इस सेक्शन में, मशीन लर्निंग क्रैश कोर्स के न्यूमेरिकल डेटा के साथ काम करना मॉड्यूल से, क्लस्टरिंग के लिए डेटा तैयार करने के सबसे ज़रूरी चरणों की समीक्षा की गई है.
क्लस्टरिंग में, दो उदाहरणों के बीच समानता का हिसाब लगाने के लिए, उन उदाहरणों के सभी सुविधा डेटा को संख्या वाली वैल्यू में जोड़ा जाता है. इसके लिए, ज़रूरी है कि सभी फ़ीचर का स्केल एक जैसा हो. ऐसा करने के लिए, डेटा को सामान्य करना, बदलना या क्वार्टाइल बनाना होगा. अगर आपको डेटा के डिस्ट्रिब्यूशन की जांच किए बिना, डेटा में बदलाव करना है, तो डिफ़ॉल्ट रूप से क्वंटील का इस्तेमाल किया जा सकता है.
डेटा को सामान्य करना
डेटा को सामान्य करके, कई सुविधाओं के डेटा को एक ही स्केल में बदला जा सकता है.
Z-स्कोर
जब भी आपको कोई डेटासेट, गॉसियन डिस्ट्रिब्यूशन के आकार का दिखे, तो आपको डेटा के लिए z-स्कोर का हिसाब लगाना चाहिए. Z-स्कोर, किसी वैल्यू के मीन से होने वाले स्टैंडर्ड डिवीऐशन की संख्या होती है. जब डेटासेट, क्वार्टाइल के लिए ज़रूरत के मुताबिक बड़ा न हो, तो z-स्कोर का इस्तेमाल भी किया जा सकता है.
इस प्रोसेस के बारे में जानने के लिए, Z-स्कोर स्केलिंग देखें.
यहां z-स्कोर स्केलिंग से पहले और बाद में, डेटासेट की दो सुविधाओं का विज़ुअलाइज़ेशन दिया गया है:
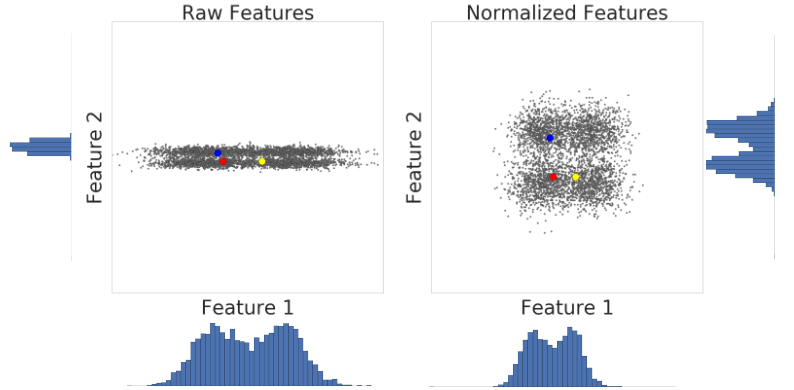
बाईं ओर मौजूद नॉर्मलाइज़ नहीं किए गए डेटासेट में, x और y ऐक्सिस पर ग्राफ़ किए गए फ़ीचर 1 और फ़ीचर 2 का स्केल एक जैसा नहीं है. बाईं ओर, लाल रंग का उदाहरण, पीले रंग के मुकाबले नीले रंग से ज़्यादा मिलता-जुलता है. दाईं ओर, z-स्कोर स्केलिंग के बाद, सुविधा 1 और सुविधा 2 का स्केल एक जैसा है. साथ ही, लाल रंग का उदाहरण, पीले रंग के उदाहरण के करीब दिखता है. सामान्य डेटासेट, पॉइंट के बीच समानता का सटीक आकलन करता है.
लॉग ट्रांसफ़ॉर्म
जब कोई डेटासेट पूरी तरह से पावर लॉ डिस्ट्रिब्यूशन के मुताबिक हो, जहां डेटा सबसे कम वैल्यू पर ज़्यादा क्लस्टर हो, तो लॉग ट्रांसफ़ॉर्म का इस्तेमाल करें. लॉग स्केलिंग देखें और इस प्रोसेस के बारे में जानें.
यहां लॉग ट्रांसफ़ॉर्मेशन से पहले और बाद के पावर-लॉ डेटासेट का विज़ुअलाइज़ेशन दिया गया है:
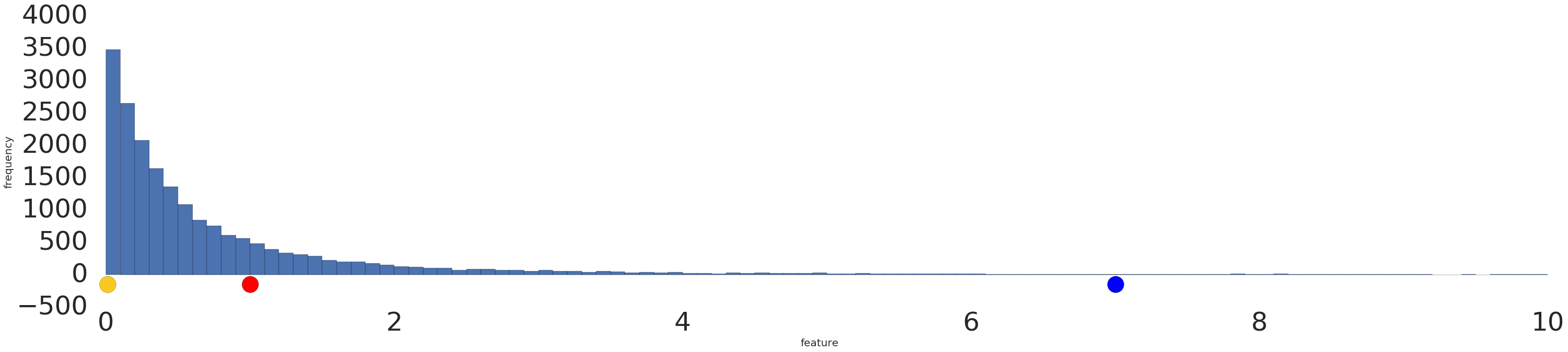
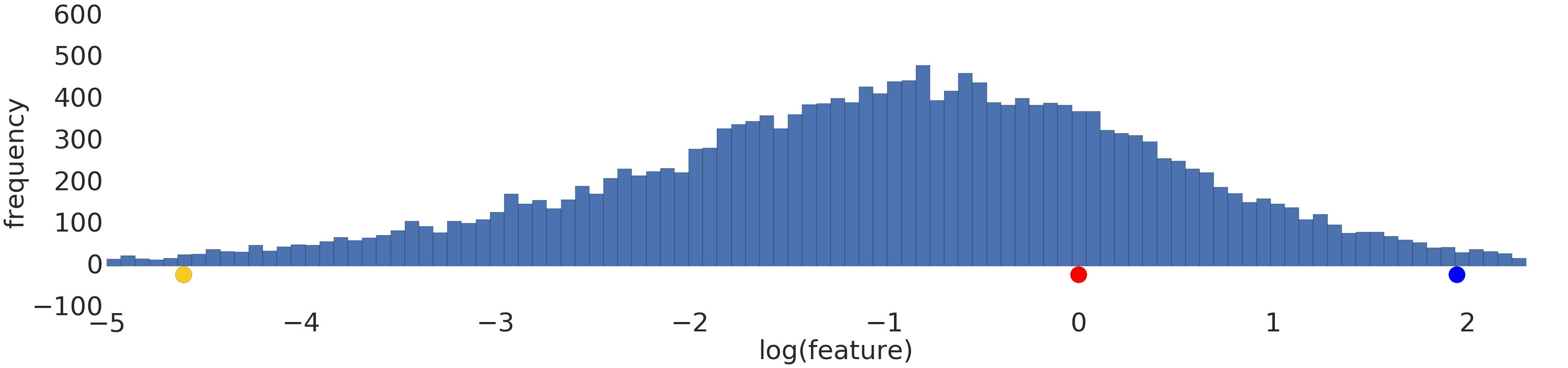
लॉग स्केलिंग (दूसरी इमेज) से पहले, लाल रंग का उदाहरण पीले रंग से मिलता-जुलता दिखता है. लॉग स्केलिंग (तीसरा चित्र) के बाद, लाल रंग नीले रंग से मिलता-जुलता दिखता है.
क्वैनटाइल
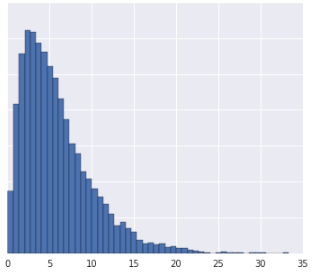
डेटा को क्वार्टाइल में बांटने की सुविधा तब अच्छी तरह से काम करती है, जब डेटासेट किसी ज्ञात डिस्ट्रिब्यूशन के मुताबिक न हो. उदाहरण के लिए, यह डेटासेट देखें:

आम तौर पर, दो उदाहरण तब ज़्यादा मिलते-जुलते होते हैं, जब उनके बीच में सिर्फ़ कुछ उदाहरण आते हैं. भले ही, उनकी वैल्यू अलग-अलग हों. वहीं, अगर उनके बीच में कई उदाहरण आते हैं, तो वे ज़्यादा अलग-अलग होते हैं. ऊपर दिए गए विज़ुअलाइज़ेशन से, लाल और पीले या लाल और नीले रंग के बीच आने वाले उदाहरणों की कुल संख्या देखना मुश्किल है.
डेटासेट को क्वाइनटल या इंटरवल में बांटकर, मिलती-जुलती चीज़ों के बारे में पता लगाया जा सकता है. हर इंटरवल में, उदाहरणों की संख्या बराबर होती है. साथ ही, हर उदाहरण को क्वाइनटल इंडेक्स असाइन किया जाता है. क्वंटाइल बकेट देखकर, इस तरीके के बारे में जानें.
यहां पिछले डिस्ट्रिब्यूशन को क्वार्टाइल में बांटा गया है. इससे पता चलता है कि लाल रंग, पीले रंग से एक क्वार्टाइल और नीले रंग से तीन क्वार्टाइल दूर है:
![क्वार्टाइल में बदलने के बाद का डेटा दिखाने वाला ग्राफ़. लाइन में 20 इंटरवल दिखाए गए हैं.]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=9&hl=hi)
आपके पास \(n\) क्विंटाइल की संख्या चुनने का विकल्प होता है. हालांकि, डेटा को सही तरीके से दिखाने के लिए, आपके डेटासेट में कम से कम\(10n\) उदाहरण होने चाहिए. अगर आपके पास ज़रूरत के मुताबिक डेटा नहीं है, तो डेटा को सामान्य बनाएं.
देखें कि आपको क्या समझ आया
नीचे दिए गए सवालों के लिए, मान लें कि आपके पास क्वार्टाइल बनाने के लिए ज़रूरत के मुताबिक डेटा है.
पहला सवाल
- डेटा डिस्ट्रिब्यूशन, गॉसियन है.
- आपके पास इस बारे में कुछ जानकारी है कि डेटा असल में क्या दिखाता है, जिससे पता चलता है कि डेटा को नॉन-लाइनर तरीके से ट्रांसफ़ॉर्म नहीं किया जाना चाहिए.
दूसरा सवाल
रिपोर्ट में पूरा डेटा नहीं है
अगर आपके डेटासेट में किसी सुविधा के लिए वैल्यू मौजूद नहीं हैं, लेकिन ये उदाहरण कम ही दिखते हैं, तो इन उदाहरणों को हटाया जा सकता है. अगर ऐसे उदाहरण अक्सर दिखते हैं, तो उस सुविधा को पूरी तरह हटाया जा सकता है. इसके अलावा, मशीन लर्निंग मॉडल का इस्तेमाल करके, दूसरे उदाहरणों से छूटी हुई वैल्यू का अनुमान लगाया जा सकता है. उदाहरण के लिए, वह संख्या जो मौजूद नहीं है उसे जोड़ने के लिए, पहले से मौजूद सुविधा के डेटा पर ट्रेन किए गए रिग्रेशन मॉडल का इस्तेमाल किया जा सकता है.