Questa sezione esamina i passaggi di preparazione dei dati più pertinenti per il clustering del modulo Lavorazione di dati numerici del corso introduttivo al machine learning.
Nel clustering, la somiglianza tra due esempi viene calcolata combinando tutti i dati delle funzionalità per quegli esempi in un valore numerico. Ciò richiede che le caratteristiche abbiano la stessa scala, il che può essere ottenuto normalizzando, trasformando o creando quantili. Se vuoi trasformare i dati senza ispezionarne la distribuzione, puoi utilizzare per impostazione predefinita i quantili.
Normalizzazione dei dati
Puoi trasformare i dati di più elementi nella stessa scala normalizzandoli.
Punteggi Z
Ogni volta che vedi un set di dati approssimativamente simile a una distribuzione normale, devi calcolare i codici z per i dati. I valori z indicano il numero di deviazioni standard di un valore rispetto alla media. Puoi anche utilizzare i valori z quando il set di dati non è abbastanza grande per i quantili.
Consulta Ridimensionamento del punteggio Z per esaminare i passaggi.
Ecco una visualizzazione di due funzionalità di un set di dati prima e dopo la scalatura dello z-score:
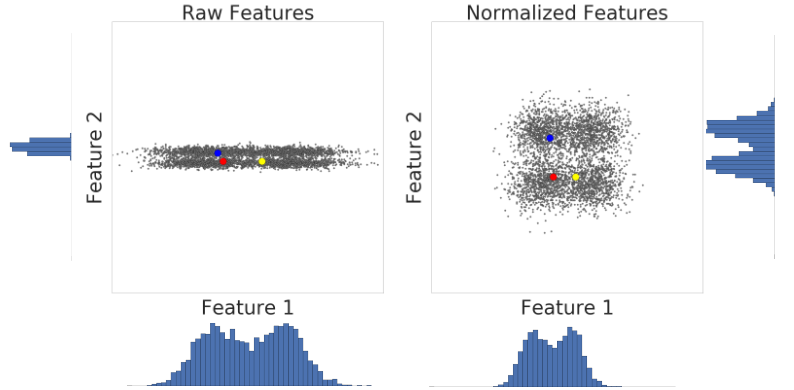
Nel set di dati non normalizzato a sinistra, la caratteristica 1 e la caratteristica 2, rappresentate rispettivamente sugli assi x e y, non hanno la stessa scala. A sinistra, l'esempio rosso sembra più simile al blu che al giallo. A destra, dopo la scalatura del punteggio z, la funzionalità 1 e la funzionalità 2 hanno la stessa scala e l'esempio rosso appare più simile all'esempio giallo. Il set di dati normalizzato fornisce una misura più accurata della somiglianza tra i punti.
Trasformazioni dei log
Quando un set di dati è perfettamente conforme a una distribuzione di legge di potenza , in cui i dati sono fortemente raggruppati nei valori più bassi, utilizza una trasformazione logaritmica. Per esaminare i passaggi, consulta Scalabilità dei log.
Ecco una visualizzazione di un set di dati con distribuzione di potenza prima e dopo una trasformazione logaritmica:
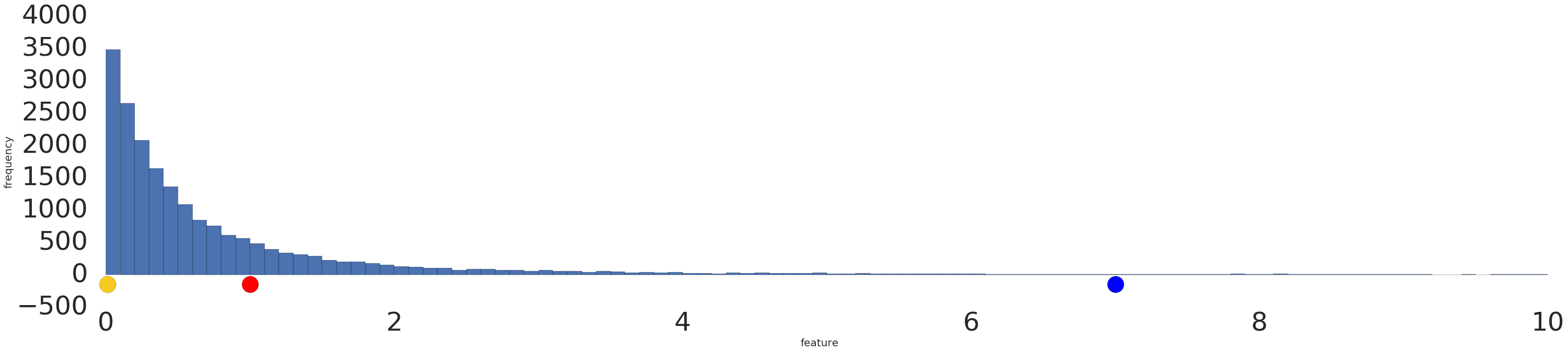
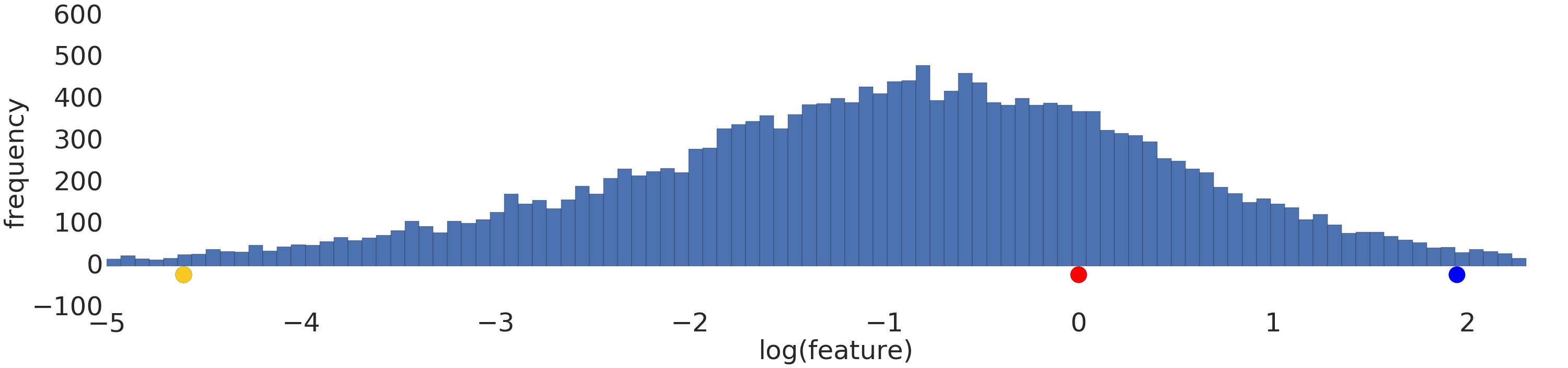
Prima della scalatura logaritmica (Figura 2), l'esempio rosso è più simile al giallo. Dopo la scalatura dei log (Figura 3), il rosso appare più simile al blu.
Quantili
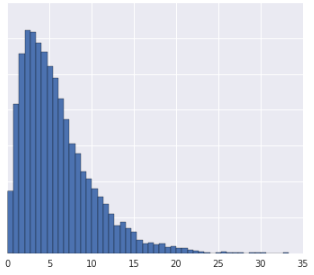
La suddivisione dei dati in quantili funziona bene quando il set di dati non è conforme a una distribuzione nota. Prendi ad esempio questo set di dati:

Intuitivamente, due esempi sono più simili se tra di loro si trovano solo pochi esempi, indipendentemente dai loro valori, e sono più diversi se tra di loro si trovano molti esempi. La visualizzazione sopra riportata rende difficile vedere il numero totale di esempi che rientrano tra il rosso e il giallo o tra il rosso e il blu.
Questa comprensione della somiglianza può essere evidenziata dividendo il set di dati in quantili, ovvero intervalli contenenti ciascuno un numero uguale di esempi, e assegnando l'indice di quantile a ogni esempio. Consulta Bucketing per quantili per esaminare i passaggi.
Ecco la distribuzione precedente divisa in quantili, che mostra che il rosso è distante un quantile dal giallo e tre quantili dal blu:
![Un grafico che mostra i dati dopo la conversione
in quantili. La linea rappresenta 20 intervalli.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=19&hl=it)
Puoi scegliere un numero qualsiasi \(n\) di quantili. Tuttavia, affinché i quantili rappresentino in modo significativo i dati sottostanti, il set di dati deve contenere almeno\(10n\) esempi. Se non hai dati sufficienti, esegui la normalizzazione.
Verificare di aver compreso
Per le seguenti domande, presupponiamo che tu abbia dati sufficienti per creare quantili.
Domanda 1
- La distribuzione dei dati è gaussiana.
- Hai alcune informazioni su cosa rappresentano i dati nella realtà che suggeriscono che i dati non debbano essere trasformati in modo non lineare.
Domanda 2
Dati mancanti
Se il tuo set di dati contiene esempi con valori mancanti per una determinata funzionalità, ma questi esempi si verificano raramente, puoi rimuoverli. Se questi esempi si verificano di frequente, puoi rimuovere del tutto la funzionalità o prevedere i valori mancanti da altri esempi utilizzando un modello di machine learning. Ad esempio, puoi attribuire i dati numerici mancanti utilizzando un modello di regressione addestrato sui dati delle funzionalità esistenti.