এই বিভাগটি মেশিন লার্নিং ক্র্যাশ কোর্সে সংখ্যাসূচক ডেটা মডিউলের সাথে কাজ করা থেকে ক্লাস্টারিংয়ের জন্য সবচেয়ে প্রাসঙ্গিক ডেটা প্রস্তুতির পদক্ষেপগুলি পর্যালোচনা করে।
ক্লাস্টারিং-এ, আপনি একটি সংখ্যাসূচক মানের মধ্যে সেই উদাহরণগুলির জন্য সমস্ত বৈশিষ্ট্য ডেটা একত্রিত করে দুটি উদাহরণের মধ্যে সাদৃশ্য গণনা করেন। এর জন্য বৈশিষ্ট্যগুলির একই স্কেল থাকা প্রয়োজন, যা স্বাভাবিককরণ, রূপান্তর বা কোয়ান্টাইল তৈরি করে সম্পন্ন করা যেতে পারে। আপনি যদি এটির বিতরণ পরিদর্শন না করে আপনার ডেটা রূপান্তর করতে চান তবে আপনি কোয়ান্টাইলে ডিফল্ট করতে পারেন।
ডেটা স্বাভাবিককরণ
আপনি ডেটা স্বাভাবিক করে একই স্কেলে একাধিক বৈশিষ্ট্যের জন্য ডেটা রূপান্তর করতে পারেন।
জেড-স্কোর
যখনই আপনি গাউসিয়ান ডিস্ট্রিবিউশনের মতো মোটামুটি আকারের একটি ডেটাসেট দেখতে পান, তখন আপনার ডেটার জন্য z-স্কোর গণনা করা উচিত। Z-স্কোর হল মান থেকে একটি মান বিচ্যুতির সংখ্যা। ডেটাসেট কোয়ান্টাইলের জন্য যথেষ্ট বড় না হলে আপনি z-স্কোর ব্যবহার করতে পারেন।
ধাপগুলি পর্যালোচনা করতে Z-স্কোর স্কেলিং দেখুন।
এখানে জেড-স্কোর স্কেলিং করার আগে এবং পরে একটি ডেটাসেটের দুটি বৈশিষ্ট্যের একটি ভিজ্যুয়ালাইজেশন রয়েছে:
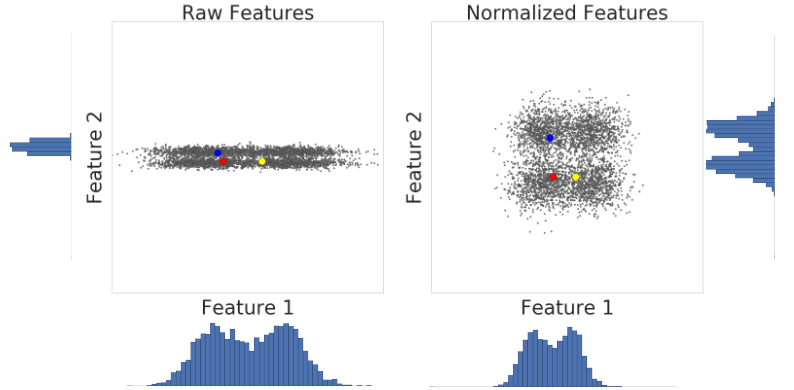
বাম দিকের অস্বাভাবিক ডেটাসেটে, বৈশিষ্ট্য 1 এবং বৈশিষ্ট্য 2, যথাক্রমে x এবং y অক্ষে গ্রাফ করা হয়েছে, একই স্কেল নেই। বাম দিকে, লাল উদাহরণটি হলুদের চেয়ে নীলের কাছাকাছি বা আরও বেশি অনুরূপ দেখা যাচ্ছে। ডানদিকে, z-স্কোর স্কেলিংয়ের পরে, বৈশিষ্ট্য 1 এবং বৈশিষ্ট্য 2-এর একই স্কেল রয়েছে এবং লাল উদাহরণটি হলুদ উদাহরণের কাছাকাছি দেখা যাচ্ছে। স্বাভাবিক করা ডেটাসেট পয়েন্টগুলির মধ্যে মিলের আরও সঠিক পরিমাপ দেয়।
লগ রূপান্তর
যখন একটি ডেটাসেট একটি পাওয়ার আইন বন্টনের সাথে পুরোপুরি সঙ্গতিপূর্ণ হয়, যেখানে ডেটা সর্বনিম্ন মানগুলিতে প্রচুর পরিমাণে জমা হয়, একটি লগ ট্রান্সফর্ম ব্যবহার করুন। ধাপগুলি পর্যালোচনা করতে লগ স্কেলিং দেখুন।
লগ ট্রান্সফর্মের আগে এবং পরে পাওয়ার-ল ডেটাসেটের একটি ভিজ্যুয়ালাইজেশন এখানে রয়েছে:
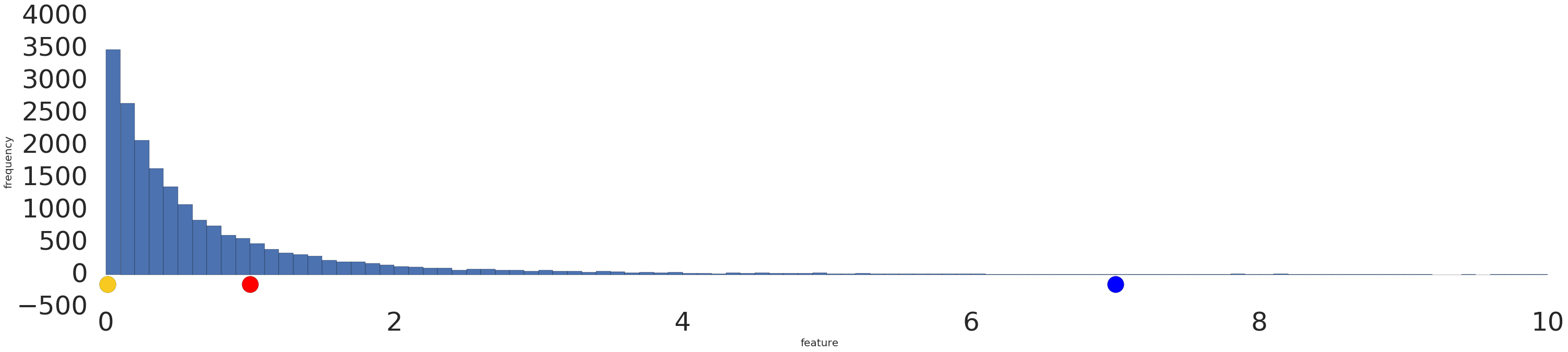
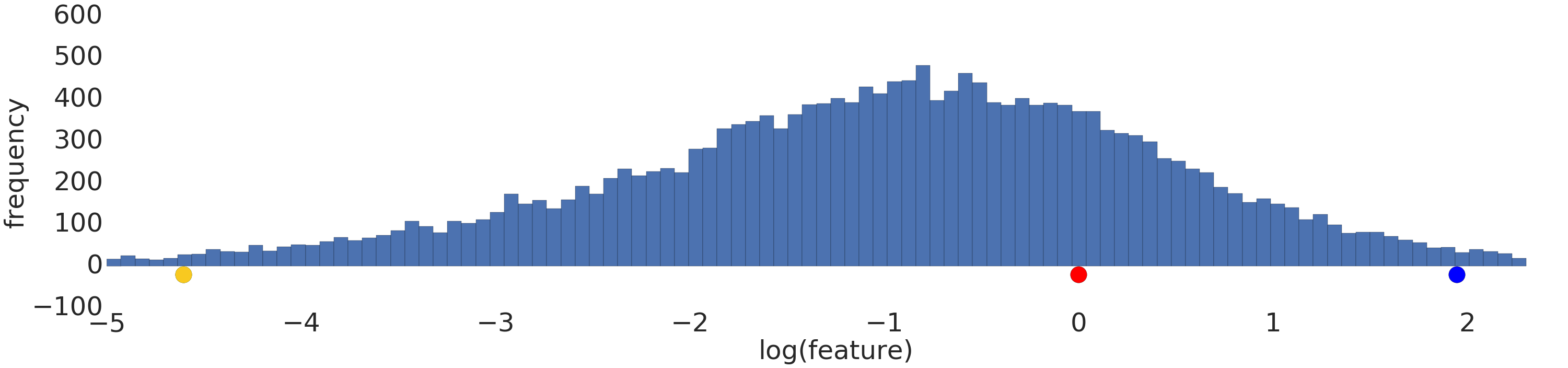
লগ স্কেলিং করার আগে (চিত্র 2), লাল উদাহরণটি হলুদের অনুরূপ দেখায়। লগ স্কেলিং করার পরে (চিত্র 3), লাল নীলের মতো আরও বেশি দেখায়।
কোয়ান্টাইল
ডেটাসেট যখন পরিচিত বন্টনের সাথে সামঞ্জস্যপূর্ণ না হয় তখন কোয়ান্টাইলে ডেটা বাইন করা ভাল কাজ করে। এই ডেটাসেট নিন, উদাহরণস্বরূপ:

স্বজ্ঞাতভাবে, দুটি উদাহরণ আরও বেশি অনুরূপ যদি তাদের মধ্যে শুধুমাত্র কয়েকটি উদাহরণ পড়ে, তাদের মান নির্বিশেষে, এবং যদি অনেক উদাহরণ তাদের মধ্যে পড়ে তবে আরও ভিন্ন। উপরের ভিজ্যুয়ালাইজেশনটি লাল এবং হলুদ বা লাল এবং নীলের মধ্যে পড়ে এমন উদাহরণগুলির মোট সংখ্যা দেখা কঠিন করে তোলে।
সাদৃশ্যের এই বোঝাপড়াটি ডেটাসেটকে কোয়ান্টাইলে বিভক্ত করে, অথবা প্রতিটিতে সমান সংখ্যক উদাহরণ ধারণ করে এবং প্রতিটি উদাহরণে কোয়ান্টাইল সূচক নির্ধারণ করে বের করা যেতে পারে। ধাপগুলি পর্যালোচনা করতে কোয়ান্টাইল বাকেটিং দেখুন।
এখানে পূর্ববর্তী বন্টনটি কোয়ান্টাইলে বিভক্ত, দেখায় যে লাল হলুদ থেকে এক কোয়ান্টাইল দূরে এবং নীল থেকে তিন কোয়ান্টাইল দূরে:
![রূপান্তরের পরে ডেটা দেখানো একটি গ্রাফ কোয়ান্টাইলে লাইনটি 20টি ব্যবধান উপস্থাপন করে।]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=7&hl=bn)
আপনি যে কোন সংখ্যা চয়ন করতে পারেন \(n\) পরিমাণ যাইহোক, কোয়ান্টাইলগুলি অন্তর্নিহিত ডেটাকে অর্থপূর্ণভাবে উপস্থাপন করতে, আপনার ডেটাসেটে অন্তত থাকা উচিত\(10n\) উদাহরণ আপনার কাছে পর্যাপ্ত ডেটা না থাকলে, পরিবর্তে স্বাভাবিক করুন।
আপনার উপলব্ধি পরীক্ষা করুন
নিম্নলিখিত প্রশ্নগুলির জন্য, ধরে নিন আপনার কাছে কোয়ান্টাইল তৈরি করার জন্য যথেষ্ট ডেটা আছে।
প্রশ্ন এক
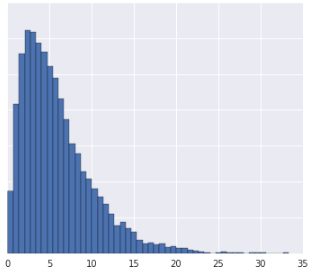
- ডেটা বিতরণ গাউসিয়ান।
- ডেটা বাস্তবে কী প্রতিনিধিত্ব করে সে সম্পর্কে আপনার কিছু অন্তর্দৃষ্টি রয়েছে যা পরামর্শ দেয় যে ডেটা অরৈখিকভাবে রূপান্তরিত করা উচিত নয়।
প্রশ্ন দুই
অনুপস্থিত তথ্য
যদি আপনার ডেটাসেটে একটি নির্দিষ্ট বৈশিষ্ট্যের জন্য অনুপস্থিত মান সহ উদাহরণ থাকে, কিন্তু সেই উদাহরণগুলি খুব কমই ঘটে, আপনি এই উদাহরণগুলি সরাতে পারেন। যদি এই উদাহরণগুলি ঘন ঘন ঘটতে থাকে, আপনি হয় সেই বৈশিষ্ট্যটি সম্পূর্ণভাবে মুছে ফেলতে পারেন, অথবা আপনি একটি মেশিন লার্নিং মডেল ব্যবহার করে অন্যান্য উদাহরণ থেকে অনুপস্থিত মানগুলির পূর্বাভাস দিতে পারেন। উদাহরণস্বরূপ, আপনি বিদ্যমান বৈশিষ্ট্য ডেটাতে প্রশিক্ষিত একটি রিগ্রেশন মডেল ব্যবহার করে অনুপস্থিত সংখ্যাসূচক ডেটা গণনা করতে পারেন।