Предположим, вы работаете с набором данных, который включает информацию о пациентах из системы здравоохранения. Набор данных сложен и включает в себя как категориальные, так и числовые характеристики. Вы хотите найти закономерности и сходства в наборе данных. Как вы могли бы подойти к этой задаче?
Кластеризация — это метод машинного обучения без учителя, предназначенный для группировки немаркированных примеров на основе их сходства друг с другом. (Если примеры помечены, такая группировка называется классификацией .) Рассмотрим гипотетическое исследование пациентов, предназначенное для оценки нового протокола лечения. В ходе исследования пациенты сообщали, сколько раз в неделю они испытывают симптомы и их тяжесть. Исследователи могут использовать кластерный анализ, чтобы группировать пациентов со схожими ответами на лечение в кластеры. На рисунке 1 показана одна из возможных группировок смоделированных данных в три кластера.
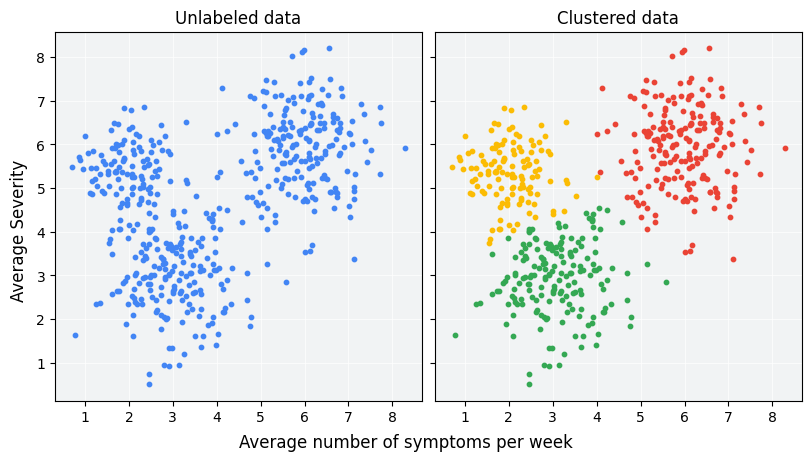
Глядя на немаркированные данные слева на рисунке 1, можно догадаться, что данные образуют три кластера, даже без формального определения сходства между точками данных. Однако в реальных приложениях вам необходимо явно определить меру сходства или метрику, используемую для сравнения выборок, с точки зрения функций набора данных. Когда примеры имеют всего пару функций, визуализировать и измерить сходство несложно. Но по мере увеличения количества функций объединение и сравнение функций становится менее интуитивным и более сложным. Различные меры сходства могут быть более или менее подходящими для разных сценариев кластеризации, и в последующих разделах этого курса будет рассмотрен выбор подходящей меры сходства: Ручные меры сходства и Мера сходства на основе вложений .
После кластеризации каждой группе присваивается уникальная метка, называемая идентификатором кластера . Кластеризация является мощным инструментом, поскольку она позволяет упростить большие и сложные наборы данных с множеством функций до одного идентификатора кластера.
Варианты использования кластеризации
Кластеризация полезна во многих отраслях. Некоторые распространенные приложения для кластеризации:
- Сегментация рынка
- Анализ социальных сетей
- Группировка результатов поиска
- Медицинская визуализация
- Сегментация изображений
- Обнаружение аномалий
Некоторые конкретные примеры кластеризации:
- Диаграмма Герцшпрунга-Рассела показывает скопления звезд, построенные по светимости и температуре.
- Секвенирование генов, которое показывает ранее неизвестные генетические сходства и различия между видами, привело к пересмотру таксономий, ранее основанных на внешнем виде.
- Модель черт личности «Большой пятерки» была разработана путем объединения слов, описывающих личность, в 5 групп. Модель HEXACO использует 6 кластеров вместо 5.
вменение
Если в некоторых примерах в кластере отсутствуют данные об объектах, вы можете вывести недостающие данные из других примеров в кластере. Это называется вменением . Например, менее популярные видео можно объединить с более популярными, чтобы улучшить рекомендации видео.
Сжатие данных
Как уже говорилось, соответствующий идентификатор кластера может заменять другие функции для всех примеров в этом кластере. Эта замена уменьшает количество функций и, следовательно, также уменьшает ресурсы, необходимые для хранения, обработки и обучения моделей на этих данных. Для очень больших наборов данных эта экономия становится значительной.
Например, одно видео YouTube может содержать следующие функциональные данные:
- местоположение, время и демографические данные зрителя
- временные метки комментариев, текст и идентификаторы пользователей
- видеотеги
Кластеризация видео YouTube заменяет этот набор функций единым идентификатором кластера, тем самым сжимая данные.
Сохранение конфиденциальности
Вы можете в некоторой степени сохранить конфиденциальность, кластеризируя пользователей и связывая пользовательские данные с идентификаторами кластера, а не с идентификаторами пользователей. В качестве одного из возможных примеров предположим, что вы хотите обучить модель истории просмотров пользователей YouTube. Вместо передачи идентификаторов пользователей в модель вы можете кластеризовать пользователей и передавать только идентификатор кластера. Благодаря этому история просмотра не привязывается к отдельным пользователям. Обратите внимание, что кластер должен содержать достаточно большое количество пользователей, чтобы сохранить конфиденциальность.