Angenommen, Sie arbeiten mit einem Datensatz, der Patientendaten aus einem Gesundheitssystem enthält. Der Datensatz ist komplex und enthält sowohl kategorische als auch numerische Features. Sie möchten Muster und Ähnlichkeiten im Datenbestand finden. Wie würden Sie vorgehen?
Clustering ist eine Methode des unüberwachten maschinellen Lernens, mit der Beispiele ohne Labels basierend auf ihrer Ähnlichkeit zueinander gruppiert werden. (Wenn die Beispiele beschriftet sind, wird diese Art der Gruppierung als Klassifizierung bezeichnet.) Angenommen, es wird eine hypothetische Patientenstudie durchgeführt, um ein neues Behandlungsprotokoll zu bewerten. Während des Tests geben die Patienten an, wie oft pro Woche sie Symptome haben und wie schwerwiegend diese sind. Mithilfe der Clusteranalyse können Forscher Patienten mit ähnlichen Behandlungsreaktionen in Clustern gruppieren. Abbildung 1 zeigt eine mögliche Gruppierung simulierter Daten in drei Clustern.
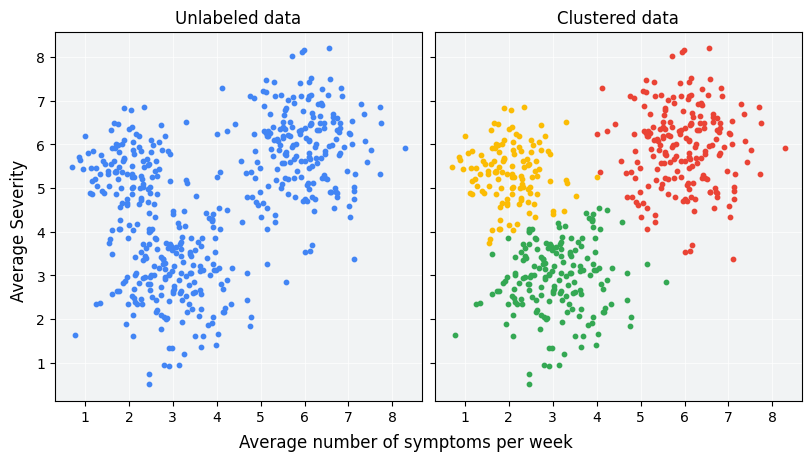
Wenn Sie sich die unbeschrifteten Daten links in Abbildung 1 ansehen, können Sie vermuten, dass die Daten drei Cluster bilden, auch ohne eine formale Definition der Ähnlichkeit zwischen Datenpunkten. In realen Anwendungen müssen Sie jedoch explizit einen Ähnlichkeitsmaßstab oder den Messwert für den Vergleich von Samples in Bezug auf die Features des Datasets definieren. Wenn Beispiele nur wenige Merkmale haben, ist es einfach, Ähnlichkeiten zu visualisieren und zu messen. Mit zunehmender Anzahl von Funktionen wird die Kombination und der Vergleich von Funktionen jedoch weniger intuitiv und komplexer. Für verschiedene Clustering-Szenarien können unterschiedliche Ähnlichkeitsmaße mehr oder weniger geeignet sein. In den folgenden Abschnitten dieses Kurses erfahren Sie, wie Sie ein geeignetes Ähnlichkeitsmaß auswählen: Manuelle Ähnlichkeitsmaße und Ähnlichkeitsmaße aus Embeddings.
Nach dem Clustern wird jeder Gruppe ein eindeutiges Label zugewiesen, die sogenannte Cluster-ID. Clustering ist leistungsstark, da es große, komplexe Datensätze mit vielen Funktionen auf eine einzige Cluster-ID vereinfachen kann.
Anwendungsfälle für das Clustering
Clustering ist in einer Vielzahl von Branchen nützlich. Einige gängige Anwendungen für das Clustern:
- Marktsegmentierung
- Analyse sozialer Netzwerke
- Gruppierung von Suchergebnissen
- Medizinische Bildgebung
- Bildsegmentierung
- Anomalieerkennung
Beispiele für Cluster:
- Das Hertzsprung-Russell-Diagramm zeigt Sternengruppen, die nach Leuchtkraft und Temperatur aufgetragen sind.
- Die Gensequenzierung, die bisher unbekannte genetische Ähnlichkeiten und Unterschiede zwischen Arten aufzeigt, hat zu einer Überarbeitung der Taxonomien geführt, die zuvor auf dem Erscheinungsbild basierten.
- Das Modell der Big Five für Persönlichkeitsmerkmale wurde entwickelt, indem Wörter, die die Persönlichkeit beschreiben, in 5 Gruppen zusammengefasst wurden. Das HEXACO-Modell verwendet sechs Cluster anstelle von fünf.
Imputation
Wenn für einige Beispiele in einem Cluster keine Feature-Daten vorhanden sind, können Sie die fehlenden Daten aus anderen Beispielen im Cluster ableiten. Dies wird als Imputation bezeichnet. Weniger beliebte Videos können beispielsweise mit beliebteren Videos gruppiert werden, um Videoempfehlungen zu verbessern.
Datenkompression
Wie bereits erwähnt, kann die entsprechende Cluster-ID andere Funktionen für alle Beispiele in diesem Cluster ersetzen. Durch diese Substitution wird die Anzahl der Features reduziert und damit auch die Ressourcen, die zum Speichern, Verarbeiten und Trainieren von Modellen mit diesen Daten erforderlich sind. Bei sehr großen Datensätzen sind diese Einsparungen beträchtlich.
Ein einzelnes YouTube-Video kann beispielsweise folgende Feature-Daten enthalten:
- Standort, Uhrzeit und demografische Merkmale der Zuschauer
- Zeitstempel, Text und Nutzer-IDs von Kommentaren
- Video-Tags
Beim Clustern von YouTube-Videos wird diese Gruppe von Funktionen durch eine einzelne Cluster-ID ersetzt, wodurch die Daten komprimiert werden.
Datenschutz
Sie können den Datenschutz etwas verbessern, indem Sie Nutzer clustern und Nutzerdaten mit Cluster-IDs statt mit Nutzer-IDs verknüpfen. Angenommen, Sie möchten ein Modell mit dem Wiedergabeverlauf von YouTube-Nutzern trainieren. Anstatt Nutzer-IDs an das Modell zu übergeben, können Sie Nutzer clustern und nur die Cluster-ID übergeben. So wird verhindert, dass einzelne Wiedergabeverläufe einzelnen Nutzern zugeordnet werden. Der Cluster muss eine ausreichend große Anzahl von Nutzern enthalten, um die Privatsphäre zu schützen.