Bagian ini meninjau langkah-langkah persiapan data yang paling relevan dengan pengelompokan dari modul Menggunakan data numerik di Kursus Singkat Machine Learning.
Dalam pengelompokan, Anda menghitung kesamaan antara dua contoh dengan menggabungkan semua data fitur untuk contoh tersebut menjadi nilai numerik. Hal ini mengharuskan fitur memiliki skala yang sama, yang dapat dilakukan dengan menormalisasi, mengubah, atau membuat kuantil. Jika ingin mengubah data tanpa memeriksa distribusinya, Anda dapat menetapkannya secara default ke kuartil.
Menormalisasi data
Anda dapat mengubah data untuk beberapa fitur ke skala yang sama dengan menormalisasi data.
Skor Z
Setiap kali Anda melihat set data yang bentuknya kira-kira seperti distribusi Gaussian, Anda harus menghitung skor z untuk data tersebut. Skor Z adalah jumlah simpangan baku nilai dari rata-rata. Anda juga dapat menggunakan skor z jika set data tidak cukup besar untuk kuartil.
Lihat Penskalaan skor z untuk meninjau langkah-langkahnya.
Berikut adalah visualisasi dua fitur set data sebelum dan setelah penskalaan skor z:
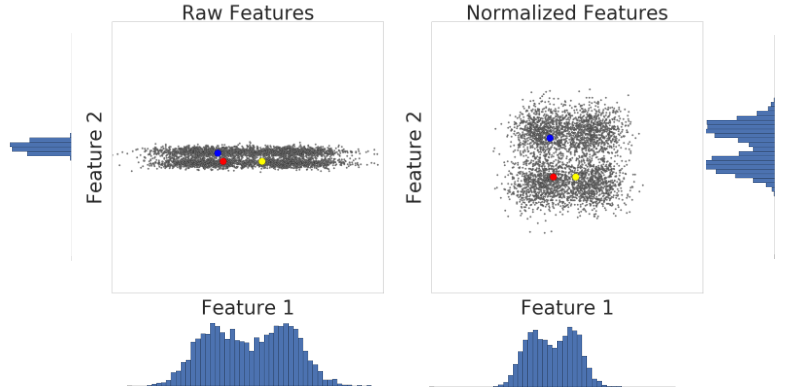
Dalam set data yang tidak dinormalisasi di sebelah kiri, Fitur 1 dan Fitur 2, yang digambarkan masing-masing pada sumbu x dan y, tidak memiliki skala yang sama. Di sebelah kiri, contoh merah tampak lebih dekat, atau lebih mirip, dengan biru daripada kuning. Di sebelah kanan, setelah penskalaan skor z, Fitur 1 dan Fitur 2 memiliki skala yang sama, dan contoh merah tampak lebih dekat dengan contoh kuning. Set data yang dinormalisasi memberikan pengukuran kesamaan yang lebih akurat antara titik.
Transformasi log
Jika set data sepenuhnya sesuai dengan distribusi hukum pangkat, dengan data yang sangat terkumpul pada nilai terendah, gunakan transformasi log. Lihat Penskalaan log untuk meninjau langkah-langkahnya.
Berikut adalah visualisasi set data hukum pangkat sebelum dan sesudah transformasi log:
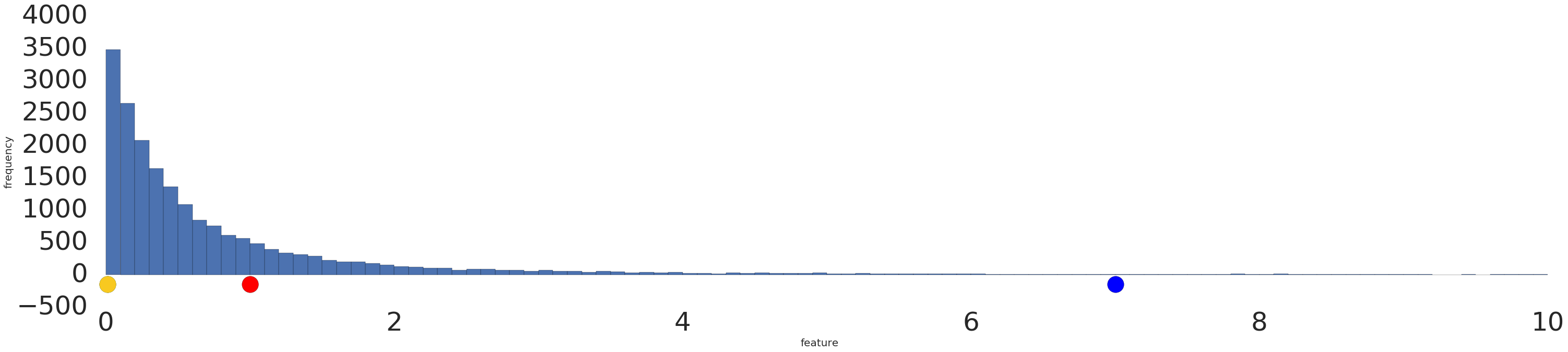
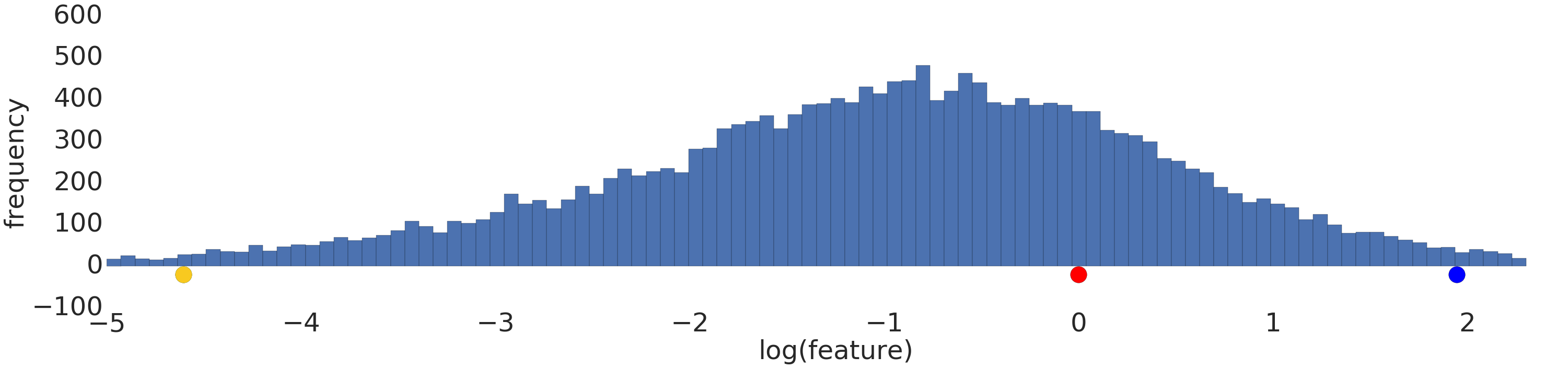
Sebelum penskalaan log (Gambar 2), contoh merah terlihat lebih mirip dengan kuning. Setelah penskalaan log (Gambar 3), warna merah akan terlihat lebih mirip dengan biru.
Kuantil
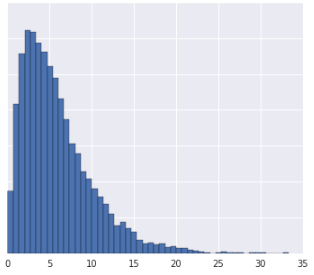
Mengelompokkan data ke dalam kuartil berfungsi dengan baik jika set data tidak sesuai dengan distribusi yang diketahui. Misalnya, ambil set data ini:

Secara intuitif, dua contoh lebih mirip jika hanya ada sedikit contoh yang berada di antara keduanya, terlepas dari nilainya, dan lebih berbeda jika banyak contoh yang berada di antara keduanya. Visualisasi di atas menyulitkan untuk melihat jumlah total contoh yang berada di antara merah dan kuning, atau antara merah dan biru.
Pemahaman tentang kesamaan ini dapat diperoleh dengan membagi set data menjadi kuartil, atau interval yang masing-masing berisi jumlah contoh yang sama, dan menetapkan indeks kuartil ke setiap contoh. Lihat Bucketing kuartil untuk meninjau langkah-langkahnya.
Berikut adalah distribusi sebelumnya yang dibagi menjadi kuartil, yang menunjukkan bahwa merah berjarak satu kuartil dari kuning dan tiga kuartil dari biru:
![Grafik yang menampilkan data setelah dikonversi
menjadi kuartil. Garis ini mewakili 20 interval.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=5&hl=id)
Anda dapat memilih jumlah kuartil \(n\) . Namun, agar kuantil dapat mewakili data pokok secara bermakna, set data Anda harus memiliki minimal\(10n\) contoh. Jika Anda tidak memiliki cukup data, lakukan normalisasi.
Memeriksa pemahaman Anda
Untuk pertanyaan berikut, asumsikan Anda memiliki cukup data untuk membuat kuantil.
Pertanyaan pertama
- Distribusi data bersifat Gaussian.
- Anda memiliki beberapa insight tentang apa yang direpresentasikan data dalam dunia nyata yang menunjukkan bahwa data tidak boleh ditransformasikan secara non-linear.
Pertanyaan kedua
Data tidak ada
Jika set data Anda memiliki contoh dengan nilai yang hilang untuk fitur tertentu, tetapi contoh tersebut jarang terjadi, Anda dapat menghapus contoh ini. Jika contoh tersebut sering terjadi, Anda dapat menghapus fitur tersebut sepenuhnya, atau memprediksi nilai yang hilang dari contoh lain menggunakan model machine learning. Misalnya, Anda dapat mengatribusikan data numerik yang hilang dengan menggunakan model regresi yang dilatih pada data fitur yang ada.