Załóżmy, że pracujesz nad zbiorem danych zawierającym informacje o pacjentach z systemu opieki zdrowotnej. Zbiór danych jest złożony i zawiera zarówno cechy kategorialne, jak i liczbowe. Chcesz znaleźć w zbiorze danych wzorce i elementy wspólne. Jak można rozwiązać to zadanie?
Klasterowanie to metoda uczenia maszynowego bez nadzoru, która służy do grupowania nieoznaczonych przykładów na podstawie ich podobieństwa. (Jeśli przykłady są oznaczone, takie zgrupowanie nazywa się klasyfikacją). Rozważ hipotetyczne badanie kliniczne mające na celu ocenę nowego protokołu leczenia. Podczas badania pacjenci zgłaszają, ile razy w tygodniu występują u nich objawy oraz jak są nasilone. Naukowcy mogą używać analizy klastrowania do grupowania pacjentów z podobnymi reakcjami na leczenie. Rysunek 1 przedstawia jedno z możliwych ugrupowań symulowanych danych w 3 klastry.
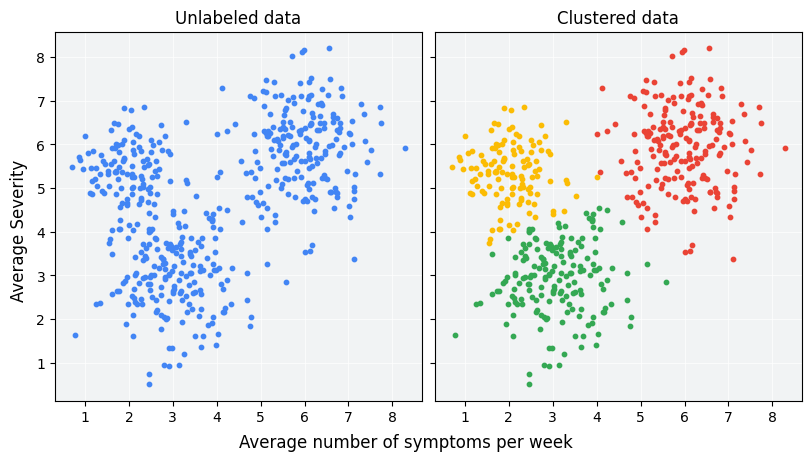
Przyglądając się danym bez etykiet po lewej stronie rysunku 1, można się domyślić, że dane tworzą 3 zbiory, nawet bez formalnej definicji podobieństwa między punktami danych. W przypadku praktycznego zastosowania musisz jednak wyraźnie zdefiniować miarkę podobieństwa lub dane służące do porównywania próbek w ujęciu cech zbioru danych. Gdy przykłady mają tylko kilka cech, wizualizacja i pomiar podobieństwa są proste. Jednak wraz ze wzrostem liczby cech ich porównywanie i łączenie staje się mniej intuicyjne i bardziej skomplikowane. Różne miary podobieństwa mogą być bardziej lub mniej odpowiednie w różnych scenariuszach grupowania. W późniejszych sekcjach tego kursu omówimy wybór odpowiedniej miary podobieństwa: ręczne miary podobieństwa i miara podobieństwa na podstawie wektorów zastępczych.
Po ułożeniu w grupy każdej z nich przypisuje się unikalną etykietę, zwaną identyfikatorem grupy. Utworzenie klastra jest przydatne, ponieważ pozwala uprościć duże, złożone zbiory danych zawierające wiele cech, przypisując im pojedynczy identyfikator klastra.
Przypadki użycia pogrupowania
Utworzenie klastrów przydaje się w różnych branżach. Typowe zastosowania grupowania:
- Segmentacja rynku
- Analiza sieci społecznościowej
- Grupowanie wyników wyszukiwania
- Diagnostyka obrazowa
- Segmentacja obrazu
- Wykrywanie anomalii
Oto kilka konkretnych przykładów grupowania:
- Diagram Hertzsprunga-Russella przedstawia gromady gwiazd na wykresie z luminancją i temperaturą.
- Sekwencjonowanie genów, które ujawnia wcześniej nieznane podobieństwa i różnice genetyczne między gatunkami, doprowadziło do rewizji taksonomii opartej wcześniej na wyglądzie.
- Model Big 5 cech osobowości został opracowany przez pogrupowanie słów opisujących osobowość w 5 grupach. Model HEXACO używa 6 zamiast 5 klastrów.
Imputation
Jeśli w przypadku niektórych przykładów w klastrze brakuje danych cech, możesz je odgadnąć na podstawie innych przykładów w klastrze. Nazywamy to przypisywaniem. Na przykład mniej popularne filmy mogą być grupowane z bardziej popularnymi, aby polecane filmy były lepiej dopasowane.
Kompresja danych
Jak już wspomnieliśmy, odpowiedni identyfikator klastra może zastąpić inne cechy we wszystkich przykładach w tym klastrze. Ta zamiana zmniejsza liczbę cech, a co za tym idzie – także zasoby potrzebne do przechowywania, przetwarzania i trenowania modeli na podstawie tych danych. W przypadku bardzo dużych zbiorów danych oszczędności stają się znaczące.
Na przykład pojedynczy film w YouTube może zawierać dane funkcji, takie jak:
- lokalizacja, czas i dane demograficzne widza;
- sygnatury czasowe komentarzy, tekst i identyfikatory użytkowników.
- tagi wideo,
Utworzenie klastrów filmów w YouTube zastępuje ten zestaw funkcji pojedynczym identyfikatorem klastra, co powoduje skompresowanie danych.
Ochrona prywatności
Możesz zachować prywatność, dzieląc użytkowników na grupy i powiązując dane użytkowników z identyfikatorami grup zamiast z identyfikatorami użytkowników. Weźmy za przykład model, który chcesz wytrenować na podstawie historii oglądania użytkowników YouTube. Zamiast przekazywać identyfikatory użytkowników do modelu, możesz pogrupować użytkowników i przekazać tylko identyfikator klastra. Dzięki temu historia oglądania nie jest przypisywana do poszczególnych użytkowników. Pamiętaj, że klaster musi zawierać wystarczającą liczbę użytkowników, aby można było zachować ich prywatność.