Bu bölümde, Makine Öğrenimi Acele Kursu'ndaki Sayısal verilerle çalışma modülünden küme oluşturmayla en alakalı veri hazırlama adımları incelenmektedir.
Kümelendirmede, iki örnekle ilgili tüm özellik verilerini sayısal bir değerde birleştirerek iki örnek arasındaki benzerliği hesaplarsınız. Bunun için özelliklerin aynı ölçeğe sahip olması gerekir. Bu, normalleştirme, dönüştürme veya yüzdelik dilim oluşturma yoluyla yapılabilir. Verilerinizi dağılımını incelemeden dönüştürmek istiyorsanız varsayılan olarak yüzdelik dilimlere geçebilirsiniz.
Verileri normalleştirme
Verileri normalleştirerek birden fazla özellik için verileri aynı ölçeğe dönüştürebilirsiniz.
Z puanları
Yaklaşık olarak Gauss dağılımı şeklinde bir veri kümesi gördüğünüzde veriler için z puanlarını hesaplamanız gerekir. Z puanları, bir değerin ortalamadan standart sapma sayısıdır. Veri kümesi yüzdelik dilimlere yetecek kadar büyük değilse z puanlarını da kullanabilirsiniz.
Adımları incelemek için Z puanı ölçeklendirme bölümüne bakın.
Aşağıda, bir veri kümesinin iki özelliğinin z-skoru ölçeklendirmesinden önceki ve sonraki durumu görselleştirilmiştir:
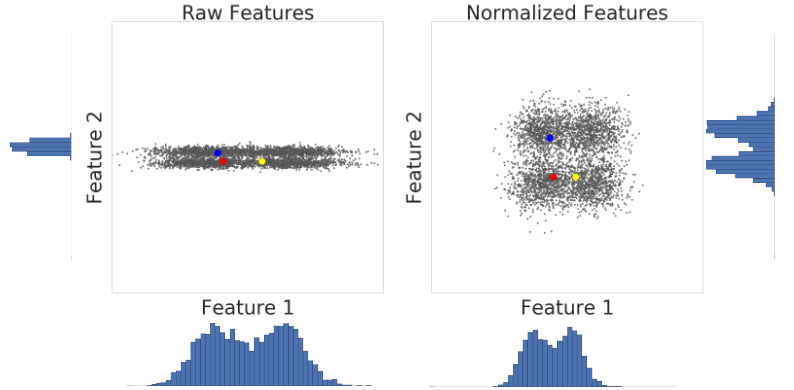
Soldaki normalleştirilmemiş veri kümesinde, x ve y eksenlerinde grafik olarak gösterilen Özellik 1 ve Özellik 2 aynı ölçeğe sahip değildir. Soldaki kırmızı örnek, sarıya kıyasla maviye daha yakın veya daha benzer görünüyor. Sağ tarafta, z-skoru ölçeklendirmesinden sonra Özellik 1 ve Özellik 2 aynı ölçeğe sahiptir ve kırmızı örnek sarı örneğe daha yakın görünür. Normalleştirilmiş veri kümesi, noktalar arasındaki benzerliği daha doğru bir şekilde ölçer.
Günlük dönüştürme işlemleri
Bir veri kümesi, verilerin en düşük değerlerde yoğunlaştığı kuvvet yasası dağılımına mükemmel şekilde uyuyorsa log dönüşümü kullanın. Adımları incelemek için Günlük ölçeklendirme bölümüne bakın.
Bir kuvvet yasası veri kümesinin logaritmik dönüşümden önce ve sonra görselleştirmesi aşağıda verilmiştir:

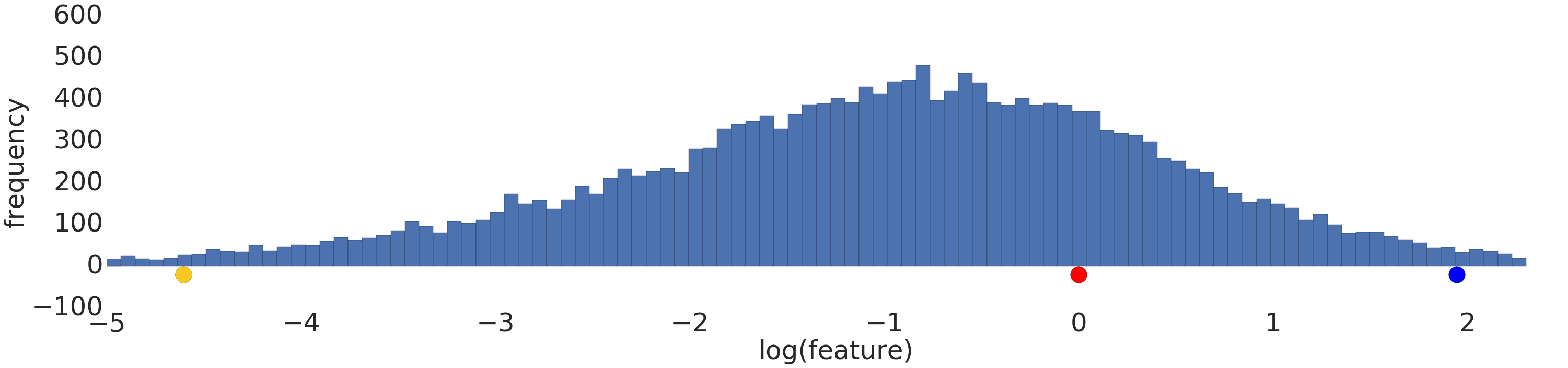
Günlük ölçeklendirmeden önce (Şekil 2), kırmızı örnek sarıya daha benzer görünür. Log ölçeklendirmesinden sonra (Şekil 3), kırmızı mavi renge daha benzer görünür.
Yüzdelik dilimler
Verileri yüzdelik dilimlere ayırma işlemi, veri kümesi bilinen bir dağılıma uymadığında iyi sonuç verir. Örneğin, şu veri kümesini ele alalım:

Sezgisel olarak, iki örnek arasında yalnızca birkaç örnek varsa (değerlerinden bağımsız olarak) daha benzer, aralarında çok sayıda örnek varsa daha farklıdır. Yukarıdaki görselleştirme, kırmızı ile sarı veya kırmızı ile mavi arasında kalan örneklerin toplam sayısını görmeyi zorlaştırır.
Benzerlik anlayışı, veri kümesinin kuantaile veya her biri eşit sayıda örnek içeren aralıklara bölünmesi ve her bir örneğe yüzdelik dilim dizini atanmasıyla ortaya çıkarılabilir. Adımları incelemek için Kuantale gruplandırma bölümüne bakın.
Aşağıda, önceki dağılımın yüzdelik dilimlere ayrılmış hali gösterilmektedir. Bu dağılım, kırmızının sarıdan bir yüzdelik dilim, maviden ise üç yüzdelik dilim uzakta olduğunu gösterir:
![Verileri yüzdelik dilimlere dönüştürüldükten sonra gösteren bir grafik. Çizgi 20 aralığı temsil etmektedir.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=6&hl=tr)
İstediğiniz sayıda kesme noktası seçebilirsiniz. \(n\) Ancak yüzdelik dilimlerin temel verileri anlamlı bir şekilde temsil edebilmesi için veri kümenizde en az\(10n\) örnek olmalıdır. Yeterli veriniz yoksa normalleştirme yapın.
Öğrendiklerinizi test etme
Aşağıdaki sorularda, yüzdelik dilim oluşturmak için yeterli veriniz olduğunu varsayın.
Birinci soru

- Veri dağılımı Gauss dağılımıdır.
- Verilerin gerçekte neyi temsil ettiğine dair bir bilginiz varsa bu, verilerin doğrusal olmayan bir şekilde dönüştürülmemesi gerektiğini gösterir.
İkinci soru
Eksik veriler
Veri kümenizde belirli bir özellik için eksik değerler içeren örnekler varsa ancak bu örnekler nadiren ortaya çıkıyorsa bu örnekleri kaldırabilirsiniz. Bu örnekler sık sık ortaya çıkıyorsa bu özelliği tamamen kaldırabilir veya makine öğrenimi modeli kullanarak diğer örneklerdeki eksik değerleri tahmin edebilirsiniz. Örneğin, mevcut özellik verilerinde eğitilmiş bir regresyon modeli kullanarak eksik sayısal verileri tahmin edebilirsiniz.