假設您正在使用包含醫療保健系統病人資訊的資料集。資料集複雜,包含類別和數值特徵。您想在資料集中找出模式和相似項目。你會如何處理這項工作?
分群是一種非監督式機器學習技術,旨在根據未標示範例的相似性,將這些範例分組。(如果範例已標示,這種分組稱為分類)。請考慮以下假設的患者研究,該研究旨在評估新的治療方案。研究期間,患者會回報每週出現症狀的次數和症狀嚴重程度。研究人員可以使用集群分析,將治療反應相似的患者歸入同一群組。圖 1 示範將模擬資料分組成三個叢集的一種可能做法。
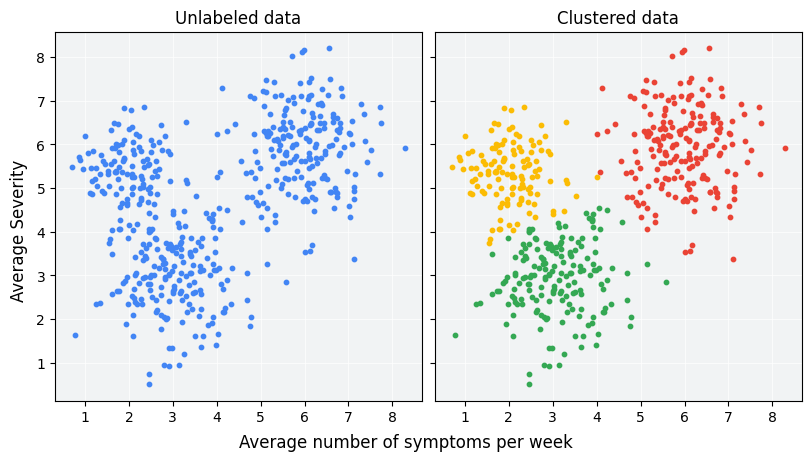
觀察圖 1 左側未標示的資料,您可以推測資料會形成三個叢集,即使沒有正式定義資料點之間的相似性也一樣。不過,在實際應用中,您需要明確定義相似度評估標準,也就是用於比較樣本的評估指標,以便評估資料集的功能。如果範例只有幾個特徵,您就能輕鬆地視覺化及評估相似度。但隨著特徵數量增加,結合和比較特徵的過程就會變得較不直覺且複雜。不同的相似度評估方式可能較適合不同的分群情境,本課程將在後續章節中說明如何選擇適當的相似度評估方式:手動相似度評估方式和從嵌入資料的相似度評估方式。
完成分群後,系統會為每個群組指派一個稱為「群組 ID」的專屬標籤。分群功能相當強大,因為它可以將包含許多特徵的大型複雜資料集簡化為單一叢集 ID。
分群用途
叢集分析在各行各業都很實用。以下是一些常見的叢集應用:
- 市場區隔
- 社群網路分析
- 搜尋結果分組
- 醫學影像
- 圖片區隔
- 異常偵測
以下列舉幾個具體的叢集範例:
- 赫茨普朗-羅素圖會根據亮度和溫度繪製星團。
- 基因定序可顯示物種之間先前未知的基因相似性和差異,進而修正先前以外觀為依據的分類法。
- Big 5 人格特質模型是透過將描述人格特質的字詞分組成 5 組而開發出來的。HEXACO 模型使用 6 個叢集,而非 5 個。
插補法
如果叢集中的部分示例缺少特徵資料,您可以從叢集中的其他示例推斷缺少的資料。這就是所謂的「推論」。舉例來說,系統可以將較不受歡迎的影片與較受歡迎的影片分組,以改善影片推薦功能。
資料壓縮
如前所述,相關叢集 ID 可取代該叢集中所有範例的其他特徵。這種替換方式可減少特徵數量,進而減少儲存、處理及訓練資料模型所需的資源。對於龐大的資料集來說,這些節省的成本就會變得相當可觀。
舉例來說,單一 YouTube 影片可能包含以下特徵資料:
- 觀眾所在位置、時間和客層
- 註解時間戳記、文字和使用者 ID
- 影片代碼
將 YouTube 影片分群後,系統會以單一叢集 ID 取代這組特徵,藉此壓縮資料。
隱私權保護
您可以將使用者分組,並將使用者資料與叢集 ID 建立關聯,而非使用者 ID,以便稍微保護隱私。舉例來說,假設您想根據 YouTube 使用者的觀看記錄訓練模型。您可以將使用者分組,並只傳遞叢集 ID,而非將使用者 ID 傳遞至模型。這樣一來,個別觀看記錄就不會連結至個別使用者。請注意,叢集必須包含足夠大量的使用者,才能確保隱私權。