मान लें कि आपके पास एक डेटासेट है, जिसमें किसी स्वास्थ्य सेवा सिस्टम से मरीज की जानकारी शामिल है. डेटासेट जटिल है और इसमें कैटगरी और संख्या, दोनों तरह की सुविधाएं शामिल हैं. आपको डेटासेट में पैटर्न और समानताएं ढूंढनी हैं. आपको यह काम किस तरह करना चाहिए?
क्लस्टरिंग, मशीन लर्निंग की एक ऐसी तकनीक है जिसमें मशीन को किसी निगरानी के बिना डेटा का विश्लेषण करने के लिए छोड़ दिया जाता है. इस तकनीक का मकसद, बिना लेबल वाले उदाहरणों को एक-दूसरे से मिलते-जुलते होने के आधार पर ग्रुप में बांटना है. (अगर उदाहरणों को लेबल किया गया है, तो इस तरह के ग्रुप को क्लासिफ़िकेशन कहा जाता है.) इलाज के नए प्रोटोकॉल का आकलन करने के लिए, किसी मरीज की एक काल्पनिक स्टडी पर विचार करें. इस दौरान, मरीज़ बताते हैं कि उन्हें हर हफ़्ते कितनी बार लक्षण महसूस होते हैं और लक्षण कितने गंभीर हैं. क्लस्टर विश्लेषण का इस्तेमाल करके, शोधकर्ता इलाज के दौरान मिलते-जुलते रिस्पॉन्स वाले मरीजों को क्लस्टर में बांट सकते हैं. पहले चित्र में, सिम्युलेट किए गए डेटा को तीन क्लस्टर में बांटने का एक संभावित तरीका दिखाया गया है.
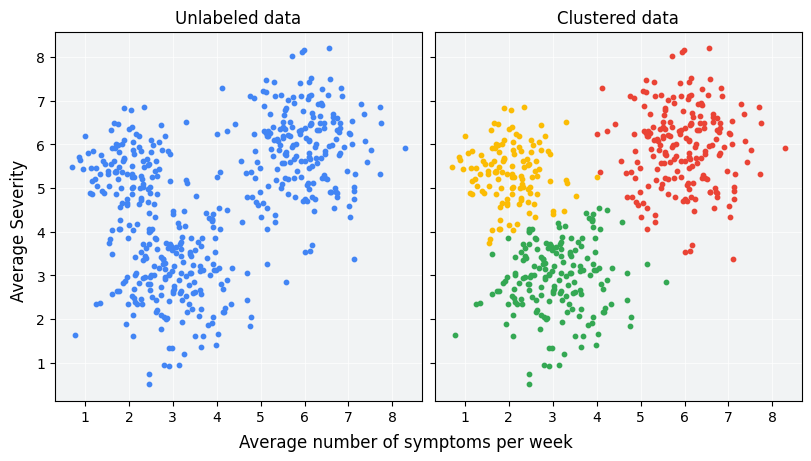
पहली इमेज की बाईं ओर मौजूद, लेबल नहीं किए गए डेटा को देखकर, यह अनुमान लगाया जा सकता है कि डेटा तीन क्लस्टर बनाता है. भले ही, डेटा पॉइंट के बीच समानता की कोई आधिकारिक परिभाषा न हो. हालांकि, असल दुनिया के ऐप्लिकेशन में, आपको डेटासेट की सुविधाओं के हिसाब से, मिलती-जुलती चीज़ों को मेज़र करने का तरीका या सैंपल की तुलना करने के लिए इस्तेमाल की जाने वाली मेट्रिक को साफ़ तौर पर तय करना होगा. जब उदाहरणों में सिर्फ़ कुछ सुविधाएं होती हैं, तो मिलती-जुलती चीज़ों को विज़ुअलाइज़ करना और उनकी तुलना करना आसान होता है. हालांकि, सुविधाओं की संख्या बढ़ने पर, सुविधाओं को जोड़ना और उनकी तुलना करना आसान नहीं होता और यह ज़्यादा मुश्किल हो जाता है. अलग-अलग क्लस्टरिंग स्थितियों के लिए, मिलती-जुलती चीज़ों के अलग-अलग मेज़र ज़्यादा या कम सही हो सकते हैं. इस कोर्स के बाद के सेक्शन में, मिलती-जुलती चीज़ों के सही मेज़र चुनने के बारे में बताया जाएगा: मिलती-जुलती चीज़ों के मैन्युअल मेज़र और एम्बेडिंग से मिलती-जुलती चीज़ों के मेज़र.
क्लस्टर करने के बाद, हर ग्रुप को एक यूनीक लेबल असाइन किया जाता है. इसे क्लस्टर आईडी कहा जाता है. क्लस्टरिंग की सुविधा काफ़ी असरदार है, क्योंकि यह कई सुविधाओं वाले बड़े और जटिल डेटासेट को एक क्लस्टर आईडी में आसानी से बदल सकती है.
क्लस्टर करने के इस्तेमाल के उदाहरण
क्लस्टर करने की सुविधा, कई तरह के इंडस्ट्री में काम की होती है. क्लस्टर करने के लिए कुछ सामान्य ऐप्लिकेशन:
- मार्केट सेगमेंटेशन
- सोशल नेटवर्क ऐनलिसिस
- खोज के नतीजों को ग्रुप करना
- इलाज के लिए तस्वीर
- इमेज का सेगमेंटेशन
- गड़बड़ी की पहचान करना
क्लस्टर करने के कुछ खास उदाहरण:
- हर्ट्ज़स्प्रंग-रसल डायग्राम में, चमक और तापमान के हिसाब से प्लॉट किए गए तारों के क्लस्टर दिखते हैं.
- जीन सीक्वेंसिंग से, प्रजातियों के बीच पहले से अनजान आनुवंशिक समानताएं और अंतर दिखते हैं. इसकी वजह से, पहले दिखने के आधार पर तय की गई टैक्सोनॉमी में बदलाव किया गया है.
- व्यक्तित्व के लक्षणों के Big 5 मॉडल को, व्यक्तित्व के बारे में बताने वाले शब्दों को पांच ग्रुप में बांटकर बनाया गया था. HEXACO मॉडल, पांच के बजाय छह क्लस्टर का इस्तेमाल करता है.
इंपुटेशन
जब किसी क्लस्टर में कुछ उदाहरणों में सुविधा का डेटा मौजूद न हो, तो क्लस्टर के अन्य उदाहरणों से, मौजूद न होने वाले डेटा का अनुमान लगाया जा सकता है. इसे इम्प्यूटेशन कहा जाता है. उदाहरण के लिए, वीडियो के सुझावों को बेहतर बनाने के लिए, कम लोकप्रिय वीडियो को ज़्यादा लोकप्रिय वीडियो के साथ ग्रुप किया जा सकता है.
डेटा कंप्रेस करना
जैसा कि हमने बताया है कि काम का क्लस्टर आईडी, उस क्लस्टर के सभी उदाहरणों के लिए अन्य सुविधाओं की जगह ले सकता है. इस बदलाव से, सुविधाओं की संख्या कम हो जाती है. इसलिए, उस डेटा पर मॉडल को स्टोर करने, प्रोसेस करने, और ट्रेन करने के लिए ज़रूरी संसाधनों की संख्या भी कम हो जाती है. बहुत बड़े डेटासेट के लिए, यह बचत अहम हो जाती है.
उदाहरण के लिए, किसी YouTube वीडियो में सुविधाओं का डेटा शामिल हो सकता है. जैसे:
- दर्शक की जगह, समय, और डेमोग्राफ़िक्स (उम्र, लिंग, रेवेन्यू, शिक्षा वगैरह)
- टिप्पणी के टाइमस्टैंप, टेक्स्ट, और यूज़र आईडी
- वीडियो टैग
YouTube वीडियो को क्लस्टर करने पर, इन सुविधाओं के सेट की जगह एक क्लस्टर आईडी का इस्तेमाल किया जाता है. इससे डेटा कम हो जाता है.
निजता की सुरक्षा
उपयोगकर्ताओं को क्लस्टर में बांटकर और उपयोगकर्ता डेटा को User-ID के बजाय क्लस्टर आईडी से जोड़कर, निजता को कुछ हद तक सुरक्षित रखा जा सकता है. उदाहरण के लिए, मान लें कि आपको YouTube उपयोगकर्ताओं की वॉच हिस्ट्री के आधार पर मॉडल को ट्रेन करना है. मॉडल में यूज़र आईडी पास करने के बजाय, उपयोगकर्ताओं को क्लस्टर में बांटकर सिर्फ़ क्लस्टर आईडी पास किया जा सकता है. इससे, अलग-अलग उपयोगकर्ताओं के वीडियो देखने के इतिहास को एक-दूसरे से अलग रखा जाता है. ध्यान दें कि क्लस्टर में उपयोगकर्ताओं की संख्या ज़रूरत के मुताबिक होनी चाहिए, ताकि निजता को बनाए रखा जा सके.