קבוצות. במודל HEXACO נעשה שימוש ב-6 אשכולות במקום ב-5.
שיוך (imputation)
כשחסרים נתוני תכונות בחלק מהדוגמאות באשכול, אפשר להסיק את הנתונים החסרים מהדוגמאות האחרות באשכול. הפעולה הזו נקראת שיוך. לדוגמה, אפשר לקבץ סרטונים פחות פופולריים עם סרטונים פופולריים יותר כדי לשפר את ההמלצות לסרטונים.
דחיסת נתונים
כפי שצוין, מזהה האשכולות הרלוונטי יכול להחליף מאפיינים אחרים בכל הדוגמאות באשכולות האלה. החלפה כזו מפחיתה את מספר המאפיינים, ולכן גם את המשאבים הנדרשים לאחסון, לעיבוד ולאימון מודלים על הנתונים האלה. בחיסכון הזה יש משמעות רבה במערכי נתונים גדולים מאוד.
לדוגמה, סרטון YouTube אחד יכול לכלול נתוני תכונות, כולל:
- המיקום, הזמן והמידע הדמוגרפי של הצופה
- חותמות זמן, טקסט ומזהי משתמשים של תגובות
- תגי וידאו
כשמקבצים סרטונים ב-YouTube, המערכת מחליפה את קבוצת המאפיינים הזו במזהה אשכול יחיד, וכך דוחסת את הנתונים.
שמירה על הפרטיות
כדי לשמור במידה מסוימת על הפרטיות, אפשר לקבץ משתמשים ולשייך נתוני משתמשים למזהי אשכולות במקום למזהי משתמשים. לדוגמה, נניח שאתם רוצים לאמן מודל על סמך היסטוריית הצפייה של משתמשי YouTube. במקום להעביר מזהי משתמשים למודל, אפשר לקבץ משתמשים ולהעביר רק את מזהה האשכולות. כך מונעים קישור של היסטוריות צפייה ספציפיות למשתמשים ספציפיים. חשוב לזכור שהאשכול צריך להכיל מספר גדול מספיק של משתמשים כדי לשמור על הפרטיות.