Supponiamo che tu stia lavorando con un set di dati che include le informazioni dei pazienti di un sistema sanitario. Il set di dati è complesso e include sia caratteristiche categoriche sia numeriche. Vuoi trovare pattern e somiglianze nel set di dati. Come potresti affrontare questa attività?
Il clustering è una tecnica di machine learning non supervisionata progettata per raggruppare esempi non etichettati in base alla loro somiglianza. Se gli esempi sono etichettati, questo tipo di raggruppamento si chiama classificazione. Prendiamo in considerazione un'ipotetica sperimentazione su pazienti progettata per valutare un nuovo protocollo di cura. Durante lo studio, i pazienti segnalano quante volte a settimana manifestano i sintomi e la loro gravità. I ricercatori possono utilizzare l'analisi di clustering per raggruppare i pazienti con risposte simili al trattamento in cluster. La Figura 1 mostra un possibile raggruppamento di dati simulati in tre cluster.
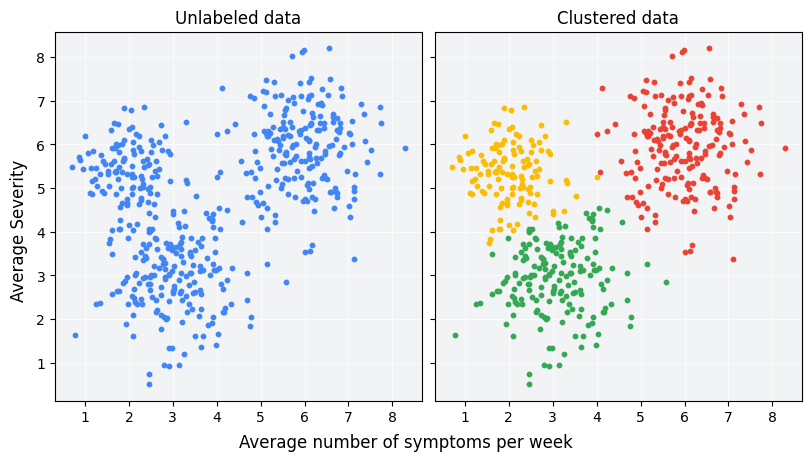
Osservando i dati non etichettati a sinistra della Figura 1, potresti intuire che i dati formano tre cluster, anche senza una definizione formale di somiglianza tra i punti dati. Nelle applicazioni reali, però, devi definire esplicitamente una misura di somiglianza o la metrica utilizzata per confrontare i campioni in termini di caratteristiche del set di dati. Quando gli esempi hanno solo un paio di funzionalità, visualizzare e misurare la somiglianza è semplice. Tuttavia, con l'aumento del numero di funzionalità, la combinazione e il confronto delle funzionalità diventano meno intuitivi e più complessi. Misure di somiglianza diverse possono essere più o meno appropriate per scenari di clustering diversi e questo corso affronterà la scelta di una misura di somiglianza appropriata nelle sezioni successive: Misure di somiglianza manuali e Misura di somiglianza dagli embedding.
Dopo l'aggregazione, a ogni gruppo viene assegnata un'etichetta univoca chiamata ID cluster. Il clustering è efficace perché può semplificare set di dati di grandi dimensioni e complessi con molte funzionalità in un unico ID cluster.
Casi d'uso del clustering
Il clustering è utile in diversi settori. Alcune applicazioni comuni per i cluster:
- Segmentazione del mercato
- Analisi dei social network
- Raggruppamento dei risultati di ricerca
- Diagnostica per immagini
- Segmentazione dell'immagine
- Rilevamento di anomalie
Alcuni esempi specifici di raggruppamento:
- Il diagramma di Hertzsprung-Russell mostra ammassi di stelle quando vengono tracciati in base a luminosità e temperatura.
- La sequenziazione dei geni che mostra somiglianze e differenze genetiche tra specie precedentemente sconosciute ha portato alla revisione delle tassonomie precedentemente basate sull'aspetto.
- Il modello Big 5 di tratti della personalità è stato sviluppato raggruppando le parole che descrivono la personalità in 5 gruppi. Il modello HEXACO utilizza 6 cluster anziché 5.
Attribuzione
Quando alcuni esempi in un cluster presentano dati mancanti sulle funzionalità, puoi dedurre i dati mancanti da altri esempi nel cluster. Questo processo si chiama attribuzione. Ad esempio, i video meno popolari possono essere raggruppati con quelli più popolari per migliorare i consigli sui video.
Compressione dei dati
Come discusso, l'ID cluster pertinente può sostituire altre funzionalità per tutti gli esempi del cluster. Questa sostituzione riduce il numero di funzionalità e quindi anche le risorse necessarie per archiviare, elaborare e addestrare i modelli su questi dati. Per set di dati di grandi dimensioni, questi risparmi diventano significativi.
Ad esempio, un singolo video di YouTube può avere dati sulle funzionalità, tra cui:
- posizione, ora e dati demografici degli spettatori
- timestamp, testo e ID utente dei commenti
- tag video
Il clustering dei video di YouTube sostituisce questo insieme di funzionalità con un singolo ID cluster, comprimendo così i dati.
Tutela della privacy
Puoi preservare in parte la privacy raggruppando gli utenti e associando i dati utente con gli ID cluster anziché con gli ID utente. Per fare un esempio, supponiamo che tu voglia addestrare un modello sulla cronologia delle visualizzazioni degli utenti di YouTube. Invece di passare gli ID utente al modello, puoi raggruppare gli utenti e passare solo l'ID cluster. In questo modo, le singole cronologie degli orologi non vengono associate ai singoli utenti. Tieni presente che il cluster deve contenere un numero sufficiente di utenti per difendere la privacy.