Bir sağlık sisteminden hasta bilgilerini içeren bir veri kümesiyle çalıştığınızı varsayalım. Veri kümesi karmaşıktır ve hem kategorik hem de sayısal özellikler içerir. Veri kümesinde kalıplar ve benzerlikler bulmak istiyorsunuz. Bu göreve nasıl yaklaşabilirsiniz?
Gruplandırma, etiketlenmemiş örnekleri birbirlerine olan benzerliklerine göre gruplandırmak için tasarlanmış, denetimsiz bir makine öğrenimi tekniğidir. (Örnekler etiketlenmişse bu tür gruplamaya sınıflandırma denir.) Yeni bir tedavi protokolünü değerlendirmek için tasarlanmış varsayımsal bir hasta çalışması düşünün. Çalışma sırasında hastalar, belirtileri haftada kaç kez yaşadıklarını ve belirtilerin şiddetini bildirirler. Araştırmacılar, benzer tedavi yanıtlarına sahip hastaları gruplandırmak için gruplandırma analizini kullanabilir. Şekil 1'de, simüle edilmiş verilerin üç kümeye gruplandırılmasının olası bir yolu gösterilmektedir.
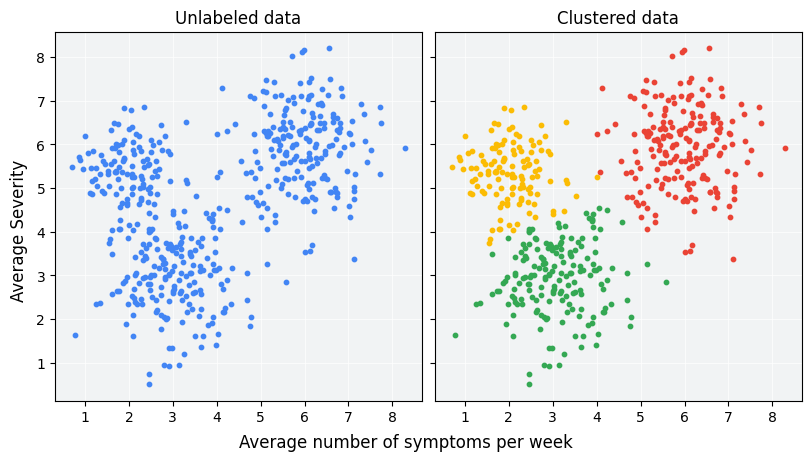
Şekil 1'in solundaki etiketsiz verilere bakarak, veri noktaları arasındaki benzerlik için resmi bir tanım olmadan bile verilerin üç küme oluşturduğunu tahmin edebilirsiniz. Ancak gerçek uygulamalarda, veri kümesinin özellikleri açısından bir benzerlik ölçümü veya örnekleri karşılaştırmak için kullanılan metriği açıkça tanımlamanız gerekir. Örneklerde yalnızca birkaç özellik varsa benzerliği görselleştirmek ve ölçmek kolaydır. Ancak özellik sayısı arttıkça özellikleri bir araya getirmek ve karşılaştırmak daha karmaşık ve sezgisel olmayan bir hal alır. Farklı benzerlik ölçütleri, farklı küme oluşturma senaryoları için daha veya daha az uygun olabilir. Bu kursta, uygun bir benzerlik ölçütü seçme konusu daha sonraki bölümlerde ele alınacaktır: Manuel benzerlik ölçütleri ve Embedding'lerden benzerlik ölçümü.
Küme oluşturma işleminden sonra her gruba küme kimliği adı verilen benzersiz bir etiket atanır. Küme oluşturma, birçok özelliği olan büyük ve karmaşık veri kümelerini tek bir küme kimliğine indirgeyerek basitleştirebildiği için güçlü bir yöntemdir.
Kümeleme kullanım alanları
Küme oluşturma, çeşitli sektörlerde faydalıdır. Küme oluşturmanın bazı yaygın uygulamaları:
- Pazar segmentasyonu
- Sosyal ağ analizi
- Arama sonucu gruplandırması
- Tıbbi görüntüleme
- Görüntü segmentasyonu
- Anormallik algılama
Küme oluşturmaya örnek olarak aşağıdakiler verilebilir:
- Hertzsprung-Russell diyagramı, parlaklığa ve sıcaklığa göre noktayla gösterilen yıldız kümelerini gösterir.
- Türler arasındaki daha önce bilinmeyen genetik benzerlikleri ve farklılıkları gösteren gen dizilemesi, daha önce görünüme dayalı olan sınıflandırmaların gözden geçirilmesine yol açtı.
- Kişilik özelliklerinin Büyük 5 modeli, kişiliği tanımlayan kelimeleri 5 gruba ayırarak geliştirilmiştir. HEXACO modeli 5 yerine 6 küme kullanır.
Tahmine dayalı doldurma
Bir kümedeki bazı örneklerde özellik verileri eksik olduğunda, eksik verileri kümedeki diğer örneklerden tahmin edebilirsiniz. Buna tahmine denir. Örneğin, daha az popüler videolar, video önerilerini iyileştirmek için daha popüler videolarla gruplandırılabilir.
Veri sıkıştırma
Daha önce de belirtildiği gibi, ilgili küme kimliği, ilgili kümedeki tüm örnekler için diğer özellikleri değiştirebilir. Bu değiştirme işlemi, özellik sayısını azaltır ve dolayısıyla bu verilerle modelleri depolamak, işlemek ve eğitmek için gereken kaynakları da azaltır. Çok büyük veri kümelerinde bu tasarruflar önemli hale gelir.
Örneğin, tek bir YouTube videosunda aşağıdakiler gibi özellik verileri bulunabilir:
- izleyicinin konumu, saati ve demografisi
- yorum zaman damgaları, metin ve kullanıcı kimlikleri
- video etiketleri
YouTube videolarını kümelemek, bu özellik grubunu tek bir küme kimliğiyle değiştirerek verileri sıkıştırır.
Gizliliği koruma
Kullanıcıları gruplandırarak ve kullanıcı verilerini kullanıcı kimlikleri yerine küme kimlikleriyle ilişkilendirerek gizliliği bir dereceye kadar koruyabilirsiniz. Bir örnek vermek gerekirse, YouTube kullanıcılarının izleme geçmişiyle ilgili bir model eğitmek istediğinizi varsayalım. Modele kullanıcı kimlikleri yerine kullanıcıları gruplandırabilir ve yalnızca grup kimliğini iletebilirsiniz. Bu sayede, izleme geçmişleri tek tek kullanıcılara eklenmez. Gizliliği korumak için kümenin yeterince fazla sayıda kullanıcı içermesi gerektiğini unutmayın.