이 섹션에서는 머신러닝 단기집중과정에서 숫자 데이터 작업 모듈의 클러스터링과 가장 관련성이 높은 데이터 준비 단계를 검토합니다.
클러스터링에서는 두 예시의 모든 특성 데이터를 수치 값으로 결합하여 두 예시 간의 유사성을 계산합니다. 이를 위해서는 특징의 크기가 동일해야 하며, 이는 정규화, 변환 또는 중앙값을 만들어서 실행할 수 있습니다. 분포를 검사하지 않고 데이터를 변환하려면 기본적으로 중앙값을 사용하면 됩니다.
데이터 정규화
데이터를 정규화하여 여러 지형지물의 데이터를 동일한 크기로 변환할 수 있습니다.
Z 점수
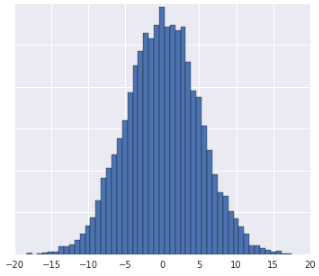
대략 가우스 분포와 같은 모양의 데이터 세트가 표시될 때마다 데이터의 z-점수를 계산해야 합니다. Z 점수는 값이 평균에서 얼마나 차이가 있는지 나타내는 표준 편차 수입니다. 데이터 세트가 중앙값을 구하기에 충분하지 않은 경우에도 z-점수를 사용할 수 있습니다.
단계를 검토하려면 Z-점수 크기 조정을 참고하세요.
다음은 z-점수 크기 조정 전후에 데이터 세트의 두 특성을 시각화한 것입니다.
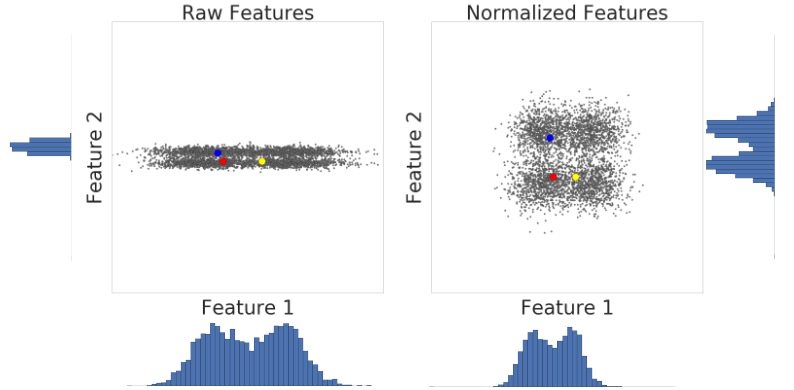
왼쪽의 정규화되지 않은 데이터 세트에서 x축과 y축에 각각 그래프로 표시된 특성 1과 특성 2의 크기가 다릅니다. 왼쪽의 빨간색 예시는 노란색보다 파란색에 더 가깝거나 더 유사해 보입니다. 오른쪽의 z-점수 크기 조정 후에는 특성 1과 특성 2의 크기가 같아지고 빨간색 예시가 노란색 예시와 더 가깝게 표시됩니다. 정규화된 데이터 세트는 포인트 간의 유사성을 더 정확하게 측정합니다.
로그 변환
데이터가 가장 낮은 값에 집중적으로 모여 있는 멱수 법칙 분포를 데이터 세트가 완벽하게 준수하는 경우 로그 변환을 사용하세요. 단계를 검토하려면 로그 확장을 참고하세요.
다음은 로그 변환 전과 후의 지수 분포 데이터 세트의 시각화입니다.
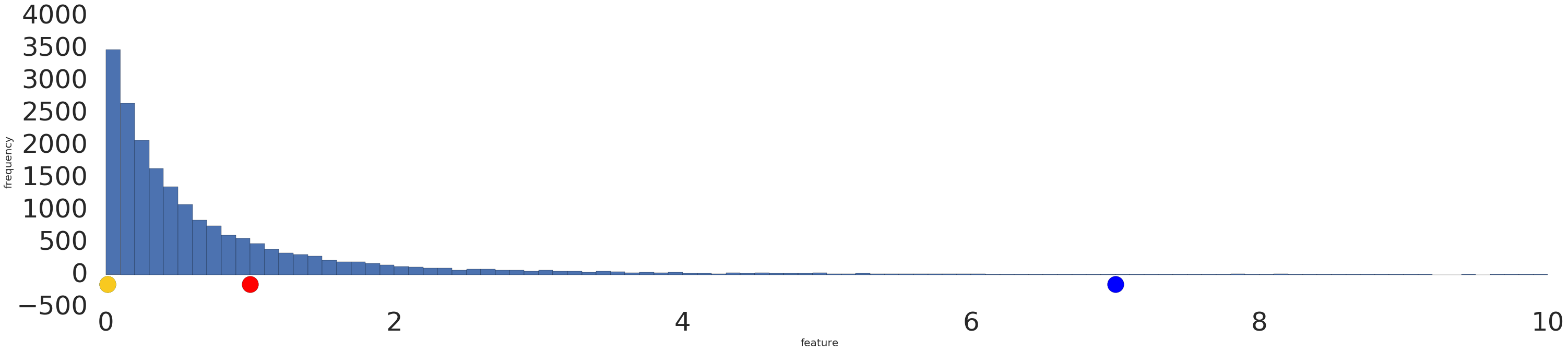
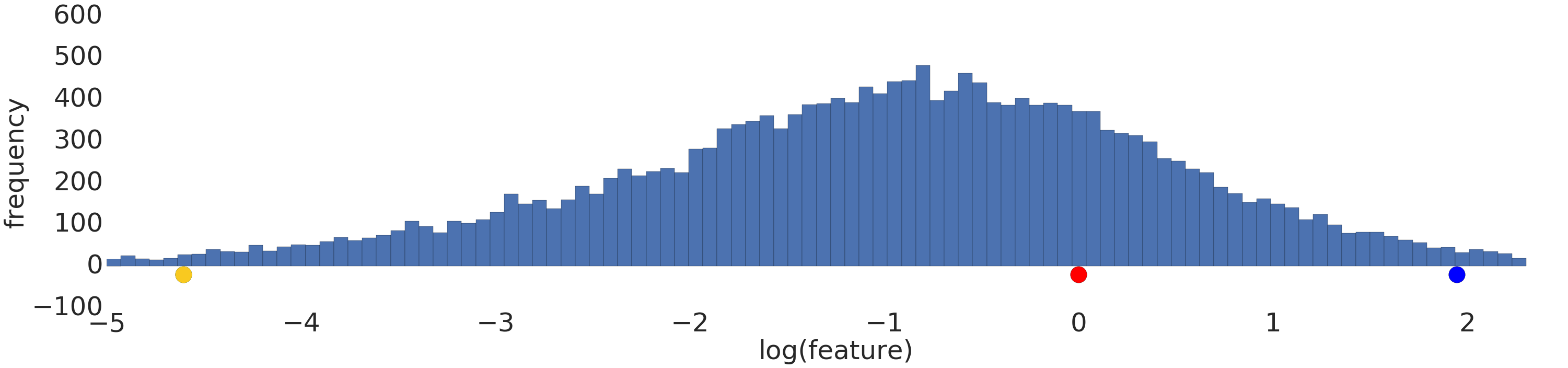
로그 크기 조정 전 (그림 2)에는 빨간색 예시가 노란색에 더 유사하게 보입니다. 로그 크기 조정 (그림 3) 후에는 빨간색이 파란색과 더 비슷하게 보입니다.
분위수
데이터를 빈도수 분포로 분류하는 것은 데이터 세트가 알려진 분포를 따르지 않는 경우에 적합합니다. 다음 데이터 세트를 예로 들 수 있습니다.

직관적으로 두 예시는 값에 관계없이 두 예 사이에 있는 예가 적으면 더 유사하고, 두 예 사이에 있는 예가 많으면 더 유사하지 않습니다. 위의 시각화에서는 빨간색과 노란색 사이 또는 빨간색과 파란색 사이의 총 예시 수를 확인하기 어렵습니다.
이러한 유사성 이해는 데이터 세트를 분위수 또는 각각 동일한 수의 예시를 포함하는 간격으로 나누고 각 예시마다 분위수 색인을 할당하여 얻을 수 있습니다. 단계를 검토하려면 분위 버케팅을 참고하세요.
다음은 이전 분포를 중앙값으로 나눈 것으로, 빨간색이 노란색에서 1개 중앙값 떨어져 있고 파란색에서 3개 중앙값 떨어져 있음을 보여줍니다.
![분위수로 변환한 후의 데이터를 보여주는 그래프 선은 20개 간격을 나타냅니다.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=2&hl=ko)
원하는 수만큼 분위수를 선택할 수 있습니다. \(n\) 그러나 중앙값이 기본 데이터를 의미 있게 나타내려면 데이터 세트에\(10n\) 개 이상의 예가 있어야 합니다. 데이터가 충분하지 않으면 대신 정규화합니다.
이해도 확인
다음 질문에서는 중앙값을 만들기에 충분한 데이터가 있다고 가정합니다.
질문 1
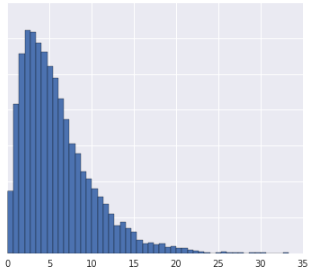
- 데이터 분포는 가우스 분포입니다.
- 데이터가 실제로 무엇을 나타내는지 파악하여 데이터를 비선형으로 변환해서는 안 된다는 것을 알 수 있습니다.
두 번째 질문
데이터 누락
데이터 세트에 특정 특성의 값이 누락된 예가 있지만 이러한 예가 드물게 발생하는 경우 이러한 예를 삭제할 수 있습니다. 이러한 예가 자주 발생하는 경우 해당 특성을 완전히 삭제하거나 머신러닝 모델을 사용하여 다른 예에서 누락된 값을 예측할 수 있습니다. 예를 들어 기존 지형지물 데이터에 대해 학습된 회귀 모델을 사용하여 누락된 숫자 데이터를 보간할 수 있습니다.