假设您正在使用包含医疗系统中患者信息的数据集。该数据集非常复杂,包含分类特征和数值特征。您希望在数据集中查找模式和相似之处。您如何着手完成此任务?
聚类是一种非监督式机器学习技术,旨在根据无标签示例之间的相似性对其进行分组。(如果示例已标记,则这种分组称为分类。)假设有一项旨在评估新治疗方案的患者研究。在研究期间,患者会报告他们每周出现症状的次数以及症状的严重程度。研究人员可以使用聚类分析将具有类似治疗响应的患者划分到不同的群组。图 1 展示了将模拟数据分组为三个集群的一种可能方式。
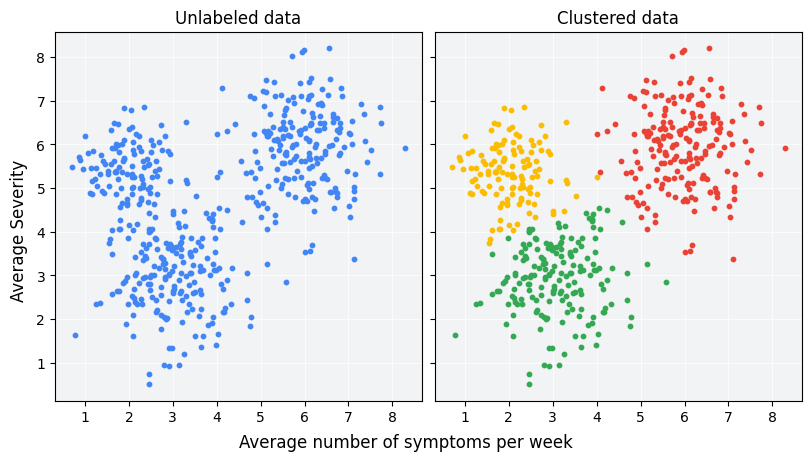
查看图 1 左侧未标记的数据,您可能会猜测这些数据形成了三个集群,即使没有正式定义数据点之间的相似性也是如此。不过,在实际应用中,您需要根据数据集的特征明确定义相似度衡量标准,即用于比较样本的指标。如果示例只有几个特征,则可直观地可视化和衡量相似性。但是,随着特征数量的增加,特征的组合和比较变得越来越不直观、越来越复杂。不同的相似度衡量标准可能更适合不同的聚类场景,本课程将在后面的部分介绍如何选择合适的相似度衡量标准:手动相似度衡量标准和基于嵌入的相似度衡量标准。
完成分组后,系统会为每个组分配一个唯一标签,称为集群 ID。聚类功能非常强大,因为它可以将包含许多特征的大型复杂数据集简化为单个集群 ID。
重合应用场景
聚类在各行各业都很有用。一些常见的集群应用:
- 市场细分
- 社会网络分析
- 搜索结果分组
- 医学影像
- 图片分割
- 异常值检测
一些具体示例如下:
- 赫茨普龙-罗素图会按亮度和温度绘制星团。
- 基因测序揭示了物种之间以前未知的基因相似性和差异性,这促使人们对之前基于外观的分类法进行了修改。
- 个性特征的五因素模型是通过将描述个性的词语分组为 5 组而开发的。HEXACO 模型使用 6 个集群,而不是 5 个。
插补
如果某个集群中的某些示例缺少特征数据,您可以根据集群中的其他示例推断出缺失的数据。这称为推断。例如,我们可以将不太热门的视频与热门视频归为一类,以便改进视频推荐功能。
数据压缩
如前所述,相关的集群 ID 可以替换该集群中所有示例的其他特征。这种替换会减少特征数量,从而减少存储、处理和基于这些数据训练模型所需的资源。对于非常大型的数据集,这些节省会变得非常显著。
举例来说,单个 YouTube 视频可以包含以下特征数据:
- 观看者所在的地理位置、观看时间和受众特征
- 评论时间戳、文本和用户 ID
- 视频广告代码
对 YouTube 视频进行聚类会将这组特征替换为单个集群 ID,从而压缩数据。
隐私保护
您可以通过对用户进行分组,并将用户数据与集群 ID(而非用户 ID)相关联,来一定程度上保护隐私。举个可能的例子,假设您想根据 YouTube 用户的观看记录训练模型。您可以对用户进行分组,然后仅传递集群 ID,而不是将用户 ID 传递给模型。这样可以防止将个人观看记录附加到个人用户。请注意,集群必须包含足够多的用户,才能保护隐私。