این بخش مراحل آمادهسازی دادهها را بررسی میکند که بیشترین ارتباط را با خوشهبندی از ماژول کار با دادههای عددی در آموزش ماشینی Crash Course دارد.
در خوشه بندی، شباهت بین دو مثال را با ترکیب تمام داده های ویژگی برای آن نمونه ها در یک مقدار عددی محاسبه می کنید. این امر مستلزم آن است که ویژگیها مقیاس یکسانی داشته باشند، که میتواند با عادیسازی، تبدیل یا ایجاد چندک انجام شود. اگر میخواهید دادههای خود را بدون بازرسی توزیع آن تغییر دهید، میتوانید بهطور پیشفرض چندکها را انتخاب کنید.
عادی سازی داده ها
میتوانید دادههای چند ویژگی را با نرمالسازی دادهها به یک مقیاس تبدیل کنید.
نمرات Z
هر زمان که یک مجموعه داده تقریباً شبیه توزیع گاوسی می بینید، باید امتیاز z برای داده ها را محاسبه کنید. نمرات Z تعداد انحرافات استاندارد یک مقدار از میانگین است. هنگامی که مجموعه داده به اندازه کافی برای چندک نیست، می توانید از امتیازهای z استفاده کنید.
برای مرور مراحل به مقیاس Z-score مراجعه کنید.
در اینجا تصویری از دو ویژگی یک مجموعه داده قبل و بعد از مقیاس بندی z-score ارائه شده است:
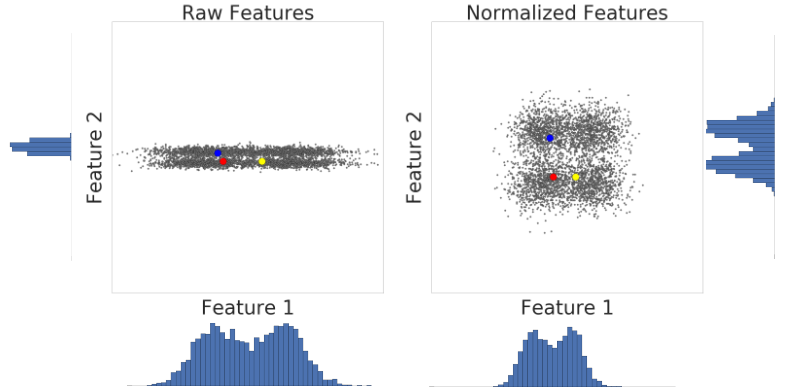
در مجموعه داده غیرعادی سمت چپ، ویژگی 1 و ویژگی 2، به ترتیب نمودار روی محور x و y، مقیاس یکسانی ندارند. در سمت چپ، مثال قرمز به رنگ آبی نزدیکتر یا بیشتر شبیه به زرد ظاهر می شود. در سمت راست، پس از مقیاس بندی z-score، ویژگی 1 و ویژگی 2 دارای مقیاس یکسانی هستند و مثال قرمز نزدیکتر به مثال زرد ظاهر می شود. مجموعه داده نرمال شده اندازه گیری دقیق تری از شباهت بین نقاط را ارائه می دهد.
ثبت تبدیل می شود
هنگامی که یک مجموعه داده کاملاً با توزیع قانون توان مطابقت دارد، جایی که داده ها به شدت در کمترین مقادیر جمع شده اند، از تبدیل log استفاده کنید. برای مرور مراحل، به مقیاس گذاری گزارش مراجعه کنید.
در اینجا یک تجسم از مجموعه داده قدرت-قانون قبل و بعد از تبدیل گزارش است:
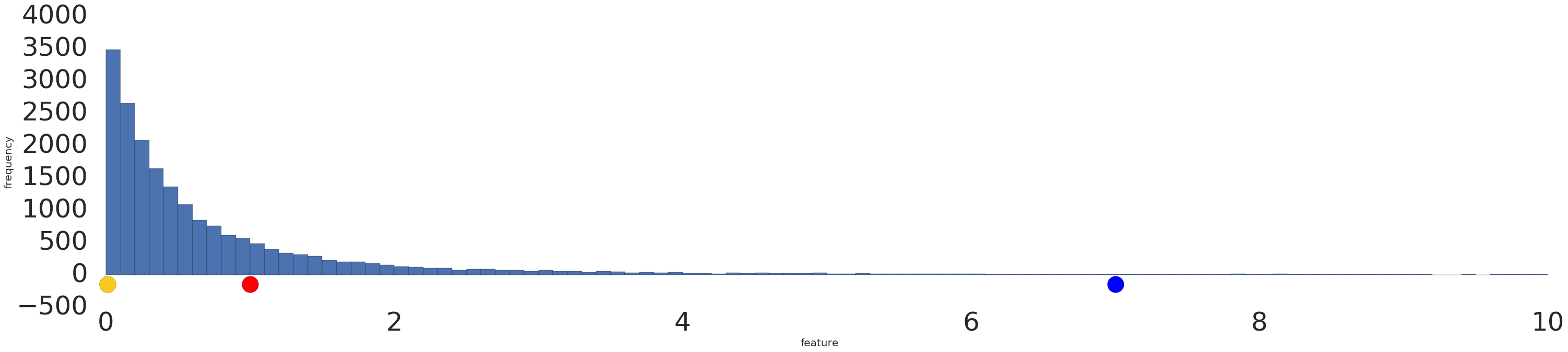
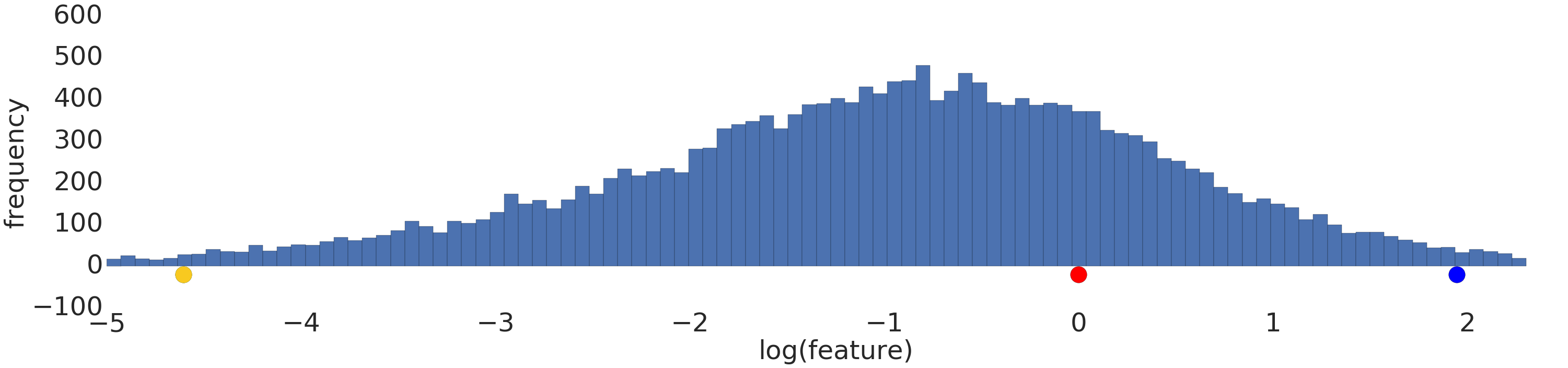
قبل از مقیاس بندی log (شکل 2)، مثال قرمز بیشتر شبیه زرد به نظر می رسد. پس از مقیاس بندی log (شکل 3)، قرمز بیشتر شبیه آبی به نظر می رسد.
کوانتیل ها
زمانی که مجموعه داده با توزیع شناخته شده مطابقت نداشته باشد، پیوند داده ها در چندک به خوبی کار می کند. برای مثال این مجموعه داده را در نظر بگیرید:

به طور شهودی، دو مثال اگر تنها چند مثال بین آنها قرار گیرد، صرف نظر از مقادیرشان، شبیهتر هستند، و اگر مثالهای زیادی بین آنها قرار گیرد، متفاوتتر هستند. تجسم بالا مشاهده تعداد کل نمونه هایی را که بین قرمز و زرد یا بین قرمز و آبی قرار می گیرند دشوار می کند.
این درک از شباهت را می توان با تقسیم مجموعه داده ها به چندک ها ، یا فواصل زمانی که هر کدام شامل تعداد مساوی مثال است، و اختصاص شاخص کمیت به هر مثال نشان داد. برای مرور مراحل به سطل Quantile مراجعه کنید.
در اینجا توزیع قبلی به چندک تقسیم شده است، که نشان میدهد رنگ قرمز یک درصد با زرد و سه چندک با آبی فاصله دارد:
![نموداری که داده ها را پس از تبدیل نشان می دهد به چندک خط نشان دهنده 20 بازه است.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=4&hl=fa)
شما می توانید هر عددی را انتخاب کنید \(n\) از چندک. با این حال، برای اینکه چندک ها به طور معناداری داده های اساسی را نشان دهند، مجموعه داده شما باید حداقل داشته باشد\(10n\) نمونه ها اگر داده کافی ندارید، به جای آن نرمال کنید.
درک خود را بررسی کنید
برای سؤالات زیر، فرض کنید داده های کافی برای ایجاد چندک دارید.
سوال یک
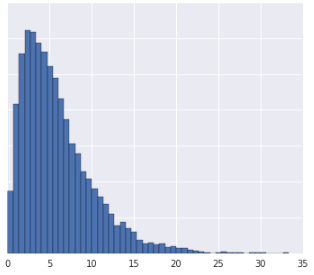
- توزیع داده ها گاوسی است.
- شما بینشی نسبت به آنچه که داده ها به صورت واقعی نشان می دهند دارید که نشان می دهد داده ها نباید به صورت غیرخطی تبدیل شوند.
سوال دو
داده های از دست رفته
اگر مجموعه داده شما دارای نمونه هایی با مقادیر گمشده برای یک ویژگی خاص است، اما این نمونه ها به ندرت رخ می دهند، می توانید این نمونه ها را حذف کنید. اگر این مثالها مکرراً رخ میدهند، میتوانید آن ویژگی را به طور کلی حذف کنید یا میتوانید مقادیر گمشده را از نمونههای دیگر با استفاده از یک مدل یادگیری ماشینی پیشبینی کنید. به عنوان مثال، میتوانید دادههای عددی گمشده را با استفاده از یک مدل رگرسیون آموزشدیده بر روی دادههای ویژگی موجود نسبت دهید .