Esta seção analisa as etapas de preparação de dados mais relevantes para a clusterização do módulo Trabalhar com dados numéricos no Curso intensivo de aprendizado de máquina.
Na formação de clusters, você calcula a semelhança entre dois exemplos combinando todos os dados de recursos desses exemplos em um valor numérico. Isso requer que os atributos tenham a mesma escala, o que pode ser feito normalizando, transformando ou criando quartis. Se você quiser transformar seus dados sem inspecionar a distribuição, use o padrão de percentis.
Como normalizar dados
É possível transformar dados de vários elementos na mesma escala normalizando os dados.
Valores Z
Sempre que você encontrar um conjunto de dados com a forma aproximada de uma distribuição gaussiana, calcule os escores z dos dados. Os escores Z são o número de desvios padrão de um valor em relação à média. Você também pode usar escores z quando o conjunto de dados não for grande o suficiente para quantis.
Consulte Como usar a escala de Z-score para conferir as etapas.
Confira uma visualização de dois recursos de um conjunto de dados antes e depois da escala de z-score:
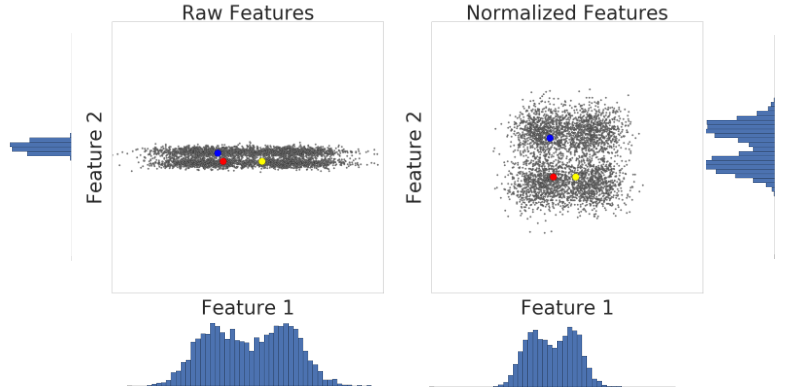
No conjunto de dados não normalizado à esquerda, os recursos 1 e 2, respectivamente representados nos eixos x e y, não têm a mesma escala. À esquerda, o exemplo vermelho parece mais próximo ou mais semelhante ao azul do que ao amarelo. À direita, após a escalação do z-score, o atributo 1 e o atributo 2 têm a mesma escala, e o exemplo vermelho aparece mais próximo do exemplo amarelo. O conjunto de dados normalizado fornece uma medida mais precisa de similaridade entre pontos.
Transformações de registro
Quando um conjunto de dados se conforma perfeitamente a uma distribuição de lei de potência, em que os dados estão agrupados nos valores mais baixos, use uma transformação logarítmica. Consulte Como dimensionar registros para conferir as etapas.
Confira uma visualização de um conjunto de dados de lei de potência antes e depois de uma transformação logarítmica:
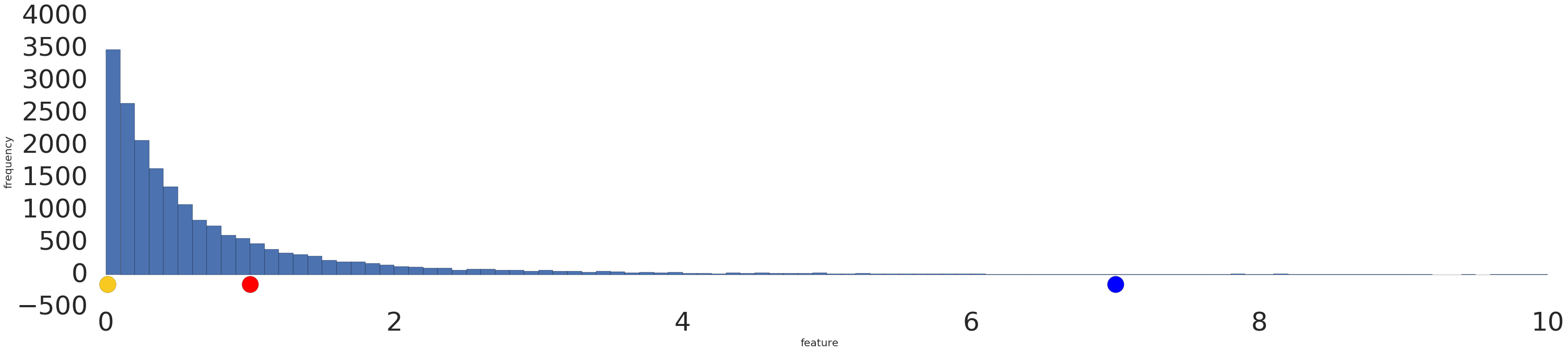
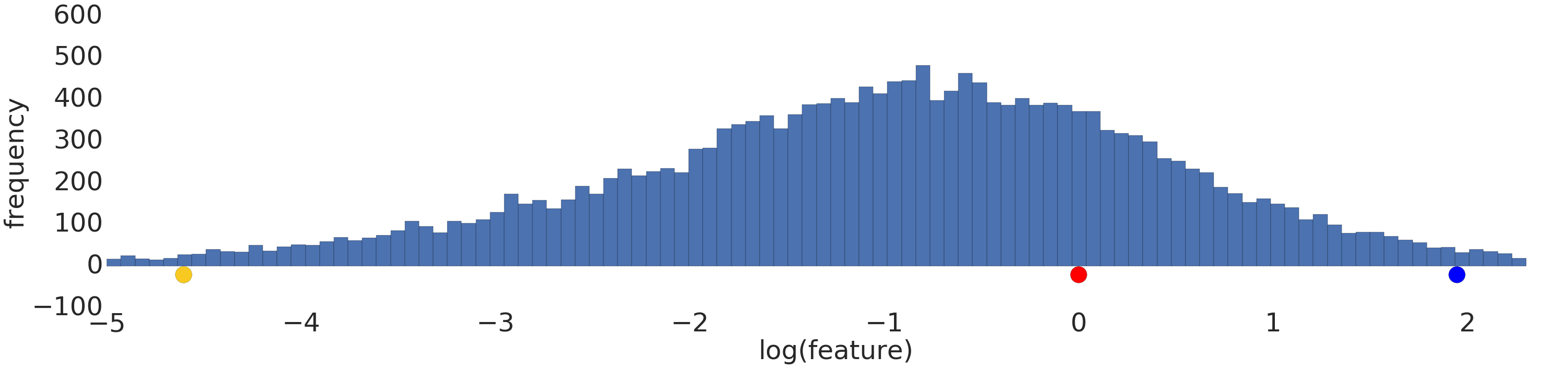
Antes da escalonamento de registro (Figura 2), o exemplo vermelho aparece mais semelhante ao amarelo. Após a escalação de registro (Figura 3), o vermelho aparece mais semelhante ao azul.
Quantis
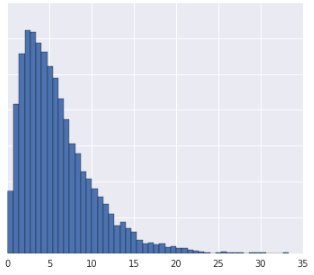
Agrupar os dados em quantis funciona bem quando o conjunto de dados não está em conformidade com uma distribuição conhecida. Considere este conjunto de dados, por exemplo:

Intuitivamente, dois exemplos são mais semelhantes se apenas alguns exemplos estiverem entre eles, independentemente dos valores, e mais diferentes se muitos exemplos estiverem entre eles. A visualização acima dificulta a visualização do número total de exemplos entre vermelho e amarelo ou entre vermelho e azul.
Esse entendimento da semelhança pode ser mostrado dividindo o conjunto de dados em quantis, ou intervalos que contêm números iguais de exemplos, e atribuindo o índice de quantis a cada exemplo. Consulte Bucketing de quartil para revisar as etapas.
Confira a distribuição anterior dividida em quartis, mostrando que o vermelho está a um quartil de distância do amarelo e a três quartis de distância do azul:
![Um gráfico mostrando os dados após a conversão
em quantis. A linha representa 20 intervalos.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=4&hl=pt)
Você pode escolher qualquer número \(n\) de quartis. No entanto, para que os quartis representem os dados subjacentes de maneira significativa, seu conjunto de dados precisa ter pelo menos \(10n\) exemplos. Se você não tiver dados suficientes, normalize.
Teste seu conhecimento
Para as perguntas a seguir, suponha que você tenha dados suficientes para criar quartis.
Primeira pergunta
- A distribuição de dados é gaussiana.
- Você tem algum insight sobre o que os dados representam na realidade, o que sugere que eles não devem ser transformados de forma não linear.
Segunda pergunta
Dados ausentes
Se o conjunto de dados tiver exemplos com valores ausentes para um determinado recurso, mas esses exemplos ocorrerem raramente, você poderá removê-los. Se esses exemplos ocorrerem com frequência, você pode remover esse recurso por completo ou prever os valores ausentes de outros exemplos usando um modelo de aprendizado de máquina. Por exemplo, é possível importar dados numéricos ausentes usando um modelo de regressão treinado com dados de recursos atuais.